Математика/2. Перспективы систем информатики
К.
ф.-м. н. Панкратов А. С., Брилева Н. Е.
Российский
университет дружбы народов, Россия
Алгоритм построения родословий на
основе оцифрованных архивных данных
С
открытием большинства российских государственных архивов для широкого круга
исследователей, в России всё более популярными становятся генеалогические
исследования. Многие хотят восстановить
историю своей семьи, своего рода. Однако людям, которые хотят больше узнать о
своих предках, приходится прикладывать огромные усилия, для того, чтобы найти
какие-то сведения в различных архивных документах. Это связано с массой
факторов, в частности, с географической удаленностью региональных архивов.
Кроме того, в связи с определенными историческими событиями колоссальное
количество архивных документов оказалось безвозвратно утраченным. Но даже если исследователь-любитель
и получит доступ к документам, в которых имеется информация о его предках
(например, к материалам переписей), он может потратить колоссальный объем времени
на то, чтобы просто прочитать записи в переписях и разобрать почерк того
приказчика или старосты, который проводил перепись. Однако наиболее трудоемким
является процесс идентификации выбранного человека и его сородичей в других,
более ранних (поздних) переписях. Уже давно перед разработчиками и
программистами поставлена задача автоматизации процесса поиска информации о
человеке в архивах. В частности, разработана и успешно функционирует система
поиска сведений о погибших и пропавших без вести в годы Великой Отечественной
войны – на основе данных Центрального архива Министерства Обороны РФ [1].
Однако относительно данных переписей населения Российской Империи задача
автоматизации поиска (в контексте построения родословных связей) не является
тривиальной. Основная сложность здесь связана с необходимостью структуризации информации
для дальнейшей обработки тех данных, которые представлены в архивах.
В настоящем докладе
предлагается один из путей решения этой задачи, основанный на построении базы
данных, содержащей информацию о жителях населенных пунктов, полученную из
архивных материалов переписей. Мы здесь ограничиваемся одним видом архивных
документов: ревизскими сказками 4-й и 5-й ревизий (подушных переписей), проведённых,
соответственно, в 1782 и 1795 гг. [2]. Однако данный подход может быть распространен
и на иные переписные документы, имеющиеся в российских архивах.
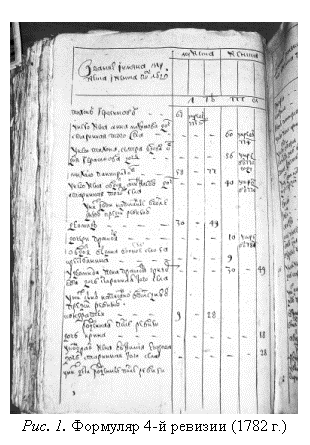 В Российской
Империи всего было проведено 10 ревизий: с 1719 по 1858 г. Формуляр сказки 4-й
ревизии приведен на рис. 1. Данные о жителях здесь организованы в таблицу с 7
колонками. В 1 колонке записывались сами жители (для хозяина двора – имя,
отчество и фамилия (если была), для членов его семьи – только имена с указанием
степени родства), во 2 и 4 колонках записывался возраст жителей-мужчин, соответственно,
на предыдущую и текущую перепись, в 3 колонке фиксировались выбывшие из списка (мужчины)
с момента предыдущей переписи, с указанием года и причины выбытия. 5, 6 и 7
колонки содержали аналогичные сведения для женщин. Как видно, записи в документе
выполнены старинной скорописью, с сокращениями, титлами и надстрочными буквами.
В Российской
Империи всего было проведено 10 ревизий: с 1719 по 1858 г. Формуляр сказки 4-й
ревизии приведен на рис. 1. Данные о жителях здесь организованы в таблицу с 7
колонками. В 1 колонке записывались сами жители (для хозяина двора – имя,
отчество и фамилия (если была), для членов его семьи – только имена с указанием
степени родства), во 2 и 4 колонках записывался возраст жителей-мужчин, соответственно,
на предыдущую и текущую перепись, в 3 колонке фиксировались выбывшие из списка (мужчины)
с момента предыдущей переписи, с указанием года и причины выбытия. 5, 6 и 7
колонки содержали аналогичные сведения для женщин. Как видно, записи в документе
выполнены старинной скорописью, с сокращениями, титлами и надстрочными буквами.
Для организации
автоматического поиска в архивных документах необходимо произвести их
первоначальную оцифровку. Предполагается, что архивные документы оцифровываются
вручную, и табличная структура данных ревизий позволяет использовать в качестве
формата оцифровки электронные таблицы Excel.
При этом производится перевод старинной скорописи на современный русский язык,
однако с максимальным сохранением исходной орфографии и пунктуации. Оцифрованный
Excel-вариант 4-й ревизской сказки представлен в следующей
таблице:
|
Персонажи |
возраст на пред. перепись (муж.) |
выбытие (муж.) |
возраст на эту перепись (муж.) |
возраст на пред. перепись (жен.) |
выбытие (жен.) |
возраст на эту перепись (жен.) |
|
Тихон Герасимов |
67 |
умре в 773 году |
|
|
|
|
|
У него жена Анна
Максимова дочь старинная того села |
|
|
|
60 |
умре в 774 |
|
|
У него Тихона сестра
вдова Овдотья Герасимова дочь |
|
|
|
56 |
умре в 770 году |
|
|
Михайло Паникратов |
58 |
|
77 |
|
|
|
|
У него жена Овдотья
Акинфиева дочь старинная того же села |
|
|
|
44 |
умре в 770 |
|
|
У них дети написанные
в последней пред сей ревизии Деомид |
30 |
|
49 |
|
|
|
|
дочери Прасковья |
|
|
|
10 |
умре в 781 |
|
|
Овдотья выдана в оное
же село за крестьянина |
|
|
|
9 |
|
|
|
У Деомида жена
Прасковья Григорьева дочь старинная того села |
|
|
|
30 |
|
49 |
|
У них сын написанный в
последней пред сей ревизии Кондратей |
9 |
|
28 |
|
|
|
|
рожденная после
ревизии дочь Ирина |
|
|
|
|
|
18 |
|
У Кондратия жена
Евфимия Егорова дочь старинная того села |
|
|
|
|
|
28 |
После такой оцифровки
имена-отчества жителей, их родственные связи, а также некоторые дополнительные
характеристики (такие, как «вдова», «старинная того же села») попадают в одну
графу Excel-таблицы. Это означает, что в контексте задачи поиска
конкретного персонажа и автоматического выявления его родственных связей данные
ревизий являются полуструктурированными [3, 4]. В связи с этим возникает
проблема распознавания в данной Excel-таблице всех
названных характеристик переписанных жителей (персонажей) и размещение их в
реляционные таблицы базы данных.
Как видно, записи в
ревизских сказках обладают рядом специфических особенностей (например,
древнерусские языковые обороты и старинная орфография), а количество используемых
в них языковых конструкций невелико и сводится к стандартному перечню
(например, «у него жена», «у них дети»). В связи с этим, для задачи выделения
характеристик из переписных документов разрабатывается специальный алгоритм,
задача которого – сформировать на основе ревизских записей реляционные таблицы
с характеристиками персонажей. Выделяются следующие характеристики: имя, отчество,
фамилия, пол, возраст (преобразуется в год рождения), родственник, степень
родства, дополнительные характеристики (в связи с возможным многозначным
характером они выносятся в отдельную таблицу). В результате алгоритм формирует
две реляционные таблицы: ПЕРСОНАЖИ и ДОП_ХАРАКТЕРИСТИКИ. В нашем примере они
будут иметь следующий вид:
Таблица ПЕРСОНАЖИ:
|
Номер двора |
Номер персон. |
Имя |
Отчество |
Фамилия |
Пол |
Год рожд. |
Номер родств. |
Степень родства |
|
1 |
1 |
Тихон |
Герасимов |
Null |
муж. |
1696 |
Null |
Null |
|
1 |
2 |
Анна |
Максимова |
Null |
жен. |
1703 |
1 |
жена |
|
1 |
3 |
Овдотья |
Герасимова |
Null |
жен. |
1707 |
1 |
сестра |
|
2 |
4 |
Михайло |
Паникратов |
Null |
муж. |
1705 |
Null |
Null |
|
2 |
5 |
Овдотья |
Акинфиева |
Null |
жен. |
1723 |
4 |
жена |
|
2 |
6 |
Деомид |
Михайлов |
Null |
муж. |
1733 |
4 |
сын |
|
2 |
7 |
Прасковья |
Михайлова |
Null |
жен. |
1753 |
4 |
дочь |
|
2 |
8 |
Овдотья |
Михайлова |
Null |
жен. |
1754 |
4 |
дочь |
|
2 |
9 |
Прасковья |
Григорьева |
Null |
жен. |
1733 |
6 |
жена |
|
2 |
10 |
Кондратей |
Деомидов |
Null |
муж. |
1754 |
6 |
сын |
|
2 |
11 |
Ирина |
Деомидова |
Null |
жен. |
1764 |
6 |
дочь |
|
2 |
12 |
Евфимия |
Егорова |
Null |
жен. |
1754 |
10 |
жена |
Таблица ДОП_ХАРАКТЕРИСТИКИ:
|
Номер персонажа |
Характеристика |
|
1 |
умре в 773 году |
|
2 |
старинная того же села |
|
2 |
умре в 774 |
|
3 |
вдова |
|
3 |
умре в 770 году |
|
5 |
старинная того же села |
|
5 |
умре в 770 |
|
7 |
умре в 781 |
|
8 |
выдана в оное же село за крестьянина |
|
9 |
старинная того же села |
|
12 |
старинная того же села |
Примечание. В
исходном историческом документе могут встретиться записи, которые не относятся
ни к одному из стандартных типов. Их количество, как правило, невелико, и
соответствующие ячейки таблицы специальным образом маркируются для дальнейшего
распознавания «вручную».
По аналогичному
принципу подобные алгоритмы разрабатываются и для ревизий с другими формулярами
сказок. Это позволяет выстроить непрерывную цепочку исторических переписных
ведомостей, переведенную в единый формат базы данных и охватывающую период с
1719 по 1858 годы. Далее строится алгоритм, который, начиная с конкретного
предка, идёт «в глубь времен» и, на основе информации о родственных связях, выстраивает
историю рода, выявляя при этом сородичей прошлых поколений. Возникающая при
этом задача идентификации одного и того же персонажа в нескольких смежных ревизиях
решается путем сопоставления имен, отчеств, возрастов и составов семей. Здесь
приходится учитывать ряд нюансов, например, наличие разных вариантов одного и
того же имени (например, Авдотья – Евдокия), а также возможные неточности при
указании возраста. Данный алгоритм изложен в [5].
Литература:
1. ОБД Мемориал. – http://www.obd-memorial.ru
.
2. All Russia Family Tree. Российская
генеалогия. – http://www.vgd.ru .
3. Гарсиа-Молина Г.,
Ульман Дж., Уидом Дж. Системы баз данных. Полный курс. – М.: Издательский дом
«Вильямс», 2003. – 1088 с.
4. Гринев М. Системы
управления полуструктурированными данными // Открытые системы, 1999 г., № 5-6.
5. Брилева Н. Е.
Генерация родословных линий на базе оцифровки архивных документов переписи
населения / Фестиваль науки в РУДН: Сборник работ студентов-победителей
международных, всероссийских конкурсов, конференций, олимпиад. – М.: РУДН,
2010. – С. 118-124.