Математика / 5. Математическое
моделирование
к.ф.-м.
н. Калжанов М.У.
Костанайский
государственный университет
имени
А.Байтурсынова
Алгоритм укрупнения
градаций признаков
Предположим, что признаку y,
характеризующему объекты совокупности, соответствует разбиение ![]() , классы которого состоят из объектов, имеющих одно значение
этого признака. Назовем укрупнением y
разбиение совокупности
, классы которого состоят из объектов, имеющих одно значение
этого признака. Назовем укрупнением y
разбиение совокупности ![]() , каждый класс которого суть объединения некоторого поднабора
множеств rα.
, каждый класс которого суть объединения некоторого поднабора
множеств rα.
Значения номинальных признаков не упорядочены , поэтому допустимы любые
укрупнения: классы разбиения R могут быть объединениями
практически любого набора множеств rα. Классы ранговых
признаков упорядочены, поэтому допустимыми укрупнениями таких признаков будем
считать разбиения, классы которых представимы в виде 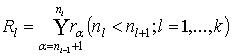 . При укрупнении количественных признаков мы будем
рассматривать их как ранговые, учитывая лишь порядок их значений; в конечном
итоге разбиение R даст нам интервалы
значений.
. При укрупнении количественных признаков мы будем
рассматривать их как ранговые, учитывая лишь порядок их значений; в конечном
итоге разбиение R даст нам интервалы
значений.
В
зависимости от цели исследования качество укрупнения можно оценивать, используя
подходящую вещественную целевую функцию Q(R),
определенную на множестве допустимых разбиений совокупности объектов; при
укрупнении стоит задача максимизации этой функции.
Обозначим ![]() , разбиение, полученное из R перемещением
подмножества объектов rα в класс R1. Обычно относительно
быстро (по сравнению с
, разбиение, полученное из R перемещением
подмножества объектов rα в класс R1. Обычно относительно
быстро (по сравнению с ![]() ) вычисляется величина приращения Q при таком
изменении R:
) вычисляется величина приращения Q при таком
изменении R: ![]() , этот факт используется в реализованных алгоритмах.
, этот факт используется в реализованных алгоритмах.
Итерация алгоритма укрепления номинального признака состоит в том, что
поочередно рассматриваются классы исходного разбиения rα (α = 1, …, n). При рассмотрении rα отыскивается l, для которого величина ![]() максимальна, и при
переходе к rα+1 вместо R берется
максимальна, и при
переходе к rα+1 вместо R берется
![]() . Итерации повторяются до тех пор, пока есть положительные
приращения
. Итерации повторяются до тех пор, пока есть положительные
приращения ![]() , после чего улучшенное таким образом R
принимается за искомое оптимальное укрупнение.
, после чего улучшенное таким образом R
принимается за искомое оптимальное укрупнение.
Рассмотрим алгоритм укрупнения ранговых признаков. Пусть ![]() . Обозначим R(β) разбиение,
полученное из Rβ заменой двух классов Rl
и Rl+1 на
. Обозначим R(β) разбиение,
полученное из Rβ заменой двух классов Rl
и Rl+1 на 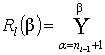 и
и 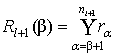 , полагая
, полагая ![]() Ø. В итерации алгоритма поочередно рассматриваются
пары классов Rl и Rl+1 (l = 1, …, k).
При рассмотрении Rl и Rl+1 отыскивается β, для которого величина Q(R(β))
максимальна (оптимальное β) и при переходе к следующей паре классов
разбиение R заменяется на R(β). Итерации
повторяются до тех пор, пока величина Q(R)
увеличивается.
Ø. В итерации алгоритма поочередно рассматриваются
пары классов Rl и Rl+1 (l = 1, …, k).
При рассмотрении Rl и Rl+1 отыскивается β, для которого величина Q(R(β))
максимальна (оптимальное β) и при переходе к следующей паре классов
разбиение R заменяется на R(β). Итерации
повторяются до тех пор, пока величина Q(R)
увеличивается.
Рассмотрим, каким образом
отыскивается оптимальное β. Прежде всего заметим, что безразлично, что
максимизировать: Q(R(β)) или P(β)
= Q(R(β)) - Q(R(nl-1)). Для Р выполняется рекуррентное
соотношение P(β) = P(β-1) + ![]() , с использованием которого последовательно вычисляются P(β)
для β = пl-1 + 1, …, nl+1, в том числе и Р(пl).
Величина приращения Q при замене R
на R(β) выражается следующим образом: Q(R(β))
- Q(R) = P(β)
- Р(пl).
, с использованием которого последовательно вычисляются P(β)
для β = пl-1 + 1, …, nl+1, в том числе и Р(пl).
Величина приращения Q при замене R
на R(β) выражается следующим образом: Q(R(β))
- Q(R) = P(β)
- Р(пl).
Таким образом, отыскивая оптимальное
β, мы одновременно получаем величину приращения при ![]() , мы узнаем, насколько
увеличилась Q(R) в результате итерации.
, мы узнаем, насколько
увеличилась Q(R) в результате итерации.
Пусть ![]() - важные с точки
зрения исследователя признаки. Знание значений признака у позволяет в
той или иной мере предсказывать значения признаков системы Х. Укрупнение
градаций признака у вызывает некоторое уменьшение точности такого
прогноза, поэтому целью укрупнения является минимальная потеря информативности.
- важные с точки
зрения исследователя признаки. Знание значений признака у позволяет в
той или иной мере предсказывать значения признаков системы Х. Укрупнение
градаций признака у вызывает некоторое уменьшение точности такого
прогноза, поэтому целью укрупнения является минимальная потеря информативности.
Для измерения степени информативности
разбиения R по отношению к признаку х используется коэффициент Валлиса:
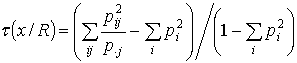 ,
,
где ![]() -
доля объектов, имеющих i значение признака х и
содержащихся в j-м классе R,
-
доля объектов, имеющих i значение признака х и
содержащихся в j-м классе R, ![]() и
и ![]()
В нашем случае необходима максимизация ![]() сразу для всех признаков
сразу для всех признаков
![]() . Одним из способов построения целевой функции в такой
многоцелевой задаче является суммирование целевых функций:
. Одним из способов построения целевой функции в такой
многоцелевой задаче является суммирование целевых функций:
![]() .
.
Пусть группа объектов rα, содержащая в классе j, переносится в класс l,
тогда величина приращения ![]() выражается следующим образом:
выражается следующим образом:
![]()
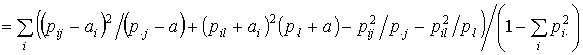 ,
,
где ![]() - доля объектов, имеющих
i-е значение признака х и содержащихся в rα,
- доля объектов, имеющих
i-е значение признака х и содержащихся в rα, ![]() - доля объектов rα в совокупности. Эта
величина вычисляется
- доля объектов rα в совокупности. Эта
величина вычисляется
быстрее, чем ![]() , поскольку
суммирование в правой части выражения производится только по одному индексу i,
следовательно, использование приращения
, поскольку
суммирование в правой части выражения производится только по одному индексу i,
следовательно, использование приращения ![]() оправдано.
оправдано.
Литература :
1.
Методы
принятия технических решений : Пер. с нем.- Мушик Э., Мюллер П., М.: Мир, 1990.
– 208 С.
2.
Сборник
задач по теории надежности .Половко А.М., Маликов И.М., Жигарев А.Н., Зарудный
В.И. – М. : Советское радио , 1972 .- 408 С.