Современные
информационные технологии/Вычислительная техника и программирование
Мясіщев О.А., Юрчук І.В.
Хмельницький національний університет, Україна
Про практичне досягнення найбільшої
продуктивності для обчислювальних
систем на базі багатоядерних процесорів
При рішенні, наприклад завдань теорії
пружності, пластичності широко використовується метод кінцевих елементів.
Практичне вирішення завдань цим методом зводиться до вирішення систем лінійних
рівнянь. Побудова цих систем рівнянь зводиться до побудови так званої матриці
жорсткості, що вимагає виконання операцій перемножування матриць. Отже,
використання найбільш швидких алгоритмів розрахунку для матричних добутків
дозволяє найефективніше використовувати існуючу обчислювальну систему. У цій
роботі розглядається
можливість підвищення продуктивності стандартної обчислювальної системи до 9
разів при вирішенні завдань перемножування квадратних матриць шляхом переходу
від стандартних класичних послідовних алгоритмів до використання алгоритмів
блокового представлення матриць.
Завдання матричного множення вимагає
для свого вирішення виконання великої кількості операцій.
Нехай A,B,C – квадратні матриці розміром n x n. Матриця C=A*B. Тоді компоненти матриці C розраховуються по формулі:
![]()
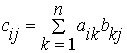
Тут i,j=1,...,n..
Для обчислення одного елементу матриці C необхідно виконати n множень і n-1
складань. Отже, спільна кількість операцій з плаваючою крапкою для всіх
елементів матриці визначиться
![]()
![]()
Оцінку продуктивності
комп'ютера проводитимемо в Мегафлопсах (1 Mflops - мільйон операцій з плаваючою крапкою
за одну секунду). Розділивши число операцій на
час, помножений на 1000000, отримаємо продуктивність системи в
Мегафлопсах. Для перемножування квадратних матриць отримаємо
![]()
![]() (Mflops)
(Mflops)
Найбільшу продуктивність спробуємо досягти на обчислювальній системі,
побудованій на базі одного чотирьох ядерного процесора CORE 2 QUAD PENTIUM Q6600 2.4GHZ з
оперативною пам'яттю 4Гбайт. В якості операційної
системи
використовуватимемо 32-х і 64-х розрядні Linux Ubuntu ver. 9.04 desktop,
компілятори фортран – F77 і gfortran
ver. 4.3.3, які входять до складу цих дистрибутивів.
Оскільки обчислювальна система базується на
чотирьох ядерному процесорі, то програми повинні передбачати процедури
розпаралелювання обчислювального процесу. Для цієї мети використовуватимемо
бібліотеки
MPI [1].
Розглянемо перший підхід. У роботі
[2] представлений фрагмент програми по множенню матриць:
do
j=1,n
do k=1,n
do i=1,n
с(i,j)=c(i,j)+a(i,k)*b(к,j)
end do
end do
end do
Показано,
що при використанні циклу jki
досягається максимальна продуктивність роботи програми для компілятора ФОРТРАН,
який розміщує елементи матриці в пам'яті по стовпцях тобто
![]()
Це
викликано тим, що розміщувані в кеш-пам'яті елементи матриць A,B,C ефективно використовуються, коли
доступ до них або їх модифікація в
алгоритмі множення матриць проводиться послідовно з переходом до сусіднього
елементу пам'яті. Також при послідовній вибірці збільшується ефективність
використання кеш-пам'яті.
Проте даний алгоритм все ж недостатньо
ефективно використовує кеш-пам'ять першого рівня [2]. Відомо, що її розмір для
використовуваного нами процесора не перевищує 32Кбайт для зберігання даних на
одне ядро. Для ефективного її використання доцільно, щоб вся матриця могла бути там розміщена під час проведення операцій
множення. З цією метою розглянемо блокове представлення
матриць. Представимо матриці A,B,C
(глобальні матриці) у вигляді блоків, розміром
(n/N) x(n/N), N - кількість блоків по рядках або стовпцях.
![]()
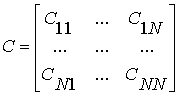 =AB=
=AB=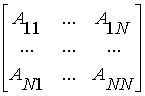
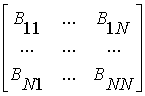
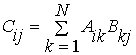
Тут
![]() - блокові матриці.
- блокові матриці.
Нижче представлений фрагмент програми, що
реалізовує блокове множення матриць [2].
do j=1,nn
do k=1,nn
do i=1,nn
do
j1=1,m
do
k1=1,m
do
i1=1,m
c(i1,j1,i,j)=c(i1,j1,i,j)+a(i1,k1,i,k)*b(k1,j1,k,j)
end do
end do
end do
end do
end do
end do
Тут nn=N, m=n/N. Перші
два
індекси (i1,j1) масивів – рядки
і
стовпці
конкретної
блокової
матриці, останні
два
індекси (i,j) – координати
блокової
матриці
в
глобальній
матриці.
Нижче представлена
робоча програма, що реалізовує блоковий підхід обчислення добутку.
program
cpu4_par
include 'mpif.h'
C n-число
рядків і стовпців матриць A,B,C
C m-число
рядків і стовпців в блоці матриць
C nn-число
рядків і стовпців матриць A,B,C, які складаються
з блоків
parameter
(n=5120,m=20,nn=n/m)
integer ierr,rank,size,i,j,k
double precision а,
b(m,m,nn,nn), с(m,m,nn,nn)
double precision
mf,op
double precision time1, time, time2
integer status(MPI_STATUS_SIZE)
call MPI_INIT(ierr)
C
size – число ядер
call MPI_COMM_SIZE(MPI_COMM_WORLD, size, ierr)
C
rank – номер ядра
call MPI_COMM_RANK(MPI_COMM_WORLD, rank, ierr)
do 10 i=1,nn
do 10 j=1,nn
do 10 i1=1,m
do 10 j1=1,m
а(i1,j1,i,j) =1.0d0*(i1+m*(i-1))*(j1+m*(j-1))
b(i1,j1,i,j) =1.0d0/a(i1,j1,i,j)
с(i1,j1,i,j)=0.d0
10 continue
time1
= MPI_Wtime()
с Цикл по процесорах rank
do
j=rank+1,rank+1+(nn-size),size
do k=1,nn
do i=1,nn
do j1=1,m
do k1=1,m
do i1=1,m
с(i1,j1,i,j)=c(i1,j1,i,j)+a(i1,k1,i,k)*b(k1,j1,k,j)
end do
end do
end do
end do
end do
end do
time2 = MPI_Wtime()
time=time2-time1
if(rank.eq.0) then
op=(2.0*n-1)*n*n
mf=op/(time*1000000.0)
print *', time = ',time, 'mf=',mf
end if
с Друк
елементу матриці C
call
prinmatr(1000,250,m,nn,c)
call MPI_FINALIZE(ierr)
end
с Підпрограма для
друку
елементу
глобальної
матриці
subroutine prinmatr(ig,jg,m,nn,c)
double precision з(m,m,nn,nn)
il=ig-m*((ig-1)/m)
jl=jg-m*((jg-1)/m)
mg=((ig-1)/m)+1
ng=((jg-1)/m)+1
print 7,ig,jg,c(il,jl,mg,ng)
7
format(1x,'i=',i5', j=',i5', C=',f18.10)
end
Компіляція
для F77 і запуск програми проводилися командами:
F77 –O3 –I/usr/local/mpi/include –f
–o cpu4_par cpu4_par.f
/usr/local/mpi/lib/libmpich.a
/usr/local/mpi/bin/mpirun –np 4
–machinefile machines cpu4_par
Для gfortran:
gfortran –O3 –I/usr/lib/lam/include
–o cpu4_par cpu4_par –lmpi
mpirun –np 4 cpu4_par
Програма
запускалася
з
ключем -np 4 (для
паралельної
роботи
з 4-а
ядрами) і -np 1 (при
роботі
на 1-му ядрі)
Нижче представлені наступні випадки розрахунку:
1.
Числа подвійної точності. 64-х розрядна версія Linux Ubuntu ver. 9.04 desktop.
Використовуються компілятори F77 і gfortran. При запуску на одному ядрі
приймається, що розміри глобальної і блокової
матриць збігаються, а при запуску на 4-х ядрах (паралельна робота) глобальна
матриця розбивається на 16 блоків з метою коректної роботи представленої
програми. Якщо глобальна матриця має розмірність 4000х4000 елементів, то розмір блоку буде рівний 1000х1000
елементів. Результати експерименту
показані в таблиці 1. У ній представлені час розрахунку в секундах (чисельник),
продуктивність в Мегафлопсах (знаменник), прискорення розрахунку для 4-х ядерного
варіанту.
Таблиця 1.
|
Розмір матриці |
Gfortran |
F77 |
||||
|
Одне ядро |
Чотири ядра |
Приско-рення |
Одне ядро |
Чотири ядра |
Приско-рення |
|
|
500х500 |
0.09/2653 |
0.03/8112 |
3.06 |
0.12/2126 |
0.03/8111 |
3.82 |
|
1000х1000 |
1.42/1405 |
0.20/9841 |
7.00 |
1.57/1272 |
0.25/8071 |
6.35 |
|
2000х2000 |
11.81/1355 |
2.48/6442 |
4.75 |
13.00/1231 |
2.91/5499 |
4.47 |
|
4000х4000 |
101.9/1256 |
73.7/1738 |
1.38 |
106.9/1198 |
76.0/1684 |
1.41 |
|
6000х6000 |
341.0/1267 |
250.5/1725 |
1.36 |
357.9/1206 |
257/1680 |
1.39 |
Теоретичне прискорення 4-х ядерного варіанту розрахунку
повинно бути біля 4-х одиниць. Проте для розміру матриць 500х500 воно близьке
до теоретичного, а для розмірів понад 4000х4000 воно значно менше теоретичного
і настільки, що немає сенсу застосовувати процедуру
розпаралелювання програм. Проте, наприклад, для розміру 1000х1000 прискорення
вище теоретичного, що пояснюється блоковим представленням матриці. Отже, для
підвищення ефективності при паралельних розрахунках необхідно зменшувати розмір
блоку матриці. З таблиці також видно, що програма, скомпільована на gfortran для 64-х розрядної системи, працює
швидше, ніж в разі компіляції на F77.
2.
Тут розглядаються
ті ж
умови розрахунку, що і в першому випадку, але за винятком того, що розмір
блокових матриць вибирається з умови досягнення найбільшої продуктивності
розрахунків, як для послідовного одноядерного варіанту, так і для паралельного
багатоядерного. Результати експерименту представлені в таблиці 2.
Таблиця
2.
|
Розмір матриці |
Gfortran |
F77 |
||||
|
Одне ядро |
Чотири ядра |
Приско-рення |
Одне ядро |
Чотири ядра |
Приско-рення |
|
|
1000х1000 |
- |
- |
- |
0.94/2129 |
0.23/8704 |
4.09 |
|
1280х1280 |
1.14/3694 |
0.29/14425 |
3.90 |
- |
- |
- |
|
2000х2000 |
4.41/3630 |
1.15/13952 |
3.84 |
7.53/2126 |
1.56/10231 |
4.81 |
|
2560х2560 |
9.27/3618 |
2.34/14359 |
3.97 |
- |
- |
- |
|
4000х4000 |
35.4/3620 |
9.47/13509 |
3.73 |
60.5/2114 |
15.0/8548 |
4.04 |
|
5120х5120 |
74.4/3607 |
20.2/13317 |
3.69 |
- |
- |
- |
|
6000х6000 |
120.4/3588 |
34.3/12580 |
3.51 |
205/2102 |
50.8/8500 |
4.04 |
Розмір блокових матриць, для яких виходила
найбільша продуктивність для компілятора gfortran, приблизно рівний 20х20, для
F77 – 200х200 елементів. З таблиці 2 видно, що gfortran приблизно в 1.5 разу для
64-х розрядних систем ефективніший, ніж F77. Прискорення розрахунку
при паралельному обчисленні для 4-х ядерного процесора приблизно відповідає
теоретично досяжному, тобто – чотирьом.
Це свідчить про те, що кеш-пам'ять використовується ефективно. Для матриць
великого розміру (> 4000х4000) продуктивність зросла більш ніж в 7 разів. Із
збільшенням розміру матриці продуктивність слабо зменшується.
3.
Тут розглядаються
ті ж умови, що і в 2-му випадку, проте розрахунки проводяться для чисел
одинарної точності і для 4-х ядер. Результати представлені в таблиці 3.
Таблиця
3.
|
Розмір матриці |
gfortran |
F77 |
|
Чотири ядра |
Чотири ядра |
|
|
1280х1280 |
0.14/30534 |
- |
|
2000х2000 |
0.51/31160 |
0.79/20150 |
|
4000х4000 |
4.34/29465 |
6.36/20138 |
|
6400х6400 |
17.8/29488 |
32.5/16131 |
|
8000х8000 |
35.9/28551 |
63.4/16139 |
З таблиці 3 видно, що для чисел одинарної
точності продуктивність в порівнянні з числами подвійної точності подвоюється.
Для великих матриць
(> 6000х6000) компілятор gfortran майже в
два рази ефективніший ніж F77 для 64-х розрядних систем.
4.
Числа подвійної точності. 32-х розрядна версія Linux Ubuntu ver. 9.04 desktop.
Використовуються компілятори F77 і gfortran. Розмір блокових матриць
вибирається з умови досягнення найбільшої продуктивності розрахунків, як для
послідовного одноядерного варіанту, так і для паралельного багатоядерного.
Результати експерименту представлені в таблиці 4.
Таблиця
4.
|
Розмір матриці |
Gfortran |
F77 |
||||
|
Одне ядро |
Чотири
ядра |
Приско-рення |
Одне ядро |
Чотири
ядра |
Приско-рення |
|
|
1000х1000 |
1.17/1705 |
0.24/8460 |
4.96 |
1.06/1878 |
0.24/8486 |
4.52 |
|
2000х2000 |
9.39/1704 |
1.89/8474 |
4.97 |
8.23/1939 |
1.76/9088 |
4.67 |
|
4000х4000 |
75.2/1702 |
18.9/6772 |
3.98 |
66.2/1932 |
16.7/7672 |
3.97 |
З таблиці 4 видно, що для 32-х розрядних систем
компілятор F77 працює дещо швидше gfortran.
Зіставлення таблиць 2 і 4 показує, що для 64-х розрядних систем компілятор
gfortran приблизно в 1.5-1.8 разу
показує вищу продуктивність, ніж для 32-х. Компілятор
F77 для 64-х розрядних систем не дає істотного виграшу в продуктивності в
порівнянні з 32-х розрядними.
5.Умови
розрахунку, як
і для 4-го випадку, але розглядаються числа одинарної
точності. Розрахунки проводяться для 4-х ядер в паралельному режимі. Результати
представлені в таблиці 5.
Таблиця
5.
|
Розмір матриці |
gfortran |
F77 |
|
Чотири ядра |
Чотири ядра |
|
|
1000х1000 |
0.24/8274 |
0.22/9087 |
|
2000х2000 |
1.86/8584 |
1.62/9848 |
|
4000х4000 |
14.4/8864 |
12.7/10082 |
|
6400х6400 |
75.3/6962 |
66.5/7887 |
З таблиці 5,
як і для попереднього випадку, видно, що для 32-х розрядних систем компілятор
F77 працює дещо швидше gfortran. Зіставлення таблиць 4 і 5 показує, що для
чисел подвійної і одинарної точності для 32-х розрядних систем різниця в
швидкості розрахунків не істотна.
Висновки.
1.Істотне
збільшення продуктивності при матричних обчисленнях для багатоядерних систем
можливо завдяки блоковому представленню початкових глобальних матриць. В цьому
випадку вдається
досягти теоретичного прискорення при розпаралелюванні по ядрах процесора.
2.Використання
64-х розрядних систем дозволяє в 1.5-1.8 разу підняти продуктивність
розрахунків в порівнянні з 32-х розрядними.
3.Для
64-х розрядних систем значно ефективніше використовувати компілятор gfortran,
який в порівнянні з F77 дає приріст продуктивності в 1.5-1.8 разу. Для 32-х
розрядних систем компілятор F77 працює трохи швидше gfortran.
4.Матричні
обчислення одинарної точності в 64-х розрядних системах виконуються в 2.0-2.2 рази
швидше, ніж подвійної точності. Для 32-х розрядних систем істотного
збільшення швидкодії не спостерігається.
5.Результати
обчислювального експерименту показали, що перехід до блокового представлення
матриць, до 64-х розрядного програмного
забезпечення,
до компілятора gfortran дозволило підвищити швидкість розрахунків для чисел
одинарної і подвійної точності приблизно в 8-9 разів.
Література.
1.Гергель
В.П. Теория и практика параллельных вычислений. http://www.intuit.ru/department/calculate/paralltp/ - 2007
2.Высокопроизводительные
вычисления на кластерах: Учебное пособие/ Под ред. А.В.Старченко.- Томск:
Изд-во Том. Ун-та, 2008 – 198 с.