Современные
информационные технологии/2.Вычислительная техника и программирование
Корнийко
М.В.
Национальный
горный университет, Украина
Разработка программы распознавания текстовой информации
средствами нейросетевых технологий
Актуальностью
является использование нейросетевых методов распознавания текста – наиболее
успешной реализации нейронных сетей. Перспектива их использования довольно яркая, в свете решения
нетрадиционных проблем и является ключом к целой технологии.
Цель
работы — исследование нейросетевых методов и выбор оптимального метода для
распознавания текста.
Предполагается
алгоритм:
1) Создание эталонных
табличных изображений всех символов;
2) Преобразование
двумерного массива в одномерный вектор-столбец;
3) Создание зашумленных
копий всех строк для разного уровня шума;
4) Создание сети и ее обучение
на части полученной выборки;
5) Проверка качества
обучения на тестовой выборке для каждого уровня шума.
Для
сравнения результатов распознавания
текста использованы следующие нейросетевые методы:
1) Сеть Элмана
с обратным распространением;
2) Сеть с
прямым распространением сигнала и обратным распространением ошибки;
3) Сеть для классификации
входных векторов;
4) Персептрон;
5) Вероятностная
сеть;
6) Радиальная
базисная сеть с нулевой ошибкой.
На вход системы распознавания поступает растровое изображение
страницы. Для работы алгоритмов распознавания желательно, чтобы поступающее на
вход изображение имело качество. Поэтому перед применением алгоритмов
распознавания проводится его предварительная обработка, направленная на
улучшение качества изображения [1].
Работа
простого классификатора осуществляется в два шага (рис.1). Сначала по исходному
изображению вычисляются признаки. Значение каждого признака является функцией
от яркостей некоторого подмножества пикселей изображения. В результате
получается вектор значений признаков, который поступает на вход нейронной сети.
Каждый выход сети соответствует одной из букв алфавита, а получаемое на выходе
значение рассматривается как уровень принадлежности буквы нечёткому множеству [2].
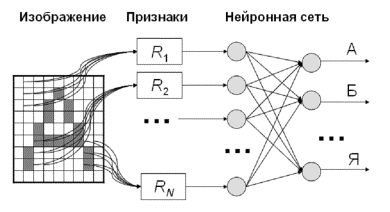
Рисунок 1. Простой классификатор.
Задачей алгоритма комбинирования является обобщение информации, поступающей в
виде входных нечётких множеств и вычисление на их основе выходного нечёткого
подмножества множества распознавания символов.
Результатом
работы классификатора является нечёткое множество, полученное в результате
комбинирования на самом верхнем уровне.
На
последнем этапе принимается решение о наиболее правдоподобном варианте
прочтения слова. Для этого используются уровни возможности прочтения отдельных
букв, межбуквенной сегментации и частоты сочетаний букв.
Применение таких методов даёт возможность выполнить процедуры
обучения нейронной сети на примере печатных символов, выполнив распознавание
символов, и на основе полученных данных выбрать оптимальный
метод.
Литература:
1.
Квасников В.П., Дзюбаненко А.В. Улучшение визуального качества цифрового
изображения путем поэлементного преобразования // Авиационно-космическая
техника и технология 2009 г., 8, стр. 200-204.
2. Арлазаров В.Л.,
Куратов П.А., Славин О.А. Распознавание строк печатных текстов // Сб. трудов
ИСА РАН «Методы и средства работы с документами». — М.: Эдиториал УРСС, 2000. —
С. 31-51.