Экономическин науки/ 8. Математические методы в экономике
К.э.н. Андриенко В.М., магистр
Самисько М. Г.
Одесский национальный
политехнический університет
Статистические методы анализа экономических показателей
Методы многомерного статистического анализа сегодня называют интеллектуальным инструментом исследователя. Они активно используются в аналитической практике в странах с передовой экономикой. Интерес к многомерному статистическому анализу объясняется, прежде всего, его широкими возможностями в отображении и моделировании реальных явлений и процессов. Кроме того, все новейшие разработки, посвященные проблемам приложения нечетких множеств, моделирования катастроф, распознавания образов, сценарного прогнозирования и т.д., предполагают многомерное представление наблюдаемых объектов. Процесс совершенствования системы экономического управления неизбежно приводит к постоянному расширению области применения экономико-математических и статистических методов анализа данных.
В последнее время все более
широкое распространение находит один из разделов многомерного статистического
анализа – факторный анализ. Современные статистики под факторным анализом понимают
совокупность методов, которые на основе реально существующей связи между
признаками позволяет выявить латентные (скрытые) обобщающие и независимые
характеристики развития изучаемых
явлений и процессов.
Для проведения факторного анализа информация
должна быть представлена в виде матрицы
размером m x n:
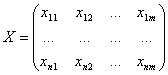
Строки матрицы соответствуют
объектам наблюдений (i=![]() ), а столбцы – признакам (j=
), а столбцы – признакам (j=![]() ). Признаки,
характеризующие объект имеют разную размерность. Для того, чтобы их привести к
одной размерности и обеспечить сопоставимость признаков матрицу исходных данных
обычно нормируют, вводя единый масштаб. Самым распространенным способом
нормировки является стандартизация: от
переменных
). Признаки,
характеризующие объект имеют разную размерность. Для того, чтобы их привести к
одной размерности и обеспечить сопоставимость признаков матрицу исходных данных
обычно нормируют, вводя единый масштаб. Самым распространенным способом
нормировки является стандартизация: от
переменных ![]() переходят к переменным
переходят к переменным
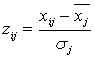 ,
,
где ![]() - среднее
значение j признака,
- среднее
значение j признака, ![]() - среднеквадратическое отклонение.
- среднеквадратическое отклонение.
Основная модель факторного анализа имеет вид:
![]() ,
,
j
=![]() , zj
– j-й признак (величина случайная); F1, F2, …, Fp –
общие факторы (величины случайные, нормально распределенные); uj – характерный фактор;
, zj
– j-й признак (величина случайная); F1, F2, …, Fp –
общие факторы (величины случайные, нормально распределенные); uj – характерный фактор;
aj1, aj2, …, ajp – факторные
нагрузки, характеризующие существенность влияния каждого фактора; dj – нагрузка характерного
фактора. Общие факторы имеют
существенное значение для анализа всех признаков. Характерные факторы показывают, что он относится только к
данному ![]() -му признаку, это специфика
признака, которая не может быть выражена через факторы
-му признаку, это специфика
признака, которая не может быть выражена через факторы ![]() . Основная задача факторного
анализа – определить факторные нагрузки. Дисперсию Sj2
каждого признака, можно разделить на 2 составляющие: первая часть обуславливает действие общих факторов – общность hj2; вторая часть обуславливает действие характерного фактора – характерность
- dj2 . Все переменные представлены в
стандартизованном виде, поэтому дисперсия
. Основная задача факторного
анализа – определить факторные нагрузки. Дисперсию Sj2
каждого признака, можно разделить на 2 составляющие: первая часть обуславливает действие общих факторов – общность hj2; вторая часть обуславливает действие характерного фактора – характерность
- dj2 . Все переменные представлены в
стандартизованном виде, поэтому дисперсия ![]() -го признака Sj2 = 1. Если общие и характерные факторы не коррелируют между собой, то
дисперсию j-го признака можно представить в виде:
-го признака Sj2 = 1. Если общие и характерные факторы не коррелируют между собой, то
дисперсию j-го признака можно представить в виде:
![]()
где
![]() - доля дисперсии признака
- доля дисперсии признака
![]() ,
приходящаяся на k-ый фактор.
,
приходящаяся на k-ый фактор.
Полный вклад
какого-либо фактора в суммарную дисперсию равен
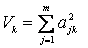 ,
,
вклад
всех общих факторов в суммарную дисперсию
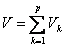 ,
, 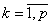 ;
;
Из числа методов,
позволяющих обобщать значения элементарных признаков, алгоритмически простым
является метод главных компонент [2]. Метод главных компонент состоит в
построении факторов - главных компонент, каждый из которых представляет линейную
комбинацию исходных признаков. Первая главная компонента F1 определяет такое направление в пространстве исходных
признаков, по которому совокупность объектов (точек) имеет наибольший разброс
(дисперсию). Вторая главная компонента F2
строится с таким расчетом, чтобы ее направление было ортогонально направлению F1 и она объясняла как можно
большую часть остаточной дисперсии, и т.д. вплоть до p-й главной компоненты Fp. Так как
выделение главных компонент происходит в убывающем порядке с точки зрения доли
объясняемой ими дисперсии, то признаки, входящие в первую главную компоненту с
большими коэффициентами ![]() оказывают максимальное влияние на
дифференциацию изучаемых объектов. Однако, вычислительные
процедуры метода главных компонент достаточно
трудоемки, поэтому расчеты следует
проводить на ПЭВМ. В настоящее время существует несколько десятков
наиболее известных статистических пакетов, разработанных ведущими компаниями
мира [1]. Эти пакеты широко применяются
в органах государственной статистики, органах управления, производственных и
научно-исследовательских организациях различных стран для сбора, обработки и
анализа больших объемов данных. Пакеты являются коммерческими, что служит
препятствием их использования на практике.
оказывают максимальное влияние на
дифференциацию изучаемых объектов. Однако, вычислительные
процедуры метода главных компонент достаточно
трудоемки, поэтому расчеты следует
проводить на ПЭВМ. В настоящее время существует несколько десятков
наиболее известных статистических пакетов, разработанных ведущими компаниями
мира [1]. Эти пакеты широко применяются
в органах государственной статистики, органах управления, производственных и
научно-исследовательских организациях различных стран для сбора, обработки и
анализа больших объемов данных. Пакеты являются коммерческими, что служит
препятствием их использования на практике.
Рассмотрим один из возможных подходов
реализации на компьютере метода главных компонент. Исходные данные для анализа
экономических показателей, целесообразно импортировать из внешней базы данных, например, «1С.Предприятие». Пакет Microsoft-Excel допускает использование файлов
внешней базы данных. Для работы с файлом внешней базы, используется приложение
Microsoft Query, которое включено в Excel. При этом можно использовать
бесплатно распространяемую версию OpenOffic.org.Calc. Стандартизация исходной матрицы, производится
с использованием встроенных функций СРЗНАЧ, СТАНДОТКЛОН. Реализация
непосредственно метода главных компонент можно осуществить с помощью программы Chemometrics , которая является
свободно распространяемой надстройкой Excel. Надстройка Chemometrics содержит несколько функций, которыми можно
пользоваться как обычными функциями рабочего листа Excel. Для этого надо активизировать «Мастер функций» (Insert/Function)
и выбрать категорию «Определенные пользователем». При этом в списке имен
функций будут представлены различные функции. Результатами работы этих
функций являются массивы, поэтому они должны быть введены как формулы массива, то
есть с применением комбинации клавиш Ctrl+Shift+Enter.
Стандартизованная матрица передается в соответствующую программу. Результатом
является матрица факторных нагрузок.
Этот подход был применен для анализа
себестоимости на предприятии «Укрполимер», г. Борисполь. Предприятие производит
напорные трубы из полиэтилена. Взяты следующие технико-экономические параметры:
х1 – средний наружный диаметр трубы;
х2 – толщина стенки труб;
х3 – масса одного метра трубы;
х4 – предельное отклонение наружного диаметра трубы;
х5 – овальность трубы;
х6 – объем выпуска.
В результате выделены три
главные компоненты:
![]() - обобщенный фактор
технических характеристик изделия, доля дисперсии этого фактора – 72,01%;
- обобщенный фактор
технических характеристик изделия, доля дисперсии этого фактора – 72,01%;
![]() - обобщенный производственный фактор, его доля в дисперсии –
14,89%;
- обобщенный производственный фактор, его доля в дисперсии –
14,89%;
![]() -обобщенный фактор
эксплуатационных характеристик, доля в
дисперсии - 8,6%. Таким образом,
суммарный вклад общих факторов в
дисперсии составляет – 95,5%.
Зависимость между показателем себестоимости Y и обобщенными факторами имеет вид:
-обобщенный фактор
эксплуатационных характеристик, доля в
дисперсии - 8,6%. Таким образом,
суммарный вклад общих факторов в
дисперсии составляет – 95,5%.
Зависимость между показателем себестоимости Y и обобщенными факторами имеет вид:
![]() .
.
Совокупный коэффициент
корреляции ![]() , статистика для оценки по критерию Фишера F = 17,93. Для
, статистика для оценки по критерию Фишера F = 17,93. Для ![]() =0,05,
=0,05, ![]() , значение критерия
, значение критерия ![]() = 5,80. Следовательно, на уровне значимости
= 5,80. Следовательно, на уровне значимости ![]() =0,05 можно утверждать, что аппроксимация данным уравнением
достаточно хорошая.
=0,05 можно утверждать, что аппроксимация данным уравнением
достаточно хорошая.
До
недавнего времени формирование ценовой политики предприятия было пассивным,
существовал огромный разрыв между нужной величиной продаж и величиной средних
затрат. У предприятия существовали проблемы, ограничивающие сбыт и не
способствующие получению прибыли. Предприятие не полностью использовало мощности
из-за боязни перепроизводства и затоваривания. Производство осуществлялось по
ходу поступления заявок и заключения договоров, и, в связи с этим было не
ритмичным. Теперь, опираясь на результаты анализа себестоимости, было принято
решение об увеличении объемов производства и активному продвижению продукции на
рынке. Формирование цены производится не по затратному принципу, а в
соответствии с полученной факторной моделью себестоимости. Ситуация на
производстве изменилась в лучшую сторону, прибыль увеличилась на 5-10%.
Литература:
1.
Тюрин Ю.Н., Макаров А.А. Статистический анализ данных на компьютере
/ Под ред. В.Э.Фигурнова-М.: ИНФА-М.:
Финансы и статистика, 1997.-528с.
2. Л.А.Сошникова, В.Н.Тамашевич,
Г.Уебе, М.Шефер Многомерный статистический анализ в экономике/ Под ред.
В.Н.Тамашевича-М.: ЮНИТИ, 1999.- 598с