Бондаренко
О.С., Слєсарєв В.В.
Національний гірничий університет, Україна, Дніпропетровськ,
Інформаційний пошук в мережі Internet, як предмет
дослідження
Коли зростає важливість найбільш ефективного
використання природних і людських ресурсів, матеріальних і фінансових засобів,
особливого значення набувають завдання пошуку оптимальних рішень тієї або іншої
проблеми. Однією з таких проблем є проблема оптимізації процесів пошуку
текстових документів на специфічну тематику в мережі Internet. Проблема інформаційного
перевантаження на сьогоднішній момент
стоїть гостро у зв'язку з об'ємом баз
знань, що збільшується, не лише в мережі Internet, але і на кожному
підприємстві. Основна проблема інформаційного пошуку - збільшення точності і
швидкості процесу пошуку. Серед існуючих завдань інформаційного пошуку кожна з
них потребує знаходження оптимального рішення.
Інформаційний пошук - процес відшукування в деякій безлічі текстів
(документів) усіх таких, які присвячені вказаній в запиті темі (предмету) або
містять потрібні споживачеві факти, відомості. ІП
здійснюється за допомогою інформаційно-пошукової системи (ІПС) і виконується
вручну або з використанням засобів механізації або автоматизації. Широкого поширення ІПС набули з появою
мережі Internet. Пошук інформації є процесом виявлення в деякій безлічі
документів (текстів) усіх тих, які присвячені вказаній темі (предмету),
задовольняють заздалегідь певній умові пошуку (запиту) або містять необхідні
(що відповідають інформаційній потребі) факти, відомості, дані. Схема процесу
пошуку представлена на рисунку 1.1.
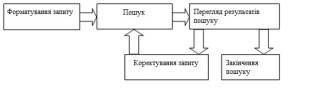
Рисунок 1.1 - Процес пошуку
Залежно від характеру інформації, яка
міститься у видаваних інформаційно - пошуковою системою (ІПС) текстах, ІП може бути документальним, у тому числі бібліографічним, і
фактографічним.
Розглянемо типову схему
інформаційно-пошукової системи на рисунку 1.2 . В різних публікаціях, присвячених конкретним системам,
приводяться схеми, які відрізняються один від одного тільки застосуванням
конкретних програмних рішень, але не принципом організації різних компонентів
системи.
Сlient - це
програма перегляду конкретного інформаційного ресурсу. Нині найбільш популярні мультипротокольні програми типу Netscape Navigator. Така програма забезпечує перегляд
документів World Wide Web, Gopher, Wais, FTP -архівів, поштових списків розсилки і груп
новин Usenet.
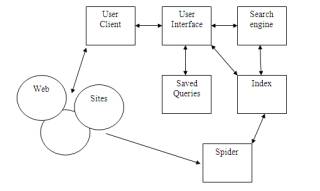
Рисунок 1.2 - Структура ІПС в мережі
Internet
У свою чергу усі ці інформаційні ресурси є об'єктом пошуку
інформаційно-пошукової системи.
User interface - інтерфейс користувача - це не просто
програма перегляду. У разі інформаційно-пошукової системи під цим
словосполученням розуміють і спосіб спілкування користувача з пошуковим
апаратом системи, тобто з системою формування запитів і переглядів результатів
пошуку.
Search engine - пошукова машина служить для трансляції запиту
користувача, який готується на інформаційно-пошуковій мові, у формальний запит
системи, пошуку посилань на інформаційні ресурси Мережі і видачі результатів
цього пошуку користувачеві.
Index database - індекс - це основний масив даних
інформаційно-пошукової системи. Він служить для пошуку адреси інформаційного
ресурсу.
Queries - запити користувача зберігаються в його особистій базі даних. На
відладку кожного запиту йде досить багато часу, і тому надзвичайно важливо зберігати
запити, на які система дає хороші відповіді.
Index robot - робот-індексувальник
служить для сканування Internet і підтримка бази даних індексу в
актуальному стані. Ця програма є основним джерелом інформації про стан
інформаційних ресурсів мережі.
Www sites - це увесь
Internet. А якщо говорити точніше, то це ті
інформаційні ресурси, перегляд яких забезпечується програмами перегляду.
Говорячи про
інформаційно-пошукові системи, використовують терміни запит і об'єкт запиту. Запит - це
формалізований спосіб вираження інформаційних потреб користувачем системи. Для
вираження інформаційної потреби використовується мова пошукових запитів,
синтаксис варіюється від системи до системи.
Не дивлячись на те, що
найбільш поширеним об'єктом запиту є текстовий документ, не існує ніяких
принципових обмежень. Зокрема, можливий пошук зображень, музики і іншої мультимедіа
інформації.
Процес занесення об'єктів пошуку в ІПС називається індексацією.
Технічна ефективність ІП характеризується двома
відносними показниками - коефіцієнтом точності (відношенням числа текстів, що
відповідають на інформаційний запит, до загального числа текстів в цій видачі)
і коефіцієнтом повноти (відношенням числа текстів, що відповідають на
інформаційний запит, до загального числа таких текстів, що містяться в цій
ІПС). Необхідні значення цих показників залежать від специфіки
інформаційних потреб.
Центральне завдання ІП
- допомогти користувачеві задовольнити його інформаційну потребу. Оскільки
описати інформаційні потреби користувача технічно непросто, вони формулюються
як деякий запит, що представляє з себе набір ключових слів, що характеризує те,
що шукає користувач.
Класичне завдання ІП,
з яким почався розвиток цієї області, - це пошук документів, що задовольняють
запиту, у рамках деякої статичної колекції документів. Але список завдань ІП
постійно розширюється і тепер включає:
·
Питання моделювання;
·
Класифікація
документів;
·
Фільтрація
документів;
·
Кластеризація
документів;
·
Проектування
архітектури пошукових систем і призначених для користувача інтерфейсів;
·
Витягання інформації, зокрема анотування і реферування документів;
·
Мови
запитів та ін.
Однією з основних проблем
інформаційного пошуку є необхідність обробки значних об'ємів текстової
інформації. Ця проблема спричиняє за собою наступну - велика тривалість обробки
запиту, що не радує сучасних користувачів. Перед проведенням аналізу методів
рішення проблем пошуку інформації необхідно згадати про найчастіше вирішувані
завдання інформаційного пошуку, таких як класифікація і кластеризація, які
найчастіше вирішуються при інформаційному пошуку об'єктом якого виступають
текстові документи.
Класифікація - це
закономірність, що дозволяє робити висновок відносно визначення характеристик
конкретної групи. Таким чином, для проведення класифікації мають бути
присутніми ознаки, що характеризують групу, до якої належить та або інша
подія або об'єкт (зазвичай при цьому на підставі аналізу вже класифікованих
подій формулюються деякі правила).
Фактично завдання класифікації - це класичне завдання розпізнавання, де
по повчальній вибірці система відносить новий об'єкт до тієї або іншої
категорії.
Завдання
кластеризації схоже із завданням класифікації, є її логічним продовженням, але
її відмінність в тому, що класи набору даних, що вивчається, заздалегідь не зумовлені.
Кластеризація
призначена для розбиття сукупності об'єктів на однорідні групи (кластери або
класи). Якщо ці вибірки представити як точки в признаковом просторі, то
завдання кластеризації зводиться до визначення "згущувань точок".
Мета кластеризації - пошук існуючих структур. Кластеризація є описовою
процедурою, вона не робить ніяких статистичних висновків, але дає можливість
провести розвідувальний аналіз і вивчити "структуру даних".
Кластеризація сьогодні застосовується при
реферуванні великих документальних масивів, визначення взаємозв'язаних груп
документів, спрощення процесу перегляду при пошуку необхідної інформації,
знаходження унікальних документів з колекції, виявлення дублікатів або дуже
близьких за змістом документів.
Кластеризація може бути використана для розподілу документів в
колекції по класах, що дозволяє підвищити швидкість пошуку документів і
точність відповіді. Саме з цих причин кластеризація текстових документів нині є
однією з найважливіших і динамічно таких, що розвиваються областей
інформаційних технологій.
Величезні об'єми
інформації в мережі Internet часто приводять до того, що кількість об'єктів, що
видаються по запиту користувача, дуже велика. Проте, в більшості випадків,
її можна зробити доступною для
сприйняття.
Литература:
1. Grabmeier J., Rudolph
A. Techniques of cluster algorithms in data mining // Data Mining and Knowledge
Discovery. – October 2002. – Vol. 6, № 4. – p. 303-360.
2.Oren Zamin and Oren Etzioni.
Grouper: A Dynamic Clustering Interface to Web Search Results. Department of Computer science and
Engineering, University of Wahington, Box 352350 Seattle, WA 98195-2350 USA.
3. Runkler
T.A., Bezdek J.C. Web mining with relational clustering // International
Journal of Approximate Reasoning. – February 2003. – Vol. 32, №. 2-3. – c.
217-236.