Бондаренко
О.С., Слєсарєв В.В.
Національний гірничий університет, Україна, Дніпропетровськ
Методи кластерного аналізу
Кластерний аналіз -
це багатовимірна статистична процедура, що виконує збір даних, що містять
інформацію про вибірку об'єктів, і потім упорядковуючи об'єкти в порівняно однорідні групи(Q -кластеризація, або Q -техника, власне
кластерний аналіз). Головне призначення кластерного аналізу - розбиття безлічі
досліджуваних об'єктів і ознак на однорідні у відповідному розумінні групи або
кластери. Це означає, що вирішується завдання групування даних і виявлення
відповідної структури в ній. Методи кластерного аналізу можна застосовувати в
самих різних випадках, навіть в тих випадках, коли йдеться про просте
угрупування, в якому усе зводиться до утворення груп по кількісній схожості.
Кластерний аналіз можна використовувати
циклічно. В цьому випадку дослідження робиться до тих пір, поки не будуть
досягнуті необхідні результати. При цьому кожен цикл тут може давати
інформацію, яка здатна сильно змінити спрямованість і підходи подальшого
застосування кластерного аналізу. Цей процес можна представити системою із
зворотним зв'язком.
Як і будь-який інший метод, кластерний аналіз
має певні недоліки і обмеження.
Зокрема, склад і кількість кластерів
залежить від вибираних критеріїв
розбиття. При зведенні початкового масиву даних до компактнішого виду можуть
виникати певні спотворення, а також можуть втрачатися індивідуальні риси
окремих об'єктів за рахунок заміни їх
характеристиками узагальнених значень параметрів кластера. При проведенні
класифікації об'єктів ігнорується дуже часто можливість відсутності в
даній сукупності яких-небудь значень
кластерів.
Кластерний аналіз виконує наступні основні
завдання:
- Розробка
типології або класифікації;
- Дослідження
корисних концептуальних схем групування об'єктів;
- Породження
гіпотез на основі дослідження даних;
- Перевірка
гіпотез або дослідження для визначення, чи дійсно типи (групи), виділені
тим або іншим способом, є присутніми в наявних.
 Незалежно
від предмета вивчення застосування кластерного аналізу припускає наступні
етапи:
Незалежно
від предмета вивчення застосування кластерного аналізу припускає наступні
етапи:
Рисунок 1 - Процес
застосування кластерного аналізу
Нехай X - безліч об'єктів, Y - безліч номерів (імен, міток) кластерів. Задана функція
відстані між об'єктами ![]() . Є кінцева повчальна вибірка об' єктів
. Є кінцева повчальна вибірка об' єктів ![]() Вимагається розбити вибірку на підмножини, що не перетинаються,
звані кластерами, так, щоб кожен кластер складався з об' єктів, близьких по
метриці
Вимагається розбити вибірку на підмножини, що не перетинаються,
звані кластерами, так, щоб кожен кластер складався з об' єктів, близьких по
метриці ![]() , а об' єкти різних кластерів істотно
відрізнялися. При цьому об' єкту
, а об' єкти різних кластерів істотно
відрізнялися. При цьому об' єкту ![]() приписується номер кластера
приписується номер кластера ![]() . Алгоритм кластеризації - це функція
. Алгоритм кластеризації - це функція ![]() , яка будь-якому об' єкту
, яка будь-якому об' єкту ![]() ставити у відповідність номер кластера
ставити у відповідність номер кластера ![]() .
Множина Y в
деяких випадках відома заздалегідь, проте частіше ставиться завдання визначити оптимальне число
кластерів, з точки зору того або іншого критерію якості кластеризації. Кластеризація (навчання без учителя)
відрізняється від класифікації (навчання з учителем) тим, що мітки початкових
об'єктів
.
Множина Y в
деяких випадках відома заздалегідь, проте частіше ставиться завдання визначити оптимальне число
кластерів, з точки зору того або іншого критерію якості кластеризації. Кластеризація (навчання без учителя)
відрізняється від класифікації (навчання з учителем) тим, що мітки початкових
об'єктів ![]() спочатку не задані, і навіть може бути
невідома сама множина Y .
спочатку не задані, і навіть може бути
невідома сама множина Y .
Методи кластерного аналізу можна розділити
на дві групи:
·
ієрархічні;
·
неієрархічні.
На даний момент
існує безліч методів, що здійснюють кластеризацію документів. Деякі методи можуть використовувати кілька
альтернативних алгоритмів. Далі
виділений список даних методів :
·
- метод Custom Search Folders – дозволяє звузити
результати пошуку шляхом розподілу їх по "папках" (folders). Ця система вже реалізована в пошуковому сервері, що
знаходиться за адресою www.northernlight.com, і має назву NorthernLight, -
відповідно;
·
- LSA/LSI – Latent Semantic Analysis/Indexing - Шляхом факторного аналізу безлічі документів виявляються латентні
(приховані) чинники, які надалі є основою для утворення кластерів документів;
·
- STC – Suffix Tree Clustering - Кластери утворюються у
вузлах спеціального виду дерева - суффиксного дерева, яке будується із слів і
фраз вхідних документів;
·
- Single Link - Complete Link, Group Average – ці методи розбивають безліч
документів на кластери, розташовані в деревовидній структурі,що отримується за
допомогою ієрархічною аггломеративной кластеризацією;
·
- Scatter/Gather - Представляється як
ітеративний процес, що спочатку розбиває (scatter) безліч документів на групи і
представленні потім цих груп користувачеві (gather) для подальшого аналізу. Далі
процес повторюється знову над конкретними групами;
·
-
K-means - Відноситься до неієрархічних алгоритмів. Кластери представлені у вигляді
центроїдів , що є "центром маси" усіх документів;
·
- SOM – Self-Organizing Maps. Робить класифікацію документів
з використанням самоналагоджувальної нейронної мережі.
Найбільш відповідають вимогам
алгоритми SOM і Kmeans, в основі якого лежить ітеративний
процес стабілізації центроїдів кластерів. У алгоритмі SOM використовується універсальний апроксиматор -
нейронна мережа, навчання мережі без учителя, самоорганізація мережі, простота
реалізації, гарантоване отримання відповіді після проходження даних по шарах,
наочність результатів кластеризації. Алгоритм K -
means не дивлячись на те, що має недостатню точність і інші недоліки наділений іншими достоїнствами.
У основі алгоритму k - means (К-середніх) лежить ітеративний процес стабілізації
центроїдів кластерів. Основною характеристикою кластера є його центроїд і уся
робота алгоритму спрямована на стабілізацію або, у кращому разі, повне
припинення зміни центроїда кластера. Алгоритм
k -средних будує k кластерів, розташованих на можливо великих відстанях один
від одного. Дія алгоритму така, що він прагне мінімізувати середньоквадратичне
відхилення на точках кожного кластера :
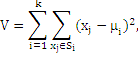
де k - кількість кластерів, Si – отримані кластери, ![]() и μi – центри мас векторів
и μi – центри мас векторів ![]() . Основна ідея полягає в тому, що
на кожній ітерації переобчислюється центр мас для кожного кластера, отриманого на попередньому кроці, потім
вектори розбиваються на кластери знову відповідно до того, який з нових центрів
виявився ближче по выбраной метриці. Алгоритм завершується, коли на якійсь
ітерації не відбувається зміни кластерів. Основний тип завдань, які вирішує
алгоритм k -средних, - наявність припущень (гіпотез) відносно числа кластерів,
при цьому вони мають бути різні настільки, наскільки це можливо. Вибір числа k
може базуватися на результатах попередніх досліджень, теоретичних міркуваннях
або інтуїції.
. Основна ідея полягає в тому, що
на кожній ітерації переобчислюється центр мас для кожного кластера, отриманого на попередньому кроці, потім
вектори розбиваються на кластери знову відповідно до того, який з нових центрів
виявився ближче по выбраной метриці. Алгоритм завершується, коли на якійсь
ітерації не відбувається зміни кластерів. Основний тип завдань, які вирішує
алгоритм k -средних, - наявність припущень (гіпотез) відносно числа кластерів,
при цьому вони мають бути різні настільки, наскільки це можливо. Вибір числа k
може базуватися на результатах попередніх досліджень, теоретичних міркуваннях
або інтуїції.
Структура SOM. SOM має на увазі використання впорядкованої структури нейронів.
Зазвичай використовуються одне і двовимірні сітки. Мережа Кохонена, на відміну
від багатошарової нейронної мережі, дуже проста, вона є двома шаром: вхідний і
вихідний. Її також називають самоорганізуючою картою. Елементи карти
розташовуються в деякому просторі, як правило, двовимірному. Мережа Кохонена
зображена на рисунку 2.
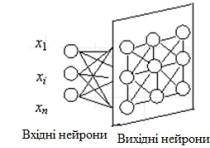
Рисунок 2 -
Структура мережі Кохонена
При цьому кожен нейрон мережі є n-вимірним
вектором-стовпцем ![]() , де n визначається розмірністю початкового простору (розмірністю
вхідних векторів). Спочатку відома розмірність вхідних даних, по ній деяким
чином будується первинний варіант карти.
Застосування одно і двовимірних мереж пов'язано з тим, що виникають
проблеми при відображенні просторових структур більшої розмірності (при цьому
знову виникають проблеми з пониженням розмірності до двовимірної, уявної на
моніторі).
, де n визначається розмірністю початкового простору (розмірністю
вхідних векторів). Спочатку відома розмірність вхідних даних, по ній деяким
чином будується первинний варіант карти.
Застосування одно і двовимірних мереж пов'язано з тим, що виникають
проблеми при відображенні просторових структур більшої розмірності (при цьому
знову виникають проблеми з пониженням розмірності до двовимірної, уявної на
моніторі).
Математична
модель нейрона може бути описана таким чином:
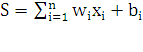 ,
,
![]()
де wi – вага синапсу (і=1..n), b –
значення зміщення, s – результат додавання, xі -
компонент вектору, що входить, y – сигнал, що виходить, n – число входів нейрона, f – нелінійне перетворення.
Зазвичай
нейрони розташовуються у вузлах двовимірної мережі з прямокутними або шестикутними
осередками. При цьому, як було сказано вище, нейрони також взаємодіють один з одним.
Величина цієї взаємодії
визначається відстанню між нейронами на карті. На малюнку 3 даний приклад
відстані для шестикутної і чотирикутної сіток. При цьому легко помітити, що для шестикутної сітки відстань між
нейронами більше співпадає з відстанню Евкліда, чим для чотирикутної сітки.
При цьому
кількість нейронів в сітці визначає міра деталізації результату роботи
алгоритму, і кінець кінцем від цього залежить точність узагальнювальної
здатності карти. Мережа Кохонена
навчається без учителя. Це означає, що на вхід поступають повчальні дані, і
відбувається корекція синаптических вагів нейронів. Зміни внутрішньої структури
мережі не відбувається, тому необхідно заздалегідь знати її внутрішню структуру
і кількість передбачуваних класів.
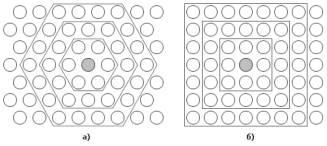
Рисунок 3.3 - Відстань між нейронами
на карті для шестикутної (а) і чотирикутної (б) сіток.
Для
навчання мережі алгоритм Кохонена використовує
інформацію про попередній крок навчання, тому не можна чітко говорити
про швидкість навчання такої мережі. Швидкість навчання мережі сильно залежить
від порядку вступу повчальних даних на вхід мережі. Для будь-якої нейронної
мережі є тестовий набір, який застосовується до мережі, для контролю за
процесом навчання, це необхідно для того, щоб не сталося недоліку або
перенасичення в процесі навчання.
Під час роботи на
вхід мережі подаються дані і відбувається їх класифікація. У імовірнісному
режимі на виході системи користувач отримує вірогідність того, що вхідний
об'єкт відноситься до того або іншого класу. Якщо мережа не може виділити
об'єкт в певний клас, то має місце факт зародження нового класу даних.
Література:
1. Grabmeier J., Rudolph
A. Techniques of cluster algorithms in data mining // Data Mining and Knowledge
Discovery. – October 2002. – Vol. 6, № 4. – p. 303-360.
2.Oren Zamin and Oren Etzioni.
Grouper: A Dynamic Clustering Interface to Web Search Results. Department of Computer science and
Engineering, University of Wahington, Box 352350 Seattle, WA 98195-2350 USA.
3. Runkler
T.A., Bezdek J.C. Web mining with relational clustering // International
Journal of Approximate Reasoning. – February 2003. – Vol. 32, №. 2-3. – c.
217-236.