Cегментация веб-страниц и ее проблемы
Определение и получение
различных элементов информации с интернета
становится все сложнее и сложнее. Кроме основного контента (статьи,
видео) современные веб-страницы содержат большое количество различных
элементов, таких как навигационное меню, объявления, комментарии, различные вставки документов, результаты работы
встроенных плагинов социальных сетей и т.д.
Сегментация различных
элементов в соответствующие и не соответствующие основному смысловому
содержимому части имеет важное значение для повышения качества результатов. Существует
несколько областей применения сегментации веб-страниц: (1) Извлечение
содержимого для более тесной интеграции с различными социальными сервисами, для
предоставления качественной информации аудитории. (2) Удаление информационного
шума увеличивает классическую производительности системы. (3) Повышение
качества интернет поиска по ключевым словам страницы.
Чаще всего структура
веб-страницы (т. е. дерево DOM) анализируется на наличие определенных шаблонов
с последующим их удалением.
Визуальная проблема
Удивительно, насколько различные
HTML
структуры документов можно встретить на различных веб-сайтах. Этому
способствует не только использование различных макетов, но также и то, что есть
универсальные способы моделирования
структуры (злоупотребление различными тегами, использование <div> и <table> верстки и т.д.). Эта ситуация делает сегментацию
веб-страницы нетривиальной задачей.
Лингвистическая проблема
В области лингвистики
количественные языковые единицы, такие как слова, слоги и предложения широко
используются в качестве статистической меры для выявления структурных моделей в
текстовых документах, в частности, для
выявление подтем, а также для
обнаружения изменений в стиле написания
(это можно рассматривать как особую форму сегментации).
Общепринятое предположении,
что вероятность наличия в документе класса х исключительно зависит от вероятности
соседних низших классов х - 1:
![]()
Например, если текст
разделен на блоки почти одинакового размера, то считается, что вероятности
возникновения какого-либо класса отрицательно гипергеометрическая (Закон
Фрумкина или законом текстовых блоков):
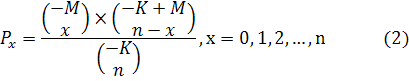
С учетом этого закона для правильной сегментации
очевидной стратегией является изучение статистических свойств последующих
блоков с точки зрения их количественных свойств. Целесообразно рассматривать эти распределение
для сегментации внутри текстовых блоков. Ципф утверждает, что частота появления
объектов определенного класса приблизительно обратно пропорциональна его порядковому номеру (рангу):
![]()
Возвращаясь к проблеме
сегментации веб-страницы, весьма сомнительно, что нахождение какого-либо HTML тега форматирования даст достаточную
информацию для проведения правильной сегментации, даст ответ на вопрос
отнесения данной информации к основному смысловому содержанию страницы. Но во всех правилах есть исключения. Есть
несколько тегов, наличие которых дает высокий шанс отнесения данной информации
к определенному сегменту. Например, при нахождении тегов <H1> ,<H2>,<H3> с большой долей вероятности можно утверждать, что информация,
заключенная в этих тегах относится к основному содержанию страницы, относится к
названию. Также очевидно, что отсутствие тегов является сильным индикатором для
идентификации информации как пустого блока (атомарного блока).
Таким образом, веб-страницы
моделируются в виде серии атомарных блоков, чередующихся с последовательностью из одного или
нескольких открытых и закрытых тегов. Назовем последовательности атомарных
блоков - разрывом. Отбросив подобные разрывы, получив чистую последовательность
тегов , мы значительно упростим задачу сегментации.
Следующее необходимое
действие – это анализ самих тегов, оставшихся блоков. Хотя всегда можно
определить наличие в блоке некоторых тегов на основе различных правил, мы
ориентируемся на анализе блоков на наличие текстовых свойств. Например, наличие в блоке только коротких предложений (“Контакты”,
“ Главная”, “Обратная связь”) скорее
всего соответствует навигационному меню, т.е не соответствует основному
содержимому. А наличие в подвале
страницы одного предложения (“Copyright
(c) 2013 by … All rights reserved”) относится к информационному блоку, который
также не относится к содержимому.
Это похоже на анализ стиля
письма, сравнивая длины предложений. Но в случае отсутствием надлежащего предложения
в шаблоне элемента, возникают серьезные трудности в анализе текстовых свойств
блока. В таком случаем мы можем заменить длины предложений в тексте
на плотность текста, то есть в частности количество слов. Определение плотности
текста было предложено Джеретом Спулом
и соавторами, как соотношение между общим количеством слов в блоке и высотой блока
в дюймах. Аналогичное понятие известно в Computer Vision, как
интенсивность области изображения.
Рассмотрим эту концепцию
в рамках HTML текста. Аналогом пикселей изображения в HTML является символьные
данные (атомарные части текста),
изображение представляет собой последовательность пикселей, в нашем случаем последовательность
элементарных частей (символов ) представляет собой блок с текстом. Для
определения высота текстового блока, мы сформируем весь текст с учетом постоянной
максимальной ширины строки (в символах)
![]() . В результате плотности блока
. В результате плотности блока ![]() можно рассчитать следующим образом:
можно рассчитать следующим образом:
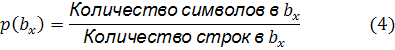
Это определение
плотности текста не учитывает лексический и грамматический анализы, которые
должны быть выполнены. Этот показатель может служить своего рода
дискриминатором между сентенциальным
текстом (высокой плотности) и текстовыми шаблонами (низкой плотности). Предположим
![]() . Это традиционная ширина экрана терминалов. Если предположить, что
средняя длина слова 5,1 символа, то мы
можем записать максимум
. Это традиционная ширина экрана терминалов. Если предположить, что
средняя длина слова 5,1 символа, то мы
можем записать максимум ![]() отдельных слов (лексем) в строке, что примерно соответствует
одному среднему предложению. Также очевидно, что абсолютный максимум 40
односимвольных предложений в каждой строке. Эти вычисления необходимы, чтобы
исключить последнюю строку многострочного блока, так как было бы ошибкой
вычислять фактическую плотность с учетом строки, которая не полностью соответствует длине
отдельных слов (лексем) в строке, что примерно соответствует
одному среднему предложению. Также очевидно, что абсолютный максимум 40
односимвольных предложений в каждой строке. Эти вычисления необходимы, чтобы
исключить последнюю строку многострочного блока, так как было бы ошибкой
вычислять фактическую плотность с учетом строки, которая не полностью соответствует длине ![]() . Учитывая набор лексем T,
содержащихся в множестве заполненных строк
L, покрывающих блок
. Учитывая набор лексем T,
содержащихся в множестве заполненных строк
L, покрывающих блок ![]() , мы можем переформулировать
уравнение 4 следующим образом:
, мы можем переформулировать
уравнение 4 следующим образом:
![]()
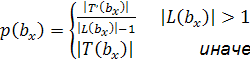 (5)
(5)
Удвоение числа лексем
приводит к почти удвоенному числу линий, которые необходимо нормировать снова
(формула 5).
Таким образом, задача
обнаружения “ненужных” блоков разделения на веб-странице в конечном счете,
сводится к нахождению и сравнению плотностей этих блоков.