Современные
информационные технологии/Компьютерная инженерия
Мясищев А.А.
Хмельницкий национальный
университет, Украина
Один из способов организации
голосового диалога на Андроид - устройствах
В последнее время наблюдается
значительный рост интереса к технологиям, связанным с распознаванием речи. Например, задачи управления устройствами с
помощью голосовых команд, задачи справочной службы, которая предоставляют
информацию после запроса в более естественной форме - с помощью голоса. Много
задач возникает при желании взаимодействовать с помощью голоса с мобильными
устройствами. Например, ввод голосовых команд для получения информации с Интернета,
прокладывания маршрута движения, запуск
пользовательских программ, диктовка текста. Последнее время появилась возможность
управления домашней, офисной техникой с помощью андроид - устройств голосовыми
командами, что широко рекламируется как технология "умный дом".
Предпосылкой развития речевых
технологий является значительное увеличение вычислительных возможностей, объема
памяти при значительном уменьшении габаритов компьютерных систем. Следует также
отметить развитие математических
методов, позволяющих выполнить требуемую обработку аудио сигнала путем
выделения из него информативных
признаков, однозначно характеризующих речевой сигнал. Например, это широко используемое дискретное преобразование
Фурье, известное из теории цифровой обработки сигналов. В последнее время
используется вейвлет - преобразования,
результаты которого более информативны для выделения акустических составляющих.
Дальнейшая обработка выполняется с использованием акустической модели, которая
ставит в соответствие выделенным параметрам конкретные звуки(фонемы).
Окончательное построение фразы, предложения, голосовой команды выполняется с
помощью лингвистической модели. Следует отметить, что последние две модели
используют методы статистического
анализа - это метод скрытого Марковского моделирования (СММ), метод
динамического программирования и метод нейронных сетей[1] .
В работе рассматривается интерфейс
взаимодействия человека и компьютера на базе Андроид, построенного на основе
инструментария Google. Здесь
предполагается, что обработка аудио сигнала, построение текстовой строки на
основе произнесенной фразы выполняется специальными библиотеками(классами,
методами), которые обеспечивают доступ к сервису распознавания и синтеза речи,
предоставляемым Google. В рамках этой работы на устройстве
Андроид должны выполняться следующие задачи:
1.
При нажатии на кнопку приложения "преобразования текста в речь" с
помощью механизма Intent(намерение) вызывается Активити, выполняющее
прослушивание произнесенной фразы с последующей передачей ее сервису
распознавания речи. Он может находиться на серверах Google или установлен на
мобильном устройстве, если оно поддерживает сервис "голосовой поиск offline". Если работа производится с серверами через
Интернет результаты распознавания фраз будут значительно лучше. Для решения
этой части задачи используется класс RecognizerIntent.
2.
Результат распознавания в виде текстовой строки сопоставляется со строкой, находящейся в памяти. Если
сопоставление истинно, то запускается синтезатор речи Google и произносится фраза из
памяти, соответствующая сопоставленной. Например, результат распознавания
"как тебя зовут". Соответствие
этой фразе в памяти "меня зовут маша". Синтезатор сгенерирует эту
фразу. Если сопоставление ложно, то синтезатор сгенерирует фразу,
соответствующую распознанной строке. Для синтеза речи используется класс TextToSpeech.
3.
После окончания синтеза речи основное приложение вновь запускает Активити,
выполняющее прослушивание произнесенной фразы. Это повторение выполняется до
тех пор, пока не будет произнесена фраза "конец связи" или
"какая погода в хмельницком". После первой фразы приложение должно после синтеза фразы "до
свидания" перейти в режим ожидания пока вновь не будет нажата на кнопка "преобразования
текста в речь". После второй
фразы с последующим синтезом "
посмотрите в
интернете, открываю браузер", основное приложение открывает браузер по ссылке
" https://pogoda.yandex.ua/khmelnitsky/details"
и переходит в режим ожидания, как и в первом случае.
4.
После синтеза речи выполняется ее вывод
через динамики компьютера. Поэтому необходимо в программе использовать
специальный механизм, который бы прослушивал работу акустического вывода речи,
а после окончания запускал вновь активити по прослушиванию речи и ее
распознаванию. В этом случае будет смоделирован полноценный диалог речевого общения между пользователем и
компьютером. Данный механизм реализуется с помощью абстрактного класса
utteranceProgressListener. Он использует методы, которым передается управление
в начале, в конце высказывания синтезатором и при появлении ошибки.
В соответствии с перечисленными
задачами рассмотрим отдельные блоки основного приложения.
1.
Создается класс приложения MainActivity, наследуемый от класса
Activity - базового класса для всех экранов приложения. Здесь используется
интерфейс TextToSpeech.OnInitListener для инициализации синтезатора речи.
public class MainActivity extends Activity implements TextToSpeech.OnInitListener {
// Объявление переменных
public String
sp10 = "как тебя зовут";
public String sp20
= "меня
зовут
маша";
...
// Описание
хеш карты для хранения ключа, необходимое для доступа
// к методу,
вызываемому при окончании акустического вывода речи
private
HashMap<String, String> params = new HashMap<String, String>();
@Override
public void
onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
txtText
= (TextView) findViewById(R.id.input_text);
// Создание экземпляра класса слушателя
utteranceProgressListener textSpeech = new utteranceProgressListener();
tts =
new TextToSpeech(this, this); // Экземпляр класса
синтезатора
речи
// Включение слушателя вывода синтезатора речи,
который определяет
// начало и конец произнесенной синтезатором
речи
tts.setOnUtteranceProgressListener(textSpeech);
// Вызов
активности распознавателя голоса при нажатии на кнопку
public void
click(View view) { spi(); }
@Override
// Следующий
метод выполняет инициализацию синтезатора речи.
// Он
требует назначения интерфейса TextToSeech.OnInitListener для
// базового класса приложения MainActivity
public void onInit(int
status) {
if (status == TextToSpeech.SUCCESS)
{// При
успешной
инициализации
tts.setLanguage(Locale.getDefault()); // выполняется
использование
языка
// синтезатора,
установленного по умолчанию
// Передача
параметра params для вызова слушателя синтезируемой речи. params.put(TextToSpeech.Engine.KEY_PARAM_UTTERANCE_ID,"5678"); } else {txtText.setText("Инициализация
не выполнена"); } }
... (далее классы
и методы, которые кратко описаны ниже)
}
2.
Метод spi() используется для
запуска активности распознавания голоса Google с помощью механизма
Intent. Активность формирует запрос к серверам Google и посылает его через
Интернет.
public void
spi() {
// Intent
подготавливает
запуск активности распознавания голоса
Intent intent
= new
Intent(RecognizerIntent.ACTION_RECOGNIZE_SPEECH);
// Передача в
активность параметров:
// 1. Задает модель распознавания, оптимальную для коротких
фраз
intent.putExtra(RecognizerIntent.EXTRA_LANGUAGE_MODEL,
RecognizerIntent.LANGUAGE_MODEL_WEB_SEARCH);
// 2. Задает
подсказку
пользователю
intent.putExtra(RecognizerIntent.EXTRA_PROMPT, "Говори
громко
и
четко!");
//
Запускается активити, выполняющее распознавание произнесенных
// фраз и
возвращающая результаты распознавания
startActivityForResult(intent, CODE);
}
3.
Метод onActivityResult используется в
программе для получения результатов работы активити распознавания речи.
Фактически он принимает результат распознавания с серверов Google через
Интернет и передает их основному приложению.
protected void onActivityResult(int requestCode, int
resultCode, Intent data) {
// Возврат результатов распознавания речи
super.onActivityResult(requestCode, resultCode, data);
// Если это
результаты распознавания речи (CODE)
// и процесс
распознавания прошел успешно
switch (requestCode){
case
CODE: {
if (resultCode == RESULT_OK && null != data) {
// то получаем список
текстовых строк - результат распознавания.
// Строк
может быть несколько, а правильные результаты идут в начале
ArrayList<String>
spee = data.getStringArrayListExtra(RecognizerIntent.EXTRA_RESULTS);
sp =spee.get(0);
// Из массива строк - результатов выбирается самая первая
txtText.setText(sp);
// и выводится на экран
spout
= sp;
// Сопоставления результата распознавания со
строками вопросов
int r10 = sp.compareTo(sp10);
...
// В
зависимости от результата сопоставления выбирается тот или иной ответ
if (r10
== 0) spout = sp20; ...
// Синтез
речи для выбранного ответа
tts.speak(spout, TextToSpeech.QUEUE_ADD, params);
} }
break; }
}
4. Обьявляем класс
utteranceProgressListener, наследуемый от класса
UtteranceProgressListener. Он необходим для
выполнения действий после прослушивания синтеза речи. Выше было отмечено, что
активити распознавания речи должно запускаться автоматически после
произнесенной синтезатором речи, фразы до тех пор, пока не встретятся голосовые
команды "конец связи" или " какая погода в хмельницком ". Этот
класс содержит необходимый нам метод, который выполняется после завершения
звука динамиком, сгенерированным синтезатором.
public class
utteranceProgressListener extends UtteranceProgressListener {
@Override
// Метод
вызывается, когда синтезированное высказывание завершено
public
void onDone(String utteranceId) {
int stop_r = sp.compareTo("конец
связи");
int r13 = sp.compareTo(sp13);
if
( r13==0 ) { Intent brIntent = new Intent(Intent.ACTION_VIEW,
Uri.parse("https://pogoda.yandex.ua/khmelnitsky/details"));
startActivity(brIntent); stop_r=0; }
// Не
вызывать активность распознавание голоса, если произнесена фраза
//
"конец связи" или "какая погода в хмельницком"
if( stop_r !=
0 ) spi();}
@Override
// Метод
вызывается, когда синтезированное высказывание начинается
public
void onStart(String utteranceId) { }
@Override
public
void onError(String utteranceId) { } }
5.
Файл разметки, отображающий строку
вывода распознанного текста и кнопку для активации голосового ввода имеет вид:
<RelativeLayout
xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="fill_parent"
android:layout_height="wrap_content"
android:layout_alignParentBottom="true"
android:layout_marginBottom="10dp"
android:orientation="vertical"
android:padding="20dp">
<Button
android:id="@+id/speak_now"
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:text="Нажмите
для преобразования текста в речь"
android:textSize="50dp"
android:onClick="click"
android:layout_alignParentTop="true"
android:layout_alignParentEnd="true"
android:layout_marginTop="688dp"
/>
<TextView
android:layout_width="wrap_content"
android:layout_height="wrap_content"
android:id="@+id/input_text"
android:layout_alignParentTop="true"
android:layout_centerHorizontal="true"
android:layout_marginTop="70dp"
android:hint="Распознанный текст"
android:textSize="45dp"
android:gravity="center"
/>
</RelativeLayout>
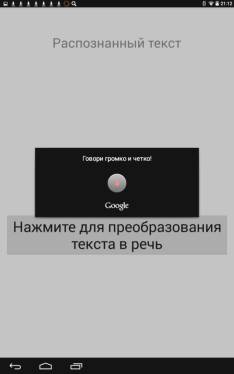
На рис.1 показаны фото запущенного
приложения до и после активации голосового ввода. Программа
написана на языке Java в Android Studio
1.0.1. Посмотреть видео работы программы можно по ссылке[3].
|
|
|
|
Рис.1. Фотография приложения до и после активации
голосового ввода |
|

Выводы.
1.
Представлена программа для мобильного
устройства на ОС Андроид, позволяющая организовать простой речевой диалог с
пользователем. Здесь используется инструментарий Google для распознавания и
синтеза речи. Причем повторный запуск активити распознавания выполняется в
цикле после окончания генерации звука благодаря использования класса
UtteranceProgressListener. Этот подход может применен для ввода нескольких голосовых
команд с целью управления устройствами.
2.
Следует отметить высокое качество распознавания произнесенных фраз при работе с
серверами Google через Интернет и более низкое при работе с библиотекой
речевого поиска Google в режиме offline, если мобильное
устройство поддерживает этот режим.
3.
При создании библиотеки голосовых команд необходимо подбирать такие команды,
которые распознаются с меньшими ошибками. Особенно это относится к режиму offline.
4.
Опыт показал, что при создании систем голосового управления для более надежного
распознавания и автономности целесообразно использовать технологию
распознавания с коротким словарем команд, которая работает всегда в режиме offline.
Литература.
1. А.В. Фролов Г.В. Фролов.
Синтез и распознавание речи. Современные решения. / Интернет-ресурс. - Режим
доступа: http://www.frolov-lib.ru/books/hi/index.html.
- 2003.
2.Android.
/ Интернет-ресурс. - Режим доступа:
http://developer.android.com/reference/android/package-summary.htm.
3. Андроид и ардуино в
задачах голосового управления через Bluetooth. / Интернет-ресурс. -
Режим доступа:
https://youtu.be/zis9Q8AuxuU