Современные информационные технологии.
Информационная безопасность.
Д.т.н. Юдін О.К., к.т.н.
Луцький М.Г., аспірант Чунарьова
А.В.
Національний
авіаційний університет(НАУ), Україна
Двовимірне математичне очікування в
статистичних правилах прийняття рішення
Вступ
При проектуванні сучасних
інформаційно-комунікаційних систем та мереж (ІКСМ) одним з найважливіших є
завдання забезпечення високої вірогідності та достовірності передачі даних. До
найбільш ефективних методів рішення даного завдання варто віднести застосування
завадостійкого канального кодування, як технології забезпечення достовірності і
цілісності інформаційних повідомлень.
Ефективність та
надійність роботи моделей вирішальних процедур статистичних правил прийняття
рішення для задач вірогідного декодування даних, оцінюється рядом
характеристик, до основної з яких відносять: ймовірність правильної
ідентифікації повної кодової конструкції та зменшення ймовірності появи не
коригованих помилок в інформаційному потоці даних.
Основним завдання при побудові моделі процедури прийняття
рішення є оцінка точності ідентифікації
з урахуванням забезпечення максимальної ймовірності правильного розпізнавання
цифрового інформаційного повідомлення.
Постановка задачі.
Задачею даних досліджень є підвищення достовірності
правильної ідентифікації кодового слова
на базі мінімально-достатньої кількості інформації з урахуванням сформованих моделей
вирішальних процедур статистичних правил прийняття рішень [1,2]. До питань
досліджень, також відноситься: проведення аналізу адекватності зазначених
методів у задачах вірогідної ідентифікації повної кодової конструкції при
використанні стандартних багато альтернативних процедур прийняття рішення.
Зазначені процедури повинні проходити з умов зменшення ймовірності появи не
коригованих помилок в інформаційному потоці даних.
Метою даних
досліджень є підвищення достовірності правильної
ідентифікації кодового слова на базі
мінімально-достатньої кількості інформації, а також встановлення кількісних значень оцінки ефективності розробленого
методу ідентифікації повної кодової конструкції на основі мінімально-достатньої
кількості інформації.
Для оцінки достовірності розробленого методу з
умов математичного моделювання в ході роботи, сформуємо графічні залежності апостеріорної
ймовірності правильної ідентифікації повної кодової конструкції та графічні
залежності ймовірності появи не коригованих помилок від співвідношення сигнал/шум
![]() .
.
Метод ідентифікації та відновлення кодових
конструкцій на базі мінімально-достатньої кількості інформації
В попередніх
роботах, розроблено нові методи відновлення кодових конструкцій на базі
достатньої кількості інформації з урахуванням інформативних складових сигналу
[1,2]. Показано, що сформований вище метод, надає можливість використання
критеріїв й процедур ідентифікації інформаційних сигналів на базі мінімально
достатньої кількості інформації ![]() з визначеними
порогами прийняття рішень
з визначеними
порогами прийняття рішень ![]() . Однак, данні правила розроблені для ідентифікації сигналів
сформованих від різних класів інформаційних об’єктів з різко відмінними
інформаційними параметрами та мають конкретні недоліки.
. Однак, данні правила розроблені для ідентифікації сигналів
сформованих від різних класів інформаційних об’єктів з різко відмінними
інформаційними параметрами та мають конкретні недоліки.
Доведено, що
вирішення даної задачі можливе на основі досягнення мінімально достатньої міри
кількості інформації, що сформована з урахуванням найбільш інформативних
параметрів інформаційних складових. Визначено, що інформативними параметрами
сигналу є спектральне представлення послідовності кодових слів, як найбільш
інформативне для прийняття остаточного рішення про достовірну ідентифікацію
кодового слова. Показано, що
спектральне подання сигналу використовується при розрахунках умовних
ймовірностей і виборі найбільш ймовірної гіпотези з урахуванням достатньої
кількість інформації, яка відповідає кожній гіпотезі та позначена як: ![]() у відповідності до
у відповідності до ![]() , де
, де ![]() . Для кожної гіпотези
. Для кожної гіпотези ![]() обчислюється
кількість інформації
обчислюється
кількість інформації ![]() , що міститься в спектрі. Позначимо
, що міститься в спектрі. Позначимо ![]() (
(![]() ,
, ![]() ), як спектральне представлення прийнятого інформаційного
сигналу при наявності в каналі зв’язку білого гауссового шуму.
), як спектральне представлення прийнятого інформаційного
сигналу при наявності в каналі зв’язку білого гауссового шуму.
Визначено, що
міра кількості інформації ![]() , яка розраховується для кожної гіпотези
, яка розраховується для кожної гіпотези ![]() , має наступний вид:
, має наступний вид:
![]() , (1)
, (1)
де ![]() – апостеріорна
ймовірність появи інформаційного сигналу;
– апостеріорна
ймовірність появи інформаційного сигналу; ![]() – узагальнена міра
невизначеності для
– узагальнена міра
невизначеності для ![]() -го інформаційного сигналу, розрахована по апостеріорним
ймовірностям.
-го інформаційного сигналу, розрахована по апостеріорним
ймовірностям.
Визначено, що
враховуючи те, що за інформативний параметр інформаційного сигналу
використовується спектральне представлення, формула (1) прийме вид:
![]() , (2)
, (2)
де ![]() – апостеріорна
ймовірність появи інформаційного сигналу;
– апостеріорна
ймовірність появи інформаційного сигналу; ![]() – узагальнена міра
невизначеності розрахована по апостеріорній ймовірності:
– узагальнена міра
невизначеності розрахована по апостеріорній ймовірності:
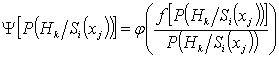 .
.
У результаті
того, що ми використали, як інформативний параметр спектральне представлення
сигналу, то розрахунок умовної щільності ймовірності розподілу знайдемо по
формулі:
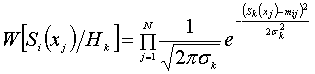 , (3)
, (3)
де ![]() – прийнятий сигнал,
за інформативний параметр якого взято спектральне представлення,
– прийнятий сигнал,
за інформативний параметр якого взято спектральне представлення, ![]() – поточний номер
спектральних складових кожного
– поточний номер
спектральних складових кожного ![]() прийнятого сигналу (
прийнятого сигналу (![]() ),
), ![]() – поточне значення
номеру інформаційного сигналу для множини гіпотез
– поточне значення
номеру інформаційного сигналу для множини гіпотез ![]() (
(![]() ),
), ![]() – двохпараметричне
математичне очікування.
– двохпараметричне
математичне очікування.
За
двохпараметричне математичне очікування ![]() приймемо двомірне
математичне очікування
приймемо двомірне
математичне очікування ![]() корисного
інформаційного сигналу
корисного
інформаційного сигналу ![]() , де
, де ![]() – поточне значення
номеру сигналу для множини гіпотез,
– поточне значення
номеру сигналу для множини гіпотез, ![]() – поточний номер
спектральних складових кожного інформаційного сигналу).
– поточний номер
спектральних складових кожного інформаційного сигналу).
Тобто, для
формування процедури ідентифікації кодових конструкцій будемо використовувати
не узагальнене математичне очікування сигналу (відповідної гіпотези), а
математичне очікування кожної спектральної складової. Покажемо, що використання спектрального представлення кодового
слова на основі використання двохпараметричного математичного очікування ![]() , буде найкращим для побудови математичної процедури прийняття
рішення з умов збільшення узагальненої міри кількості інформації. Введене
двохпараметричне математичне очікування, яке приймає участь в процесі побудови
процедури прийняття рішення, покликане забезпечити достатню міру кількості
інформації та зменшити невизначеність правила.
, буде найкращим для побудови математичної процедури прийняття
рішення з умов збільшення узагальненої міри кількості інформації. Введене
двохпараметричне математичне очікування, яке приймає участь в процесі побудови
процедури прийняття рішення, покликане забезпечити достатню міру кількості
інформації та зменшити невизначеність правила.
Введене
математичне очікування надалі буде використовуватися при побудові математичної
процедури прийняття рішення, а саме - розрахунку умовної щільності розподілу
сигналу, апостеріорної ймовірності правильної ідентифікації кодової
конструкції, міри невизначеності та міри кількості інформації. Доведемо
наступне, що кожна ![]() спектральна складова
інформаційного сигналу
спектральна складова
інформаційного сигналу ![]() має нормальний закон
розподілу (Гауссівський закон) випадкових величин при умові, що в каналі діє
адитивний білий гаусів шум з нормальним розподілом. Оскільки кожна спектральна
складова
має нормальний закон
розподілу (Гауссівський закон) випадкових величин при умові, що в каналі діє
адитивний білий гаусів шум з нормальним розподілом. Оскільки кожна спектральна
складова ![]() інформаційного
сигналу
інформаційного
сигналу ![]() має нормальний закон
розподілу випадкових величин, тоді при збільшенні кількості спектральних
складових весь спектр прийме функцію щільності нормального закон розподілу. Це
підтверджується центральною граничною теоремою для значної кількості однаково
розподілених випадкових величин. Ґрунтуючись на визначення центральної граничної
теореми можна стверджувати, якщо
має нормальний закон
розподілу випадкових величин, тоді при збільшенні кількості спектральних
складових весь спектр прийме функцію щільності нормального закон розподілу. Це
підтверджується центральною граничною теоремою для значної кількості однаково
розподілених випадкових величин. Ґрунтуючись на визначення центральної граничної
теореми можна стверджувати, якщо ![]() - незалежні величини,
які мають один и той самий закон розподілу з математичним очікуванням
- незалежні величини,
які мають один и той самий закон розподілу з математичним очікуванням ![]() та
середньоквадратичним відхиленням
та
середньоквадратичним відхиленням ![]() , то при необмеженому збільшенні кількості складових
, то при необмеженому збільшенні кількості складових ![]() закон розподілу їх
суми необмежено приближується до нормального розподілу випадкових величин.
закон розподілу їх
суми необмежено приближується до нормального розподілу випадкових величин.
З огляду на
вище викладену формулу (3) та вище накладені умови, одержимо загальний Байесовський
вираз знаходження умовної ймовірності появи інформаційного сигналу, тобто відповідної
гіпотези ![]() при умові прийнятого
інформаційного сигналу
при умові прийнятого
інформаційного сигналу ![]() :
:
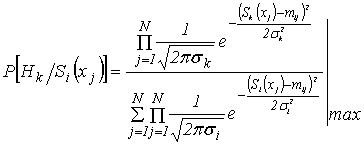 ,
(4)
,
(4)
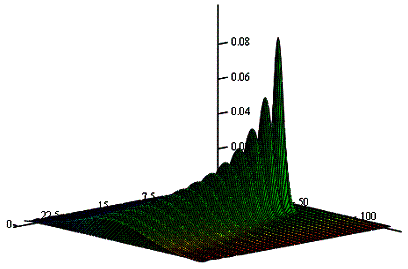
Рис. 1. Спектральне представлення слабо відмінних
кодових конструкцій з урахуванням введення двомірного математичного очікування
Для достовірної ідентифікації прийнятої
послідовності ![]() , можна
використати наступну математичну процедуру прийняття остаточного рішення:
, можна
використати наступну математичну процедуру прийняття остаточного рішення:
![]() , (5)
, (5)
Методика
оцінки точності правильної ідентифікації кодових конструкцій
Проведемо оцінку точності процедур відновлення та
ідентифікації на основі достатньої кількості інформації з умов забезпечення
достовірності і цілісності кодових конструкцій.
Для оцінки якості розробленого методу на базі
використання двохпараметричного математичного очікування, побудуємо графічні залежності ймовірності
правильної ідентифікації ![]() від співвідношення сигнал/шум
від співвідношення сигнал/шум ![]() .
.
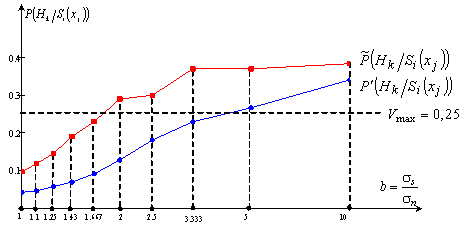
Рис.2
Залежність апостеріорної ймовірності правильної ідентифікації від співвідношення
сигнал/шум
З
отриманих аналітичних та графічних
залежностей апостеріорної ймовірності
правильної ідентифікації можна зробити наступні висновки, що кількісні значення
ймовірностей правильної ідентифікації для розробленого методу ![]() відновлення кодових слів, значно більші в порівнянні з
використанням стандартної процедури
відновлення кодових слів, значно більші в порівнянні з
використанням стандартної процедури ![]() , тобто
відбувається збільшення точності та достовірності ідентифікації від 1,14 до 2,7
разів. Видно, що при збільшенні
відношення сигнал/шум ймовірність правильної ідентифікації при використанні
двохпараметричного математичного очікування виграє по точності, що за собою
тягне збільшення достовірності ідентифікації (рис.2).
, тобто
відбувається збільшення точності та достовірності ідентифікації від 1,14 до 2,7
разів. Видно, що при збільшенні
відношення сигнал/шум ймовірність правильної ідентифікації при використанні
двохпараметричного математичного очікування виграє по точності, що за собою
тягне збільшення достовірності ідентифікації (рис.2).
Низький рівень
порогів правильної ідентифікації, пояснюється достатньо великою кількістю
альтернативних гіпотез кодових комбінацій (N=1024), а також присутністю в
зазначеному класі сигналів «слабо відмінних» кодових конструкцій. Однак, процес
математичного моделювання і використання процедур заснованих на достатній мірі
кількості інформації, показали адекватність цих методів до встановлених вимог
[1,2]. Зрозуміло, що процедура прийняття рішення сформована на основі двох
параметричного математичного очікування, більш результативна та використання
математичних очікувань спектральних складових для кожної з можливих гіпотез
більш інформативно. Введення функції двовимірного спектру дає змогу проводити
ідентифікацію при високому рівні шуму та невеликому рівні сигналу (коли шум
складає 50% від інформаційного сигналу), що зумовлює підвищення достовірності прийняття рішення.
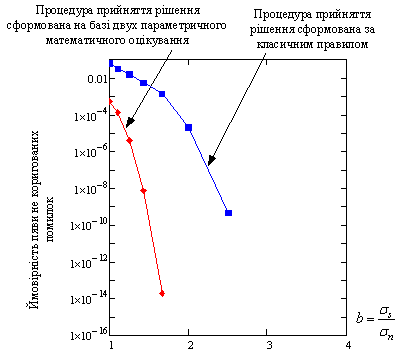
Рис.2 Ймовірності появи не коригованих помилок при ідентифікації кодового слова в залежності від співвідношення сигнал/шум
Також для оцінки точності та якості розробленого
методу відновлення кодових конструкцій у задачах декодування повної кодової
конструкції побудуємо графічні залежності ймовірності появи не коригованих
помилок в інформаційному потоці. На базі проведеного аналізу показано, що
використання в процедурі прийняття рішення двохпараметричного математичного
очікування дозволяє зменшити ймовірність появи не коригованих помилок та забезпечити
подальше усунення спотворень у інформаційному повідомленні при фіксованих
значеннях сигнал/шум ![]() .
.
Висновки
Проведені дослідження показали можливість
підвищення достовірності правильної ідентифікації кодового слова на базі мінімально-достатньої кількості
інформації в 1,14 до 2,7 разів. На
основі проведеного аналізу процедури прийняття рішення можна констатувати, що
використання двохпараметричного математичного очікування при розрахунках
умовної щільності розподілу спектру сигналу, замість усередненого стандартного
математичного очікування, підвищує точність ідентифікації з умов збільшення
міри кількості інформації. Проведено
оцінку ефективності нововведеного методу, на базі розрахунку аналітичних
залежностей ймовірності правильної ідентифікації та ймовірності появи не
коригованих помилок від співвідношення сигнал/шум ![]() . Показано, що кількісний рівень ймовірності порогів
правильної ідентифікації при використанні в процедурі прийняття рішення
двохпараметричного математичного очікування – достатні і відповідають
встановленим умовам відновлення слабо відмінних кодових слів.
. Показано, що кількісний рівень ймовірності порогів
правильної ідентифікації при використанні в процедурі прийняття рішення
двохпараметричного математичного очікування – достатні і відповідають
встановленим умовам відновлення слабо відмінних кодових слів.
Література
1.
Юдін О.К. Математичні аспекти використання багато альтернативних правил в
задачах канального кодування інформаційних потоків /Юдін О.К., Чунарьова А.В.
// Збірник наукових праць Інституту проблем моделювання в енергетиці ім. Г.Є.
Пухова. Вип.47-К.:ІПМЕ НАН України,
2008. – 25-31 с.
2.
Юдін О.К. Спектральні методи визначення інформативних складових в
процедурах усунення інформаційної невизначеності/ Юдін О.К., Чунарьова А.В.//Всеукраинский межведомственный научно-технический
сборник “Радиотехника“, вып. №159. Х.: ХНУРЭ, 2009. – С. 228-233.