Современные
информационные технологии/3. Программное обеспечение
д.ф-м.н. Калимолдаев
М.Н., д.т.н. Амиргалиев Е.А., к.т.н.
Мусабаев Р.Р., Мамырбаев О.Ж.
Институт проблемы
информатики и управления МОН РК, Казахстан.
Методы формирования словаря визем
для многомодального распознавания речи
Введение. Разработка средств
эффективного взаимодействия человека с компьютером сегодня является одним из
приоритетных направлений развития искусственного интеллекта и информатики в
целом. С развитием современных речевых технологий появилась принципиальная
возможность перехода от формальных языков-посредников между человеком и машиной
к естественному языку в устной форме, как универсальному средству выражения
целей и желаний человека. Речевая форма диалога обладает рядом преимуществ
таких, как естественность, оперативность, смысловая точность ввода,
освобождение рук и зрения пользователя, возможность управления и обработки в
экстремальных условиях.
Таким образом, существующие модели
автоматического понимания речи пока еще значительно уступают речевым
способностям человека, что свидетельствует об их недостаточной адекватности и
ограничивает применение речевых технологий в промышленности и быту. Для решения
глобальной проблемы человеко-машинного взаимодействия стали использовать
дополнительные виды каналов передачи информации (речь, артикуляция губ, жесты,
направление взгляда и т.д.). В результате начали разрабатывать так называемые
многомодальные методы распознавания речи. Такие методы распознавания
свойственны межчеловеческому общению. Здесь пользователь сам выбирает какой
канал, для передачи какого типа информации нам наиболее удобно использовать в
данный момент. Такие интерфейсы позволяют обеспечить наиболее эффективное и
естественное для человека взаимодействие с различными автоматизированными
средствами управления и коммуникации [1].
В многомодальных системах информация от
различных видео, аудио, тактильных коммуникативных каналов непрерывно
отслеживается и обрабатывается, создавая реальное или виртуальное окружение,
позволяющее удовлетворить желания пользователя и оперативно адаптироваться к
текущей задачей другим прикладным аспектам. Адаптивные многомодальные системы
позволят создавать новые многофункциональные устройства и обеспечат требуемую
гибкость использования персональных и мобильных систем.
В настоящее время за рубежом многомодальные
методы распознавания речи уже используются в некоторых прикладных областях:
картографических системах, системах виртуальной реальности, медицинских
системах, робототехнике, web-приложениях, ит. д.
Помимо этого многомодальные методы распознавания речи может быть полезен в
мобильных устройствах, где использование обычной клавиатуры невозможно. В
карманных персональных компьютерах сейчас используется системы распознавания
рукописного текста. Комбинирование таких систем с голосовым вводом позволит
обмениваться информацией с пользователем более эффективно. Также использование
многомодальные методы распознавания речи актуально в смартфонах (умный
телефонах), в которых в настоящее время возможен раздельный ввод с помощью
голоса, неэргономичной клавиатуры или сенсорного экрана. Оптимальное совместное
использование этих коммуникативных каналов позволит пользователю более
оперативно и надежно обмениваться информацией с такими устройствами [2].
Исследования, посвященные распознаванию речи,
лица, положения человека в окружающем пространстве, ведутся уже более полувека.
Однако системы объединяющие различные способы ввода информации в единой форме
стали разрабатываться совсем недавно. Такие методы распознавания и системы
получили название многомодальные (мультимодальные) методы распознавания речи.
Методы
многомодального распознавания речи. Многомодальные методы распознавания речи
обрабатывают два и более объединенных пользовательских вида ввода информации –
также как речь, письменный ввод, жесты руками, взгляд, движения головы и тела
совместно с мультимедийной системой ввода информации. Этот класс представляет
новое направление в информатике и концепцию отказа от традиционных WIMP
интерфейсов.
Люди используют ряд выходных модальностей (или
каналов) для коммуникации друг другом, а также с компьютерами. Компьютерные
входные модальности на данный момент ограничены достижениями технологий
распознавания. Компьютерная система предоставляет вывод информации
пользователю, выбирая одну или несколько сред вывода, которые человеческая
система ввода (или каналы) интерпретирует, основываясь на способностях
познания. Здесь «ввод» рассматривается как поток информации от человека к
компьютеру, а «вывод» от компьютера к человеку. Если мультимедийные системы
вывода информации известны и применяются уже давно (они используют
одновременный вывод звука, видео, анимации, синтез речи и т.д.), то
многомодальные системы ввода информации находится еще только в начале своего
развития.
Недавние успехи в обработке речи, компьютерном
зрении и композиции сцен (регистрация виртуальных объектов, трехмерные образы,
синтезированная речь и т.д.) позволяют сделать прорыв в области взаимодействия
человека с компьютером. Параллельно с цифровой обработкой сигналов активно
ведутся работы по изучению процессов мышления и коммуникации, как между людьми,
так и с машиной. Моделирование задач, построение диалоговых систем
осуществляется с учетом когнитивной психологии, эргономики. Это позволяет
выбирать оптимальные каналы взаимодействия и способы синхронизации различных
видов информации для ввода и вывода [3].
Многомодальное
человеко-машинное взаимодействие опирается на ряд принципов:
-
Пользователь
управляет компьютером, используя несколько физических устройств (клавиатура,
мышка, микрофон, видеокамера и т.д.).
-
Для
коммуникации с компьютером пользователь активизирует движение ряда своих мышц
(голосового тракта, рук, глаз, и т.д.).
-
Информация,
передаваемая компьютерными устройствами ввода, может быть обработана на
различных уровнях абстракции, обеспечивая различные уровни понимания намерения
пользователя.
-
Компьютер
взаимодействует с пользователем, используя несколько устройств вывода (дисплей,
динамики и т.д.).
-
По
этим устройствам вывода компьютер может передавать заранее подготовленные
данные (файл с изображениями, аудио файлы и т.д.) или же динамически
генерируемые данные (например, генерации текста, графики, синтеза речи и т.д.).
Таким образом, компьютерная система может использовать
несколько информационных каналов (чувств пользователя: зрение, слух, и др.) для
ввода и вывода [4].
Человек при восприятии речи еще использует и
дополнительные визуальные и тактильные способы получения информации. Рассмотрим
основные из них:
-
Чтение
по губам. Соответствует восприятию речи, когда доступна одна лишь визуальная
информация. Глухие люди полагаются только на эту информацию. Формы губ, позиция
языка и видимость зубов позволяют различать элементарные единицы визуальной
речи (виземы). Визуальная информация может компенсировать недостаток аудио
информации также в условиях окружающего шума.
-
Язык
глухонемых. Форма рук и положение рук позволяют общаться следующим образом.
Однако рука располагается близко к губам и изменяет свою форму синхронно с
произносимой речью. Форма руки определяет согласные звуки, в то время как
положение руки служит для уникального представления каждой фонемы. В отличие он
языка жестов, основанного на словах, этот язык основывается только на фонемах.
-
Язык
жестов. Форма рук, положение и ориентация рук, а также их движения является
элементами языка жестов. Движения тела и положение всех других частей тела по
отношению друг к другу также является дополнительными источниками информации и
используются для интерпретации жестов. Этот язык имеет собственную грамматику и
лингвистическую структуру. Выражение лица, направление взгляда и движения тела
также играют важную роль. Например, определенное выражение лица используется
для отрицания лексического элемента. Глаза и движения головы наоборот выражают
согласие. Например, кивок головы может быть сигналом для подчеркивания
актуальности глагольной конструкции, а также сигналом к принятию решения или
указания, что необходимо поставить скобки в предложении. Выражения лица,
означающие удивление, гнев или радость дополняют знаки руками.
Значительный
интерес уделяется многомодальным интерфейсам, которые объединяют различную
визуальную информацию, такую как направление взгляда человека, выражение лица,
жесты руками или частями тела. Эти технологии незаметно (пассивно) и постоянно
отслеживают поведение пользователя и не требуют подачи конкретных команд
компьютеру. В отличие от этих модальностей речевой ввод и световое перо
используют для выдачи определенных команд указывающих намерение пользователя,
поэтому такие модальности являются активными в ходе диалога.
Формирования словаря визем. Фонетическую систему языка образуют не только
сегментные средства, но и суперсегментные, которые накладываются на фонемную
(линейную) структуру речи. Если минимальные единицы звуковой системы языка –
фонемы (гласные, согласные), являющиеся элементами звуковой оболочки слов и
морфем, составляют сегментный уровень речевого звучания и определения
линейность речи, то вторую линию речевого звучания составляет суперсегментный
уровень, т. е. интонация. Интонационный (просодический) уровень имеет
достаточно сложное строение и выполняет весьма многообразные функции.
Просодические средства в каждом языке функционируют в виде тональных,
динамических и темпоральных модификаций и изменений одновременно с сегментами
речевого потока [5].
С. К. Кенесбаев подробно анализирует фонемный
состав, закон сингармонизма, звуковые изменения, слоговую структуру слов и
категорию акцентуации казахского языка. При анализе фонологической структуры
казахского слова казахский вокализм состоит из одиннадцати фонем: девяти
монофтонгов (а, ә, е, ө, о, ү, ұ, ы, і) и двух дифтонгоидов (и,
у). С. К. Кенесбаев подчёркивает восточное происхождение фонемы ә в
казахском языке и наличие нескольких согласных (в, х, ф, ч, щ) заимствованных
из русского языка (таблица 1.).
Таблица 1.
Виды гласных звуков (визем) казахского языка.
|
Виды гласных звуков |
|||||
|
По
участию губ |
Огубленные |
По
подъему языка |
|||
|
губные |
нелабиализованные |
открытые |
сжатые |
твердые |
мягкие |
|
О,
Ө, У, Ұ, Ү |
А,
Ә, Ы, І,(Э) |
А,
Ә, О, Ө, Е |
Ы,
І, (И), У, Ұ, Ү |
А,
О, (У), Ұ, (И) |
Ә,
Ө, Ү, І, Е, (И), (У) |
Классификация согласных проводится в трех
направлениях: по участию голоса и шума, по способу и месту образования. По
месту образования согласные делятся на восемь групп: губно-губные
(билабиальные) – п, б, м (у); зубно-губные (дентолабиальные) – ф, в; зубные
(дентальные) – т, с, з, д, ц; альвеолярные – н, л, ч; переднеязычные
(палатальные) – р, щ, ж, й; среднеязычные (препалатальные) – к, г; заднеязычные
(велярные) – қ, ғ, ң, х; гортанные
(фарингальные) – һ (таблица 2.).
Таблица
2. Виды согласных звуков (визем) казахского языка.
|
Виды согласных звуков |
||
|
Звонкие |
Глухие |
Сонорные |
|
б,в, г, ғ, д, ж, з |
к,қ,п,с,т,ф,х,ц,ч,ш,щ,һ |
й,р,л,м,н,ң,(у) |
Предварительный
анализ возможности автоматической классификации образов такого алфавита показал
необходимость его существенного сокращения в направлении использования базовых
или опорных визем [5, 6]. Поэтому для дальнейших исследований в направлении
разработки системы автоматического чтения с губ можно принять следующий рабочий
алфавит визем, за основу которого приняты опорные виземы (таблица 3.).
Таблица 3. Состав визем казахского языка.
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|
|
|
|
|
|
|
|
|
а |
ә |
ж,
ы,с,ң ц,ш,щ,и |
д,і,т,х,р,
л,н,з |
е,қ,һ |
ұ |
ү |
|
8 |
9 |
10 |
11 |
12 |
13 |
|
|
|
|
|
|
|
|
|
|
о |
ө,у |
б,п,м |
ч |
в,ф |
г,ғ,к |
|

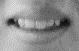


Как видно из таблицы 3, приведенные в ней
элементы алфавита визуально трудно – различимы с элементами рабочего алфавита,
что может существенно затруднить распознавание произнесенного звука по
изображению соответствующей конфигурации губ. Так виземы 3 и 5 визуально
трудноотличимы от 11 а виземы 8, 6 и 7 легко спутать как между собой принятого
рабочего алфавита.
Выводы. В статье приводится
концепция создания экспериментальной технологии многомодального распознавания
речи, которая явилась результатом всестороннего анализа современного состояния
проблемы автоматического чтения с губ. В целях выполнения рекомендации
международных экспертов по адаптации разработанных технологий для мобильных
устройств было разработано мобильное приложение «KazVoice» для операционных систем iOS
и Android на основе бесплатного open-source фреймворка PhoneGap. PhoneGap позволяет создавать приложения под все мобильные операционные системы
(iOS, Android, Bada и т. д.). Готовое приложение компилируется в виде
установочных пакетов для каждой мобильной операционной системы. В настоящий
момент через мобильное приложение «KazVoice» пользователь может получить доступ и опробовать
в тестовом режиме технологию распознавания речи на казахском языке. В будущем
планируется внедрить и другие сопутствующие технологии.
Литература:
1.
Ронжин
А.Л., Ли И.В. Автоматическое распознавание русской речи // Вестник Российской
Академии Наук, Том 77, вып.2, 2007, С.133-138.
2.
Ронжин
А.Л. Сравнительный анализ и оценка моделей словаря для систем распознавания
русской речи. // Информационные технологии, №1, 2009, С. 21-28.
3.
Сапожков
М.А. Речевой сигнал в кибернетике и связи. –М.: Связьидат, 1963. -452 с.
4.
Потапова
Р.К. Речь: коммуникация, информация, кибернетика. 2003. – 568 с.
5.
Базарбаева
З.М. Интонационные системы казахского языка.
А., 1996. -256
с.
6. Kalimoldayev M.N., Keylan A., Mamyrbayev O.J. Methods for applying VAD
in Kazakh speech recognition systems. // International journal of Speech
Technology. 14 December 2013.