Паскар В.В.
Буковинський державний фінансово-економічний університет,
Україна
Методики визначення якості рейтингових моделей оцінки кредитоспроможності
Постановка проблеми. Взяття Україною курсу на
поступове впровадження вимог «Міжнародної конвергенції вимірювання капіталу та
стандартів капіталу: нові підходи» («Базель ІІ») передбачає впровадження
багатьох реформ у вітчизняну банківську систему. Одним із положень,
передбачених даними рекомендаціями є необхідність застосування рейтингових
методик визначення кредитоспроможності позичальника на основі кількісного та
якісного аналізу його діяльності.
В умовах вітчизняної економіки доцільним і єдино можливим є визначення
рейтингів на основі підходу, що базується на внутрішніх рейтингах (IRB-підхід),
адже інститут рейтингових агентств розвинутий дуже слабко. Такий підхід
передбачає розробку банківськими установами власних моделей визначення
внутрішнього кредитного рейтингу позичальників.
Невід’ємним елементом впровадження будь-якої нової моделі оцінки
кредитоспроможності є визначення її ефективності, рейтингові моделі не є
винятком.
Аналіз останніх досліджень і
публікацій. Дослідженнями рейтингових моделей оцінки кредитоспроможності та пошуком
шляхів їх покращення займаються такі науковці, як: А. Гідулян Ю.Л. Логвиненко, О.О. Терещенко та ін.
[1],[2],[3]. Однак вітчизняних напрацювань безпосередньо в напрямку опису
методик перевірки якості рейтингових моделей дуже мало. Серед зарубіжних
науковців даному питанню приділяють увагу такі вчені, як: Б. Енгельман, Е. Хейден,
Д. Таше та Н. Паклин [4],[5].
Постановка завдання. Метою даної статті є
опис методів визначення якості рейтингових моделей оцінки кредитоспроможності
позичальників, що застосовуються в зарубіжній практиці. А також опис
авторського алгоритму оцінки точності поділу позичальників на рейтингові групи.
Виклад основного матеріалу. За своєю сутністю рейтингові
моделі оцінки кредитоспроможності у спрощеному вигляді є класифікаційними
моделями, які поділяють позичальників на дві групи: кредитоспроможних та некредитоспроможних.
Математичною основою таких моделей є бінарна логістична регресія.
Для аналізу якості моделей на основі логістичної регресії використовують
так-званий ROC-аналіз. Даний вид аналізу передбачає побудову ROC-кривої
-кривої, яка найчастіше використовується для представлення результатів бінарної
класифікації. ROC-крива показує залежність кількості вірно класифікованих
позитивних прикладів від кількості невірно класифікованих негативних прикладів.
У термінології ROC-аналізу перші називаються істинно позитивною, другі -
хибно негативною множиною. При цьому передбачається, що у класифікатора є
деякий параметр, варіюючи який, ми будемо отримувати те чи інше розбиття на два
класи. Цей параметр часто називають порогом, або точкою відсікання (cut-off value).
Розглянемо таблицю співвідношення результатів класифікації моделі з
реальними результатами (таблиця 1.1).
Таблиця 1.1
Співвідношення результатів класифікації моделі з реальними результатами
|
Класифікація на основі моделі |
Фактично |
|
|
Позитивно |
Негативно |
|
|
Позитивно |
TP |
FP |
|
Негативно |
FN |
TN |
TP (True Positives) – вірно класифіковані позитивні приклади (так-звані
істинно позитивні випадки);
TN (True Negatives) – вірно класифіковані негативні приклади (істинно
негативні випадки);
FN (False Negatives) – позитивні приклади, класифіковані як негативні
(помилка І роду). Це так-званий «хибний пропуск» - коли подія, яка нас цікавить
помилково не виявляється (хибно негативні приклади);
FP (False Positives) – негативні, приклади, класифіковані як позитивні
(помилка ІІ роду). Це хибне виявлення, оскільки при відсутності події помилково
виноситься рішення про її наявність (хибно позитивні випадки) [5].
Що відноситься до позитивних, а що до негативних прикладів – залежить від
конкретно поставленої задачі. Наприклад, якщо прогнозується вірогідність
дефолту, то позитивним випадком буде факт настання дефолту. А якщо
прогнозується імовірність повернення кредиту, то факт настання дефолту буде
негативним випадком, а позитивним – вчасне погашення зобов’язань боржником.
Введемо ще два визначення: чутливість та специфічність моделі. Ними
визначається об'єктивна цінність будь-якого бінарного класифікатора.
Чутливість (Sensitivity) – це і є частка істинно позитивних випадків:

Специфічність (Specificity) - частка істинно негативних випадків, які були
правильно ідентифіковані моделлю:

Модель з високою чутливістю часто дає істинний результат при наявності
позитивного результату (виявляє позитивні приклади). І навпаки, модель з
високою специфічністю частіше дає істинний результат при наявності негативного
результату (виявляє негативні приклади).
Якщо розглядати модель, завданням якої є визначення можливості повернення
боргу вчасно, то можна сказати, що чутлива модель зорієнтована на максимальне
виявлення кредитоспроможних контрагентів (при цьому до класу кредитоспроможних
потраплять практично всі кредитоспроможні і частина з тих, у кого висока
імовірність дефолту). Специфічна модель в даному випадку зорієнтована на
точність виявлення тих позичальників, що зазнають дефолту. Тобто буде виявлено
практично всіх некредитоспроможних позичальників, і до цього класу потрапить
якась частина контрагентів, які потенційно могли б успішно погасити
заборгованість.
ROC-крива будується наступним чином:
1. Для кожного значення порога відсікання, яке змінюється від 0 до 1 з
кроком dx (наприклад, 0,01) розраховуються значення чутливості Se і
специфічності Sp. В якості альтернативи порогом може бути кожне наступне
значення прикладу у вибірці.
2. Будується графік залежності: по осі Y відкладається чутливість Se, по
осі X - 100%-Sp (сто відсотків мінус специфічність) - частка хибно позитивних
випадків. В результаті отримуємо деяку криву (рис. 1.1) [5].
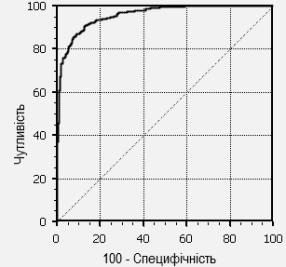
Рис. 1.1 ROC-крива
Для ідеального класифікатора графік ROC-кривої проходить через верхній
лівий кут, де частка істинно позитивних випадків становить 100% або 1.0
(ідеальна чутливість), а частка хибно позитивних випадків дорівнює нулю. Тому
чим ближче крива до верхнього лівого кута, тим вище передбачувальна здатність
моделі. І навпаки: чим менше вигин кривої і чим ближче вона розташована до
діагональної прямої, тим менш ефективною є модель. Діагональна лінія відповідає
повністю непридатному класифікатору, який розрізняє події на класи випадковим
чином.
При візуальній оцінці ROC-кривих розташування їх відносно один одного
вказує на їх порівняльну ефективність. Крива, розташована вище і лівіше,
свідчить про більшу передбачувальну здатність моделі.
Візуальне порівняння кривих ROC не завжди дозволяє виявити найбільш
ефективну модель. Своєрідним методом порівняння ROC-кривих є оцінка площі під
кривими (рис. 1.2). Теоретично вона змінюється від 0 до 1,0, але, оскільки
модель завжди характеризуються кривою, розташованої вище позитивної діагоналі,
то зазвичай говорять про зміни від 0,5 (абсолютно неефективний класифікатор) до
1,0 («ідеальна» модель).
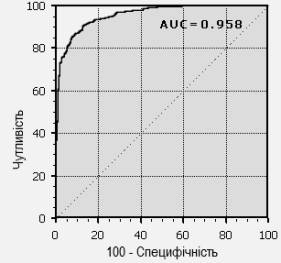
Рис. 1.2 Оцінка площі під ROC-кривою
Ця оцінка може бути отримана безпосередньо обчисленням площі під багатогранником,
обмеженим праворуч і знизу осями координат і зліва вгорі - експериментально
отриманими точками. Чисельний показник площі під кривою називається AUC (Area
Under Curve). Обчислити його можна, наприклад, за допомогою чисельного методу
трапецій:
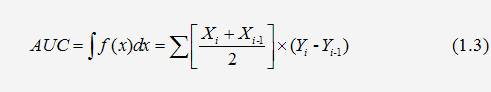
Можна вважати, що чим більше показник AUC, тим кращою прогностичною силою
володіє модель. Однак варто знати, що:
- показник AUC призначений скоріше для порівняльного аналізу декількох
моделей;
- AUC не містить ніякої інформації про чутливість і специфічність моделі.
У літературі іноді наводиться така експертна шкала для значень AUC, за якою
можна судити про якість моделі (табл. 1.2)
Таблиця 1.2
Експертна шкала для значень AUC
|
Інтервал AUC |
Якість моделі |
|
0,9-1,0 |
Відмінна |
|
0,8-0,9 |
Дуже добра |
|
0,7-0,8 |
Добра |
|
0,6-0,7 |
Задовільна |
|
0,5-0,6 |
Незадовільна |
Ідеальна модель володіє 100% чутливістю і специфічністю. Однак на практиці
досягти цього неможливо, більше того, неможливо одночасно підвищити і
чутливість, і специфічність моделі. Компроміс знаходиться за допомогою порогу
відсікання, оскільки порогове значення впливає на співвідношення Se і Sp [5].
Іншим методом оцінки якості моделей кредитоспроможності, який досить часто
використовується у зарубіжній практиці є оцінка профілю акумулювання точності
(Cumulative accuracy profiles) або CAP-аналіз. Його методологічна база має
багато спільного із ROC-аналізом, концептуальна відмінність полягає лише у
методиці визначенні коефіцієнта, за допомогою інтерпретації якого визначається
точність моделі.
Б.Енгельман, Е.Хайден та Д.Таше провели детальний порівняльний аналіз,
висновком якого стало твердження про еквівалентність оцінок кредитної моделі
отриманої за результатами ROC та CAP аналізу [4, 86].
ROC-аналіз та CAP-аналіз придатні для оцінки моделей побудованих на основі
логістичної регресії, і оцінюють лише класифікацію контрагентів на фінансово
здорових і потенційних банкрутів. Однак рейтингові моделі передбачають поділ
потенційно кредитоспроможних позичальників на кілька груп (5-7) за рівнем
імовірності дефолту. Тому можемо запропонувати власну методику визначення
точності поділу кредитоспроможних позичальників за групами кредитного ризику у
рейтинговій моделі оцінки кредитоспроможності.
Як відомо у західній практиці рейтинговим групам присвоюються рівні
імовірності дефолту позичальника. Такі рівні, як правило, встановлюються у
вигляді діапазону, наприклад: від 3,01% до 6,0%. Імовірність дефолту
позичальника на рівні 50% означає, що кожен другий позичальник, якому присвоєно
такий рівень збанкрутує.
Отже, якщо зі 100 позичальників із таким рівнем імовірності дефолту,
присвоєного за результатами оцінки кредитоспроможності за певною моделлю,
збанкрутувало 70 позичальників – то можна зробити висновок, що дана модель має
неточності.
Тому можемо запропонувати наступний алгоритм оцінки точності поділу
позичальників на рейтингові групи:
1. Із великої статистичної вибірки позичальників, оцінених за відповідною
моделлю оцінки кредитоспроможності визначити питому вагу позичальників що
зазнали дефолту по кожній рейтинговій групі.
2. Визначити відхилення фактичних дефолтів по рейтингових групах за
наступним алгоритмом:
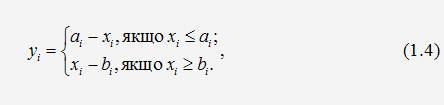
Де: yi – відхилення фактичних дефолтів від прогнозованих у і-й
рейтинговій групі;
xi - питома вага позичальників що зазнали дефолту у і-й
рейтинговій групі;
ai – нижня межа діапазону імовірності дефолту у і-й рейтинговій
групі;
bi – верхня межа діапазону імовірності дефолту у і-й рейтинговій
групі.
3. Знайти суму усіх «yi», зважених на питому вагу кількості
позичальників у групах від загальної кількості проаналізованих позичальників (у
коефіцієнтному вигляді). Тобто, якщо із 100 проаналізованих позичальників у 1
групу кредитного рейтингу потрапило 10 контрагентів, то значення у1
при знаходженні загальної суми потрібно буде помножити на 0,1.
Оскільки значення xi, ai, та bi –
є відсотковими, а питома вага по групах виражена у коефіцієнтному значенні, то
результуючий показник буде у відсотковому вираженні, і його значення може
змінюватися від 0% до 100%. Відповідно чим ближчим значення даного показника
буде до нуля – тим точнішою є аналізована кредитна модель.
Оскільки дана методика оцінює лише точність класифікації кредитоспроможних
позичальників, то вона може доповнювати західні методики аналізу бінарних
класифікаторів.
Висновки. Невід’ємним елементом
побудови моделі оцінки кредитоспроможності є оцінка якості такої моделі. У
зарубіжній літературі для оцінки моделей побудованих на базі логістичної
регресії використовують ROC-аналіз та CAP-аналіз, які є досить близькими за
своєю методологією.
Ці види аналізу передбачають оцінку якості бінарних класифікаторів і можуть
використовуватися для оцінки скорингових та дискримінантних моделей оцінки
фінансово-господарського стану позичальника. Однак рейтингова оцінка
кредитоспроможності передбачає поділ позичальників на більшу, ніж дві кількість
груп. Тому нами була запропонована методика оцінки якості класифікації
кредитоспроможних позичальників у відповідності до імовірності дефолту, яка
може доповнювати ROC-аналіз чи CAP-аналіз.
Література:
1.
Гідулян А. Актуальні питання поліпшення методики оцінки кредитоспроможності
позичальників банками України / А. Гідулян // Вісник НБУ. - січень 2012. - С.
50-53.
2.
Логвиненко Ю.Л. Сутність рейтингування підприємств та його значення в
ринкових умовах / Ю. Л. Логвиненко // Проблеми економіки та управління. - Львів
: Вид-во Нац. університету "Львівська політехніка", 2009. - №640. -
С. 319-327.
3.
Терещенко О.О. Нові підходи до оцінки кредитоспроможності
позичальників – юридичних осіб / О.О. Терещенко // Вісник НБУ. – січень
2012. – С. 26-30.
4.
Engelmann B. Testing rating accuracy / B. Engelmann, E. Hayden, D. Tasche
// Risk magazine. - january 2003. - P. 82-86.
5.
Паклин Н. Логистическая регрессия и ROC-анализ - математический апарат [Електронний
ресурс] / Н. Паклин - Режим доступу : http://www.basegroup.ru/library/analysis/regression/logistic/.