Скорин Р.А.
студент 4 курса , спец. ВТиПО
Научный руководитель: старший преподаватель Неверова Е.Г.
Казахский
Экономический Университет им. Т. Рыскулова,
Республика Казахстан, г.Алматы
Распознавание
образов с использованием нейронной сети
Искусственные нейронные сети прочно вошли в нашу
жизнь и в настоящее время и активно применяются там, где обычные
алгоритмические решения оказываются неэффективными или вовсе невозможными. В
числе задач, решение которых доверяют искусственным нейронным сетям, можно
назвать распознавание текстов. Описываемая в статье задача относится к одному
из научных направлений, называемых OCR
(англ. optical character
recognition) - оптическому распознаванию символов.
Согласно Википедии [1] – «Распознавание широко используется для конвертации
книг и документов в электронный вид, для автоматизации систем учёта в бизнесе или для публикации текста на веб-странице. Оптическое распознавание текста
позволяет редактировать текст, осуществлять поиск слова или фразы, хранить его
в более компактной форме, демонстрировать или распечатывать материал, не теряя
качества, анализировать информацию, а также применять к тексту электронный перевод, форматирование или преобразование в речь. Оптическое распознавание
текста является исследуемой проблемой в областях распознавания образов, искусственного интеллекта и компьютерного зрения.»
Существует два разных подхода к решению данной
проблемы: использовать нейронную сеть или использовать векторную модель. Векторная модель (англ. vector space
model) в информационном поиске — представление коллекции документов векторами
из одного общего для всей коллекции векторного пространства. Векторная модель
лежит в основе задач информационного поиска, как то: поиск документа по
запросу, классификация, кластеризация и
т д. Документ в векторной модели рассматривается как неупорядоченное множество
термов. Термами в информационном поиске называют слова, из которых состоит
текст, либо цветной пиксель из которого состоит изображение [2].
Нейронная сеть – сеть, состоящая из
искусственных нейронов, у каждого из которых имеется свой вес. Искусственный
нейрон имитирует свойства биологического нейрона. На вход искусственного
нейрона поступает некоторое множество сигналов. Каждый вход умножается на
соответствующий вес, и все произведения суммируются, определяя уровень
активации нейрона. Хотя сетевые парадигмы весьма разнообразны, в их основе
лежит эта конфигурация.
Создание нейронных сетей было вызвано попытками
понять принципы работы человеческого мозга. Однако, в сравнении с человеческим
мозгом нейронная сеть - весьма упрощенная модель. Хотя решение на основе
нейронных сетей может выглядеть и вести себя как обычное программное
обеспечение, они различны в принципе, поскольку большинство реализаций на
основе нейронных сетей «обучается», а «не заранее программируется», то есть
сеть учится выполнять задачу [3], в отличие от векторной модели, которая может
распознавать лишь заранее предопределенные элементы.
Простейшая сеть состоит из группы нейронов,
образующих слой, как показано на рисунке 1.
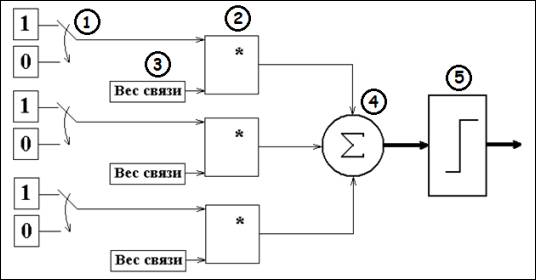
Рисунок 1 - простейшая сеть из 3-х
нейронов*
* П р и м е ч а н и е : рисунок разработан автором
Хотя один нейрон и способен выполнять простейшие
процедуры распознавания, весь потенциал можно выявить только объединяя их в
нейронную сеть.
Вычисляющие нейроны обозначаются квадратами (2).
Каждый элемент из множества входов (1) отдельным весом (3) соединен с каждым
искусственным нейроном. А каждый нейрон выдает взвешенную сумму (4) входов в
сеть (5). В искусственных и биологических сетях многие соединения могут
отсутствовать, все соединения показаны в целях общности. Могут иметь место
также соединения между выходами и входами элементов в слое.
Среди всех интересных свойств искусственных
нейронных сетей ни одно не захватывает так воображение, как их способность к
обучению. Обучение нейронных сетей напоминает процесс интеллектуального
развития человеческой личности. Но возможности обучения искусственных нейронных
сетей ограничены. Цель обучения - чтобы
для некоторого множества входов давать желаемое (или, по крайней мере,
сообразное с ним) множество выходов. Каждое такое входное (или выходное) множество
рассматривается как вектор. Обучение осуществляется путем последовательного
предъявления входных векторов с одновременной подстройкой весов в соответствии
с определенной процедурой. В процессе обучения веса сети постепенно становятся
такими, чтобы каждый входной вектор вырабатывал выходной вектор.
В своей реализации мы будем использовать
нейронную сеть. Исходный текст писался на Python (релиз: 3.3.5, автор:
Гвидо ван Россум, тип исполнения: интерпретируемый, компилируемый в байт-код Java)
[4].
Входной информацией является электронное
изображение любого графического формата - jpg, jpeg,
png, bmp, gif.
Способ его получения (было ли оно отсканировано, сфотографировано, сделано скриншотом или написано от руки в
графическом редакторе) для рассматриваемой задачи несущественен.
Заведомо мы усложняем задачу и берем изображение
низкого качества с шумами на заднем фоне, и помехами на переднем плане (см
рисунок 2). Такие изображения называют «капчами».
CAPTCHA (от англ. Completely Automated Public
Turing test to tell Computers and Humans Apart — полностью автоматизированный
публичный тест Тьюринга для различения компьютеров и людей) — компьютерный
тест, используемый для того, чтобы определить, кем является пользователь
системы: человеком или компьютером. Основная идея теста: предложить
пользователю такую задачу, которую с лёгкостью может решить человек, но которую
несоизмеримо сложнее решить компьютеру. [5]

Рисунок 2 – «капча»*
*П р и м е ч а н и е изображение взято с системы
авторизации google.com
Выходной информацией является электронный вариант текста пригодного для редактирования
и корректирования. В данном случае у нас ожидается на выходе форматируемый
текст – 759T9J. После запуска скрипта экспертной системы и
получения аргумента командной строки начинается загрузка изображения и его
анализ, показанный на рисунке 3.

Рисунок 3 – палитра цветов исходного
изображения*
*П р и м е ч а н и е: скриншот текущего
выполнения программы
Для демонстрации параллельно будем отображать
папку кэша (англ. cache) — промежуточного буфера с быстрым доступом,
содержащего информацию, которая может быть запрошена с наибольшей вероятностью
[5]. В данный момент папка КЭШа пуста.
После анализа цветовой панели на экран выводится
10 самых используемых цветов анализируемого изображения, а также автоматически
определяется цвет текста, как видно из рисунка 4.

Рисунок 4 –отображение процедуры
определения ID цвета текста*
*П р и м е ч а н и е: скриншот текущего
выполнения программы
Далее следует процедура сохранения «фикса».
«Фиксом» в данном случае мы называем изображение после «очистки» и цветовой
корректировки. С изображения удаляется фоновый шум и помехи переднего
плана. Также меняется цвет текста на
черный и сохраняется двухбитовое изображение (см рисунок 5 и рисунок 6).
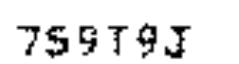
Рисунок 6 – Изображение после фикса.*
*П р и м е ч а н и е: скриншот текущего
состояния изображения

Рисунок 7 – процедура определения границ
символов.*
*П р и м е ч а н и е: скриншот текущего
выполнения программы
В КЭШе находится только
изображение фикса. Когда получен массив символов, программа «разрезает» картинку
на несколько мелких изображений (количество зависит от числа символов, по
одному на каждый символ). В КЭШе
появляется несколько следующих изображений (см рисунок 8):

Рисунок 8 – содержимое папки КЭШ после процедуры
«разрезания»*
*П р и м е ч а н и е: рисунок разработан
автором
У каждого изображения уникальное имя, которое
дается ему относительно текущей даты и
времени.
Следующая
процедура сравнивает каждое изображение с базой уже известных ему символов, сравнивает
веса каждого бита изображения и выносит вердикт, а так же говорит вероятности
уверенности в точности этого символа в
диапазоне от 0 до 1 (см рисунок 9).

Рисунок 9 – последняя процедура,
выводящая результат.*
*П р и м е ч а н и е: скриншот текущего
выполнения программы
Процедура распознавания включает алгоритм из
нескольких последовательных шагов, первым из которых является преобразование
изображения из любого формата в формат
GIF (англ. Graphics Interchange Format — «формат для обмена
изображениями») — «… популярный формат графических изображений. Способен хранить сжатые данные без потери
качества в формате не более 256 цветов. Не зависящий от аппаратного обеспечения
формат GIF был разработан в 1987 году (GIF87a) фирмой CompuServe для передачи
растровых изображений по сетям. В 1989-м формат был модифицирован (GIF89a),
были добавлены поддержка прозрачности и анимации. GIF использует
LZW-компрессию, что позволяет сжимать файлы, в которых много однородных заливок
(логотипы, надписи, схемы)» [5] Это
преобразование позволяет, во-первых, масштабировать текст по пикселям, во
вторых увидеть гистограмму цветов. Во время этой процедуры вы можете увидеть, что
белый цвет (255, самый последний в списке) встречается чаще всего, из этого
алгоритм делает вывод, что это цвет фона. Как только мы получили эту
информацию, мы создаем новые изображения, основанные на этих цветовых группах.
Для каждого из наиболее распространенных цветов
мы создаем новое бинарное изображение (из 2 цветов), где пиксели этого цвета
заполняются черным цветом, а все остальное - белым.
Далее у нас следует процедура, которая открывает
капчу, преобразует ее в GIF, создает новое изображение такого же размера с
белым фоном, а затем обходит оригинальное изображение в поисках нужного нам
цвета. Если он находит пиксель с нужным нам цветом, то он отмечает этот же
пиксель на втором изображении черным цветом.
Перед завершением работы второе изображение
сохраняется. Таким образом, на данный момент мы успешно извлекли текст из
изображения.
Инновация предлагаемой технологии распознавания
образов заключается в фильтрации переднепланового и заднепланового шума, а
также автоматическом определении цвета фона и цвета текста и, как
следствие, распознавание нечитаемых
символов.
Список используемой литературы:
1.Википедия
// [Электронный ресурс] - режим доступа:
http://ru.wikipedia.org/wiki/ Оптическое_распознавание_символов, [дата
обращения 15.04.2014]
2.Википедия
// [Электронный ресурс] - режим доступа:
http://ru.wikipedia.org/wiki/
Векторная_модель, [дата обращения 15.04.2014]
3. Портал искусственного интеллекта.
Актуальность нейронных сетей. Статья.// [Электронный ресурс] - режим
доступа: http://www.aiportal.ru/articles/neural-networks/actuality.html, [дата
обращения 15.04.2014]
4.Википедия
// [Электронный ресурс] - режим доступа: http://ru.wikipedia.org/wiki/Python,
[дата обращения 15.04.2014]
5.Борковский
А. Б. Англо-русский словарь по программированию и информатике (с толкованиями).
— М.: Русский язык, 2004. — 360 с.)