МАТЕМАТИКА
/ 4.Прикладная математика
Стрюков Р.К.
Воронежский Государственный Университет,
Россия
Сходство на основе
нечеткого моделирования
Пусть каждый объект ![]() в нашей
предметной области представлен N-мерным вектором, т.е.
в нашей
предметной области представлен N-мерным вектором, т.е.
![]()
таким
образом,
что![]() это i-ый
признак
это i-ый
признак ![]() . Признаки могут быть из любой области
. Признаки могут быть из любой области ![]() т.е.
т.е.![]() . Например, признаки могут быть целые числа,
вещественные числа и символы из некоторого дискретного набора
значений. Область признаков i
может отличаться от области признаков j.
Также допустимо, что значение признака
не определено или отсутствует [1].
. Например, признаки могут быть целые числа,
вещественные числа и символы из некоторого дискретного набора
значений. Область признаков i
может отличаться от области признаков j.
Также допустимо, что значение признака
не определено или отсутствует [1].
Пусть ![]() обозначает множество рассматриваемых объектов, такие,
что объекты,
обозначает множество рассматриваемых объектов, такие,
что объекты, ![]() ,
, ![]() . Например,
. Например, ![]() может
представлять некоторый неизвестный объект, личность которого устанавливается, в
то время как
может
представлять некоторый неизвестный объект, личность которого устанавливается, в
то время как ![]() принадлежит к
базе данных известных объектов. В этой статье рассматривается мера сходства,
которая основывается на расстоянии объектов
принадлежит к
базе данных известных объектов. В этой статье рассматривается мера сходства,
которая основывается на расстоянии объектов ![]() и
и ![]() , и особенностей объекта
, и особенностей объекта ![]() и
и ![]() . Чем меньше расстояние между объектами, тем больше их
сходство и наоборот. Для того, чтобы измерить расстояние между парой признаков,
. Чем меньше расстояние между объектами, тем больше их
сходство и наоборот. Для того, чтобы измерить расстояние между парой признаков,
![]() и
и ![]() ,
, ![]() , введем нечеткие лингвистические переменные расстояния
i-го компонента
, введем нечеткие лингвистические переменные расстояния
i-го компонента ![]() . Эта нечеткая лингвистическая переменная состоит из
нескольких нечетких множеств
. Эта нечеткая лингвистическая переменная состоит из
нескольких нечетких множеств ![]() , которые определены на
, которые определены на ![]() . Всякий раз, когда
. Всякий раз, когда ![]() и
и ![]() не определены,
все
не определены,
все ![]() не определены
также.
не определены
также.
В общем случае, нечеткие
множества ![]() , которые представляют расстояние i-й функции, будет
отличаться от нечетких множеств, представляющих расстояние j-й функции, в зависимости от характера функций [2]. Другими словами,
, которые представляют расстояние i-й функции, будет
отличаться от нечетких множеств, представляющих расстояние j-й функции, в зависимости от характера функций [2]. Другими словами,![]()
По определению, для каждого ![]() , предполагаем, упорядочение
, предполагаем, упорядочение
![]()
на нечетких множествах, такое, что расстояние признака i, соответствующее нечеткому множеству ![]() соответствует большее расстояние, чем
нечеткому множеству
соответствует большее расстояние, чем
нечеткому множеству ![]() ,
, ![]() . Формально для каждой пары нечетких
множеств
. Формально для каждой пары нечетких
множеств ![]() и
и ![]() ,
, ![]() , требуем существование разбиения
, требуем существование разбиения ![]() на два непересекающихся
подмножества
на два непересекающихся
подмножества ![]() и
и ![]() таких, что
выполнены следующие условия:
таких, что
выполнены следующие условия:
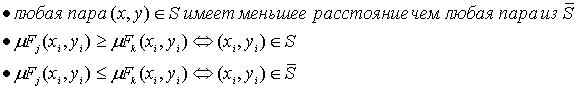
Кроме того, требуем,
чтобы ![]() достигало
своего максимального значения, если
достигало
своего максимального значения, если ![]() и
и ![]() идентичны, т.е.
идентичны, т.е.
![]()
Для некоторых приложений
требуется выполнение ![]() ,
,
![]()
Для
моделирования глобального сходства объектов, вводим нечеткую
лингвистическую переменную расстояние
объектов ![]() и
и ![]() , или
, или ![]() для краткости
[3].
для краткости
[3]. ![]() состоит из
нескольких нечетких множеств
состоит из
нескольких нечетких множеств![]() , определенных на интервале [0,1]. Пусть
, определенных на интервале [0,1]. Пусть ![]() обозначим базовую переменную лингвистической переменной
обозначим базовую переменную лингвистической переменной ![]() . Функции принадлежности нечетких множеств
. Функции принадлежности нечетких множеств ![]() имеют вид
имеют вид
![]()
Аналогично![]() , предполагаем, упорядочение на
, предполагаем, упорядочение на ![]()
![]()
таким образом, что ![]() представляет
собой большее расстояние между
представляет
собой большее расстояние между ![]() и
и ![]() , чем
, чем![]() ,
,![]() . Формально, требуем для каждой пары нечетких множеств
. Формально, требуем для каждой пары нечетких множеств ![]() и
и![]() ,
, ![]() существование
вещественного числа,
существование
вещественного числа, ![]() , которое делит диапазон [0, 1] базовой переменной u на два интервала [0, I] и [I, 1], такое что
, которое делит диапазон [0, 1] базовой переменной u на два интервала [0, I] и [I, 1], такое что
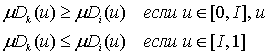
Чем меньше значение ![]() , тем меньше расстояние между
, тем меньше расстояние между ![]() и
и ![]() . Случаи
. Случаи ![]() и
и ![]() , представляют собой наименьшее и наибольшее возможные
расстояния (т.е. наибольшую и наименьшую степени сходства), соответственно.
Аналогично, требуем
, представляют собой наименьшее и наибольшее возможные
расстояния (т.е. наибольшую и наименьшую степени сходства), соответственно.
Аналогично, требуем
![]()
С учетом лингвистических
переменных ![]() и
и ![]() , расстояние между векторами
, расстояние между векторами ![]() и
и ![]() , определяется с помощью правил [4]. Общий формат
правила
, определяется с помощью правил [4]. Общий формат
правила
если сходство ![]() признака есть
признака есть ![]() и/или
и/или
сходство ![]() признака есть
признака есть ![]() и/или
и/или
…
сходство ![]() признака есть
признака есть ![]()
То сходство ![]() и
и ![]() есть
есть ![]()
или, более формально
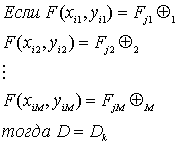
где каждый ![]() обозначает либо 'и' или 'или' связку.
обозначает либо 'и' или 'или' связку.
Правила такого вида обеспечивают очень гибкую модель и позволяют эксперту,
выразить свои знания о некоторой предметной области.
После определения
сходства двух признаков, могут быть использованы стандартные методы вывода, для
того чтобы сделать заключение о схожести двух заданных объектов ![]() и
и ![]() .
.
Литература:
1.
A. Kandel. Fuzzy Mathematical
Techniques with Applications.-Addison Wesley, 1986.
2.
Малышев
Н.Г. Нечеткие модели для экспертных систем в САПР / Малышев Н.Г., Берштейн
Л.С., Боженюк А.В. –М.: Энергоатомиздат, 1991
3.
Кофман
А. Введение в теорию нечетких множеств: Пер. с франц.–М.: Радио и связь, 1982.
4.
Татаркин
Д.С. Математическое и программное обеспечение механизма логического вывода в
нечетких продукционных системах. -Воронеж. 2007.