Современные
информационные технологии/Вычислительная техника и программирование
Мясіщев О.А., Рогоза Я.А.
Хмельницький національний
університет, Україна
Порівняння продуктивності обчислень лінійної алгебри на CPU та GPU.
Особливістю
розвитку сучасних обчислювальних систем є пошук різних шляхів збільшення
продуктивності обчислень не шляхом нарощування потужності окремих компонентів
системи, а використання технологій паралельної обробки інформації. Тактові
частоти сучасних процесорів настільки великі, що нарощувати їх далі не дозволяє
особливості технологічної конструкції мікропроцесорних пристроїв. Подальшим
кроком у розвитку мікропроцесорів була побудова пристроїв на основі декількох
обчислювальних ядер. Такий підхід дав змогу забезпечити фізичну паралельність
виконання задач, але теоретичного приросту у швидкодії він не дав, оскільки
продовжує використовуватися відносно повільна оперативна пам’ять для обміну і
синхронізації даних.
Найпоширенішою
сучасною задачею, яка потребує великої швидкості обчислень і обміну даними є
тривимірна графіка. Історично склалося так, що саме графіка є одним із основних
рушійних елементів для подальшого вдосконалення обчислювальних систем. Тому,
графічні системи розвиваються дещо швидше від інших комп’ютерних комплектуючих,
використовуючи у своїй основі найновіші технологічні рішення та досягнення.
Саме тому, компанією-виробником графічних адаптерів, фірмою NVIDIA, був
запропонований підхід, суть якого лежить у використанні графічних підсистем для
проведення різних обчислень, які раніше проводилися лише при використанні
центрального процесора і ОЗП.
Теоретично –
використанні графічних підсистем може дати значний приріст при проведенні
різних видів обчислень, оскільки графічний процесор використовує
модульно-багатоядерний принцип у своїй роботі, працюючи при цьому із власним
швидким оперативним запам’ятовуючим пристроєм. Тому, задачі, для яких
паралельність виконання дає змогу значно підвищити продуктивність роботи,
актуально вирішувати саме на графічних підсистемах. В свою чергу, потужним
графічним адаптером обладнаний майже кожен сучасний комп’ютер.
Технологія
CUDA — це середовище розробки компанії NVIDIA, яка дозволяє програмістам і
розробникам писати програмне забезпечення для вирішення складних обчислювальних
завдань за менший час завдяки багатоядерній обчислювальній потужності графічних
процесорів. Простіше кажучи, графічна підсистема комп'ютера з підтримкою CUDA
може бути використана, як обчислювальна.
Така операція
як перемноження матриць є складовою багатьох задач, які виконуються при різних
складних розрахунках. Наприклад, для вирішення лінійних рівнянь, для
організації руху полігонів при реалізації растрового зображення, для обчислення
характеристик взаємодії металу з формою при його плавці тощо. Тому, метою
подальшого дослідження є перевірка ефективності використання обчислень на
графічному адаптері для процесу перемноження двох квадратних матриць. Для цього
спочатку необхідно розглянути різницю між структурою та процесом обчислення на
CPU та GPU.
Робота GPU
полягає в прийнятті групи полігонів з однієї сторони й генерації групи пікселів
з іншої. Полігони й пікселі незалежні друг від друга, тому їх можна обробляти
паралельно. Таким чином, в GPU можна виділити велику частину кристала на
обчислювальні блоки, які, на відміну від CPU, будуть реально використовуватися.
GPU
відрізняється від CPU не тільки цим. Доступ до пам'яті в GPU дуже зв'язаний -
якщо зчитується тексель, то через кілька тактів буде зчитуватися сусідній
тексель; коли записується піксель, те через кілька тактів буде записуватися
сусідній. Розумно організовуючи пам'ять, можна одержати продуктивність, близьку
до теоретичної пропускної здатності. Це означає, що GPU, на відміну від CPU, не
потрібно величезного кешу, оскільки його роль полягає в прискоренні операцій текстурування.
Усе, що потрібно, це декілька кілобайт, що містять декілька текселів,
використовуваних у білінійних і трилінійних фільтрах.
До основних
елементів, з якими працює GPU, відносяться наступні:
Потік
(stream) являє собою потік елементів одного типу, в GPU він може бути
представлений текстурою. В принципі, у класичному програмуванні є такий аналог,
як масив.
Ядро (kernel)
- функція, яка буде застосовуватися незалежно до кожного елемента потоку; є
еквівалентом піксельного шейдера. У класичному програмуванні можна привести
аналогію циклу - він застосовується до великої кількості елементів.
Щоб зчитувати
результати застосування ядра до потоку, повинна бути створена текстура. На CPU
еквівалента немає, оскільки там є повний доступ до пам'яті.
Керування місцем
розташування в пам'яті, куди буде проводитися запис (в операціях
розкиду/scatter), здійснюється через вершинний шейдер, оскільки піксельний
шейдер не може змінювати координати оброблюваного пікселя.
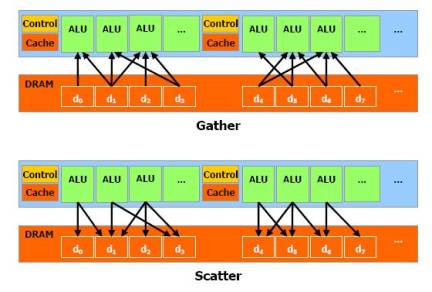
Рис 1.
Взаємодія модулів з пам’яттю
Ядро шейдерів
відеоадаптера складається з декількох кластерів текстурних мультипроцесорів
(Texture Processor Cluster, TPC) . Кожен мультипроцесор має певний набір
ресурсів. Є невелика область пам'яті під назвою "Загальна пам'ять/Shared
Memory", по 16 кбайт на мультипроцесор. Дана область пам'яті відкриває
можливість обміну інформацією між потоками в одному блоці. Важливо підкреслити
це обмеження: усі потоки в блоці гарантовано виконуються одним
мультипроцесором. Загальна пам'ять - не єдина, до якої можуть звертатися мультипроцесори.
Вони можуть використовувати відеопам'ять, але з меншою пропускною здатністю й
більшими затримками. Тому, щоб знизити частоту звертання до цієї пам'яті, у
мультипроцесорах є кеш (приблизно 8 кбайт на мультипроцесор), що зберігає
константи й текстури.
Для
тестування продуктивності перемноження матриць на CPU було написано три
програми. У всіх програмах відбувалося перемноження двох квадратних матриць
розміром 1000x1000, 1500x1500, 2000х2000. Програми, що використовувалися для
обчислення на CPU, були побудовані на основі технології OpenMP для забезпечення
паралельного виконання операцій. Програма для обчислення на GPU була побудована
з розмірами блоку у 32 потоки. В якості платформи для проведення обчислень була
обрана система з процесором AMD Phenom X3 720 (3 ядра по 2.8 GHz),
відеоадаптером Nvidia GeForce 9600 GT, операційною системою Windows 7 x32
Ultimate Edition. В якості компілятора використовувалась система Microsoft
Visual Studio Express 2008 + CUDA Libraries and Runtimes. Усі обчислення
проводилися з FP числами одинарної точності.
Вихідний код програми для обчислення на GPU
#include
<stdio.h>
#define
BLOCK_SIZE 32
#define
N
__global__
void matMult ( float * a, float * b, int n, float * c )
{
int bx = blockIdx.x;
int by = blockIdx.y;
int tx = threadIdx.x;
int ty = threadIdx.y;
int aBegin = n * BLOCK_SIZE * by;
int aEnd = aBegin + n - 1;
int aStep = BLOCK_SIZE;
int bBegin = BLOCK_SIZE * bx;
int bStep = BLOCK_SIZE * n;
float sum = 0.0f;
for ( int ia = aBegin, ib = bBegin; ia
<= aEnd; ia += aStep, ib += bStep )
{
__shared__ float as
[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float bs
[BLOCK_SIZE][BLOCK_SIZE];
as [ty][tx] = a [ia + n * ty + tx];
bs [ty][tx] = b [ib + n * ty +
tx];
__syncthreads();
for ( int k = 0; k < BLOCK_SIZE;
k++ )
sum += as [ty][k] * bs
[k][tx];
__syncthreads();
}
int ic = n * BLOCK_SIZE * by + BLOCK_SIZE
* bx;
c [ic + n * ty + tx] = sum;
}
int main (
int argc, char * argv [] )
{
int numBytes = N * N * sizeof ( float );
float * a = new float [N*N];
float * b = new float [N*N];
float * c = new float [N*N];
for ( int i = 0; i < N; i++ )
for ( int j = 0; j < N; j++ )
{
a [i] = 6.0f;
b [i] = 11.0f;
}
float * adev = NULL;
float * bdev = NULL;
float * cdev = NULL;
cudaMalloc ( (void**)&adev, numBytes
);
cudaMalloc ( (void**)&bdev, numBytes
);
cudaMalloc ( (void**)&cdev, numBytes
);
dim3 threads ( BLOCK_SIZE, BLOCK_SIZE );
dim3 blocks ( N / threads.x, N / threads.y);
cudaEvent_t start, stop;
float gpuTime = 0.0f;
cudaEventCreate ( &start );
cudaEventCreate ( &stop );
cudaEventRecord ( start, 0 );
cudaMemcpy ( adev, a, numBytes, cudaMemcpyHostToDevice );
cudaMemcpy ( bdev, b, numBytes, cudaMemcpyHostToDevice );
matMult<<<blocks,
threads>>> ( adev, bdev, N, cdev );
cudaMemcpy ( c, cdev, numBytes, cudaMemcpyDeviceToHost );
cudaEventRecord ( stop, 0 );
cudaEventSynchronize ( stop );
cudaEventElapsedTime ( &gpuTime,
start, stop );
printf("time spent executing by the
GPU: %.2f millseconds\n", gpuTime );
cudaEventDestroy ( start );
cudaEventDestroy ( stop );
cudaFree ( adev );
cudaFree ( bdev );
cudaFree ( cdev );
delete a;
delete b;
delete c;
getchar();
return 0;
}
Результати
проведення обчислень приведені нижче у таблиці.
|
Розмір
матриці |
Час
розрахунку (сек) /продуктивність (mf) |
||
|
CPU одне
ядро |
CPU три
ядра |
GPU 32
блоки |
|
|
1000x1000 |
3,98/500 |
1,37/1459 |
0,120/16658 |
|
1500x1500 |
14,151/476 |
4,828/1397 |
0,217/31095 |
|
2000x2000 |
29,72/538 |
11,24/1423 |
0,290/55158 |
Значне
прискорення (майже в 11 раз), яке було отримане порівняно з обчисленням на
трьох ядрах CPU виникло у випадку перемноження матриць тому що, дві матриці
розкладались на вектори і операції множення виконувались паралельно над блоками
у 32 потоки. Це надає можливість не витрачати багато часу на обмін даними з
пам’яттю, порівняно з CPU. Незначне зростання часу, витраченого на обчислення
матриць різних розмірів зумовлене тим, що у одному мультипроцесорі можуть
оброблюватись одночасно декілька блоків, тому збільшення розмірів матриць не
зумовлювало ситуацію черги блоків до мультипроцесорів і обчислення все одно
виконувались паралельно над усіма частинами матриці. Оптимізація паралельних
обчислень на GPU можлива шляхом
знаходження оптимальної кількості потоків для конкретної задачі.
Висновки
1.
При виконанні великої кількості однотипних обчислень, доцільно
використовувати обчислення на GPU.
2. На GPU не доцільно проводити
обчислення, в яких є необхідність постійного обміну даними при здійсненні
частих операцій. В останньому випадку можна навпаки: отримати меншу
продуктивність при обчисленні на GPU порівняно з CPU,
оскільки можливий варіант виконання операцій на різних мультипроцесорах, обмін
даними між якими значно складніший, ніж використання загального доступу до
пам’яті.
Література
1.
CUDA C Programming Guide (Nvidia Corporation www.nvidia.com/object/cuda_get.html) - 2009
2.
Joel Yliluoma. Guide into OpenMP: Easy multithreading programming for C++ (http://bisqwit.iki.fi/story/howto/openmp/)
– 2008