ПОСТРОЕНИЕ
ОПТИМАЛЬНЫХ КОДОВ
Кызылординский
Государственный Университет имени Коркыт ата
Г.Ж. Oтеген, Г.М. Енсебаева
Под кодом
понимают определенный набор символов и знаков, однозначно отображающего любое
сообщение, в том числе дискретизированное или мгновенно снятое с датчика
значение непрерывной величины.
При кодировании каждая буква исходного алфавита
представляется различными последовательностями, состоящими из кодовых букв
(цифр). Если исходный алфавит содержит m букв, то для построения равномерного кода
с использованием k кодовых букв необходимо удовлетворить соотношение m £ kq , где q - количество элементов в
кодовой последовательности.
Поэтому
![]()
Для построения равномерного кода достаточно
пронумеровать буквы исходного алфавита и записать их коды как q - разрядные
числа в k-ичной системе счисления.
Общее признанным в
настоящее время является позиционный принцип образования системы счисления.
Значение каждого символа (цифры) зависит от его положения - позиции в ряду
символов, представляющих число.
Единица каждого следующего разряда больше единицы предыдущего
разряда в m раз, где m - основание системы счисления. Полное число получают,
суммируя значения по разрядам:
![]()
где i - номер разряда данного числа; l - количество рядов; аi - множитель,
принимающий любые целочисленные значения в пределах от 0 до m-1 и показывающий,
сколько единиц i - ого ряда содержится в числе[1-2].
Часто используются двоично-десятичные коды, в которых
цифры десятичного номера буквы представляются двоичными кодами. Так, например,
для рассматриваемого примера буква с номером 13 кодируется как 0001 0011. Ясно,
что при различной вероятности появления букв исходного алфавита равномерный код
является избыточным, т.к. его энтропия (полученная при условии, что все буквы
его алфавита равновероятны): logkm = H0 всегда больше
энтропии H = log m данного алфавита (полученной с учетом неравномерности появления
различных букв алфавита, т.е. информационные возможности данного кода
используются не полностью).
Чем ближе значение qср к энтропии Н, тем
более эффективно кодирование. В идеальном случае, когда qср » Н, код называют эффективным[4].
Эффективное кодирование устраняет избыточность,
приводит к сокращению длины сообщений, а значит, позволяет уменьшить время передачи
или объем памяти, необходимой для их хранения.
При построении неравномерных кодов необходимо
обеспечить возможность их однозначной расшифровки. В равномерных кодах такая
проблема не возникает, т.к. при расшифровке достаточно кодовую последовательность
разделить на группы, каждая из которых состоит из q элементов. В неравномерных
кодах можно использовать разделительный символ между буквами алфавита (так
поступают, например, при передаче сообщений с помощью азбуки Морзе).
Если же отказаться от разделительных символов, то
следует запретить такие кодовые комбинации, начальные части которых уже
использованы в качестве самостоятельной комбинации. Например, если 101 означает
код какой-то буквы, то нельзя использовать комбинации 1, 10 или 10101.
Практические методы оптимального кодирования просты и
основаны на очевидных соображениях (метод Шеннона – Фэно).
Прежде всего, буквы (или любые сообщения, подлежащие
кодированию) исходного алфавита записывают в порядке убывающей вероятности.
Упорядоченное таким образом множество букв разбивают так, чтобы суммарные
вероятности этих подмножеств были примерно равны. Всем знакам (буквам) верхней
половины в качестве первого символа присваивают кодовый элемент 1, а всем
нижним 0. Затем каждое подмножество снова разбивается на два подмножества с
соблюдением того же условия равенства вероятностей и с тем же условием
присваивания кодовых элементов в качестве второго символа. Такое разбиение
продолжается до тех пор, пока в подмножестве не окажется только по одной букве
кодируемого алфавита. При каждом разбиении буквам верхнего подмножества
присваивается кодовый элемент 1, а буквам нижнего подмножества - 0.
Метод Шеннона - Фэно позволяет построить кодовые комбинации, в которых знаки исходного
ансамбля, имеющие наибольшую вероятность, кодируются наиболее короткими
кодовыми последовательностями. Таким образом, устраняется избыточность обычного
двоичного кодирования, информационные возможности которого используются не полностью.
Среднее число символов на знак в этом случае точно
равно энтропии. В общем случае для алфавита из восьми знаков среднее число
символов на знак будет меньше трех, но больше энтропии алфавита. Вычислим
энтропию алфавита:
![]()
Вычислим среднее число символов на знак:
![]()
где q(xi) - число символов в кодовой
комбинации, соответствующей знаку xi.
При кодировании по методу Шеннона - Фэно некоторая избыточность в последовательностях
символов, как правило, остается (qср > H) [1-3].
Повышение эффективности определяется лишь тем, что
набор вероятностей получившихся при укрупнении блоков можно делить на более
близкие по суммарным вероятностям подгруппы.
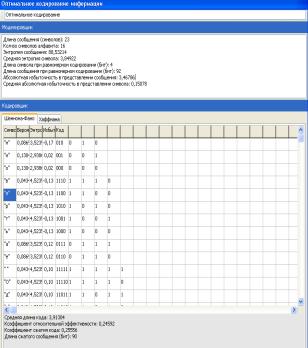
Рассмотренная методика Шеннона - Фэно не всегда приводит к однозначному построению кода,
т.к. при разбиении на подгруппы можно сделать большей по вероятности как
верхнюю, так и нижнюю подгруппы:
Таблица 1.
|
Знаки (буквы) xi |
Вероятность Pi |
1-е кодовые комбинации |
2-е кодовые комбинации |
||||||||
|
номер разбиения |
номер разбиения |
||||||||||
|
1 |
2 |
3 |
4 |
5 |
1 |
2 |
3 |
4 |
5 |
||
|
x1 |
0,22 |
1 |
1 |
|
|
|
1 |
1 |
|
|
|
|
x2 |
0,20 |
1 |
0 |
1 |
|
|
1 |
0 |
|
|
|
|
x3 |
0,16 |
1 |
0 |
0 |
|
|
0 |
1 |
1 |
|
|
|
x4 |
0,16 |
0 |
1 |
|
|
|
0 |
1 |
0 |
|
|
|
x5 |
0,10 |
0 |
0 |
1 |
|
|
0 |
0 |
1 |
|
|
|
x6 |
0,10 |
0 |
0 |
0 |
1 |
|
0 |
0 |
0 |
1 |
|
|
x7 |
0,04 |
0 |
0 |
0 |
0 |
1 |
0 |
0 |
0 |
0 |
1 |
|
x8 |
0,02 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
0 |
От указанного недостатка свободен метод Хаффмена.
Эта методика гарантирует однозначное построение кода с
наименьшим для данного распределения вероятностей средним числом символов на букву.
Для двоичного кода метод Хаффмена сводится к
следующему. Буквы алфавита сообщений выписывают в основной столбец таблицы в
порядке убывания вероятностей. Две последние буквы объединяют в одну
вспомогательную букву, которой приписывают суммарную вероятность. Вероятности
букв, не участвующих в объединении и полученная суммарная вероятность снова
располагаются в порядке убывания вероятностей в дополнительном столбце, а две
последние объединяются.
Процесс продолжается до тех пор, пока не получат
единственную вспомогательную букву с вероятностью, равной единице[1-3].
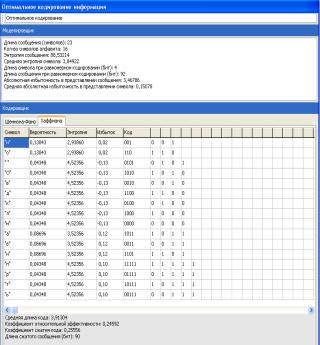
Используя метод Хаффмена, осуществим эффективное кодирование
ансамбля из восьми знаков:
Таблица 2.
|
Знаки |
Вероятности |
Вспомогательные столбцы |
Новая комбинация |
||||||
|
1 |
2 |
3 |
4 |
5 |
6 |
7 |
|||
|
x1 |
0,22 |
0,22 |
0,22 |
0,26 |
0,32 |
0,42 |
0,58 |
1 |
01 |
|
x2 |
0,20 |
0,20 |
0,20 |
0,22 |
0,26 |
0,32 |
0,42 |
|
00 |
|
x3 |
0,16 |
0,16 |
0,16 |
0,20 |
0,22 |
0,26 |
|
|
111 |
|
x4 |
0,16 |
0,16 |
0,16 |
0,16 |
0,20 |
|
|
|
110 |
|
x5 |
0,10 |
0,10 |
0,0 |
0,16 |
|
|
|
|
100 |
|
x6 |
0,10 |
0,10 |
|
|
|
|
|
|
1011 |
|
x7 |
0,04 |
0,6 |
|
|
|
|
|
|
10101 |
|
x8 |
0,02 |
|
|
|
|
|
|
|
10100 |
Для наглядности построим кодовое дерево. Из точки,
соответствующей вероятности 1, направляем две ветви, причем ветви с большей вероятностью
присваиваем символ 1, а с меньшей 0.
Использованная литература
1. Лидовский В.В. Теория
информации. Учебное пособие. - М., 2003.
2. Потапов В.Н. Теория
информации. Учебное пособие. - Новосибирск 1999.
3. Ожиганов А.А., Тарасюк М.В.
Передача данных по дискретным каналам. Учебное пособие. - Санкт-Петербург,
1999.
4. Марков А.А. Введение в
теорию кодирования. М.: Наука, 1982
5. Колесник В.Д., Полтырев Г.Ш. Введение в теорию
информации (Кодирование источников). Учебное пособие. - Л.:Изд-во
Ленингр.ун-та, 1980.