Современные информационные технологии/3.
Программное обеспечение
Ерёмин
Д.И. Ягфарова Н.И.
Институт
космической техники и технологий. Алматы. Казахстан
Особенности построения
локальной вычислительной сети в кластере GPU
Стремительное
развитие вычислительной техники и информационно-телекоммуникационных систем,
увеличение пропускной способности каналов передачи данных и ёмкости
запоминающих устройств привели к тому, что достигли внушительных размеров
объёмы хранимой и передаваемой информации внутри вычислительных систем. Широкое
распространение и применение на сегодняшний день находят корпоративные
информационные системы и сети (крупные объединения, компании, сети банков), и в
сложившихся условиях важнейшей задачей является оптимальное использование
вычислительных ресурсов внутри системы. Решение этих задач должно обеспечить
выбор оптимального варианта построения системы, эффективное распределение
вычислительных ресурсов и задач по обработке данных между клиентами и
серверами, снижающее затраты и повышающее качество организации вычислительного
процесса. При этом должны учитываться: степень приспособленности серверов к
обработке запросов, способы распределения данных в базах данных
(централизованный, расчлененный, дублирования, смешанный), организация
подключения клиентов к серверам (непосредственно через концентраторы, коммутаторы, ЛВС).
Современное
программирование является тенденцией к распределению вычислений между
несколькими, в общем случае различными компьютерами вычислительной сети.
Существующие стандартные технологии распараллеливания программ, такие как MPI
(Message Passing Interface - интерфейс передачи сообщений) и OpenMP (Open
Multi-Processing - открытый стандарт для распараллеливания программ),
ориентированы на разбиение вычислительной задачи на более мелкие процессы. Как
правило, это разбиение осуществляется вручную при разработке или модернизации
программного обеспечения. В то же время технологии объединения готовых
вычислительных блоков в более крупные распределенные системы практически
отсутствуют.
Новый подход к
организации распределенных вычислений отличается от традиционного тем, что речь
идет об использовании инновационных технологий для ускорения процесса
вычислений при использовании минимального количества вычислительных машин.
Решением может стать серверная система с GPU (Graphics
processing unit - графический процессор) кластером. Кластер GPU это
компьютерный кластер, в котором каждый узел оснащен графическим процессором.
Путем использования вычислительной мощности современных графических процессоров
расчеты могут быть выполнены очень быстро.
Между
архитектурами CPU (central processing unit – центральное процессорное
устройство) и GPU существуют некоторые основные различия (рисунок 1). [1]. Ядра
CPU созданы для исполнения одного потока последовательных инструкций с
максимальной производительностью, а GPU для быстрого исполнения большого числа
параллельно выполняемых потоков инструкций. Универсальные процессоры
оптимизированы для достижения высокой производительности единственного потока
команд, обрабатывающего и целые числа и числа с плавающей точкой.
В итоге, основой
для эффективного использования мощи GPU в неграфических расчётах является
распараллеливание алгоритмов на сотни исполнительных блоков, имеющихся в
видеокартах. К примеру, множество приложений по молекулярному моделированию
отлично приспособлено для расчётов на видеокартах, они требуют больших
вычислительных мощностей и поэтому удобны для параллельных вычислений. А
использование нескольких GPU даёт ещё больше вычислительных мощностей для
решения подобных задач.
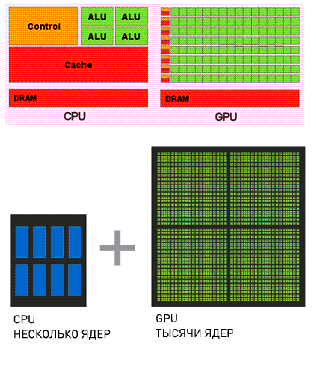
Рисунок 1
– Сравнение архитектур CPU и GPU
Выполнение
расчётов на GPU показывает отличные результаты в алгоритмах, использующих
параллельную обработку данных. К примеру, когда одну и ту же последовательность
математических операций применяют к большому объёму данных. При этом лучшие
результаты достигаются, если отношение числа арифметических инструкций к числу
обращений к памяти достаточно велико. Это предъявляет меньшие требования к
управлению исполнением программы, а высокая плотность математики и большой
объём данных отменяет необходимость в больших промежуточных буферах памяти, как
на CPU.
Литература:
1. Введение в гетерогенные вычисления.
Отличия архитектур CPU и GPU 2009 // Интернет ресурс:
http://edu.chpc.ru/cuda/mainch1.html#mainse2.html