Современные информационные технологии. Вычислительная техника и
программирование
Студент Антонов К.В.
Санкт-Петербургский
государственный университет аэрокосмического приборостроения, Россия
Особенности современных систем интеллектуального
поиска данных (Data mining)
Термин
«Data Mining» произошел от двух
английских слов «data» (рус. данные) и mine(рус.
шахта, добыча). Эта технология поиска данных введена в 1989 году Григорием
Пятецким-Шапиро - основателем этого направления. «Data Mining
— это процесс обнаружения в сырых данных ранее неизвестных, нетривиальных,
практически полезных и доступных интерпретации знаний, необходимых для принятия
решений в различных сферах человеческой деятельности»[1].
В русском языке термин «Data Mining»
означает интеллектуальный поиск данных. Data Mining
может быть применен везде, где есть работа с большими объемами данных.
В
основе технологии Data
Mining лежат шаблоны, отражающие взаимосвязь отдельных фрагментов
данных. Эти шаблоны представляют собой закономерности, которые могут быть выражены в понятной для человека форме и они
должны отражать неочевидные последовательности в данных (hidden
knowledge).
Термин
«hidden knowledge» (рус. «скрытые
знания») - это раннее неизвестные, нетривиальные и практически полезные знания,
которые можно легко представить в наглядной для пользователя форме.
Для поиска «скрытых
знаний» выделяют пять основных закономерностей данных:
·Ассоциация - связь двух и более событий или объектов друг с
другом.
·Последовательность - цепочка связанных во времени событий
или объектов.
·Классификация - выделение признаков, характеризующих к какой
области принадлежит тот или иной объект или событие. В классификации области
заданы заранее. Это делается путем анализа, и формирования некоторых правил.
·Кластеризация - выделение признаков, характеризующих к какой
области принадлежит тот или иной объект или событие, но области данных заранее
не заданы. Data Mining выделяет однородные
группы данных самостоятельно.
·Прогнозирование - предсказания поведения объекта или события
в будущем, основываясь на заранее полученную информацию из шаблонов, отражающих динамику поведения и
развития целевых показателей.
Классы систем Data Mining
1. Аналитическая обработка:
Аналитические системы
представляют собой совокупность десятков методов прогноза и выбора оптимальной
структуры модели для решения определенной задачи. Эти методы используют
статический аппарат и учитывают специфику своей области.
2. Деревья решений:
Деревья решений - один
из самых популярных методов реализации Data Mining.
Популярность данного метода связана с его наглядностью и понятностью, но
деревья решений не способны наиболее точно и полно находить правила в данных.
Деревья решений создают иерархическую структуру из правил типа "if-then",
имеющих вид дерева. Для того, чтобы отнести какой-либо объект к классу, нужно
ответить на вопросы, стоящие в узлах этого дерева, начиная с корня.
3. Нейронные сети:
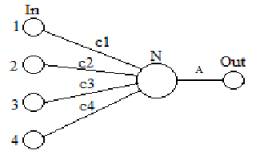
Рис.4. Одна ячейка нейронной сети.
На нейрон самого нижнего
уровня подаются входные сигналы, далее сигналы ослабляются или усиливаются в
зависимости от весов синапса (сn). В результате на
выходе нейрона высшего уровня вырабатывается некоторый ответ - реакция всей
системы на входное воздействие. Основной недостаток нейронных сетей -
необходимость иметь довольно большой объем обучающих данных.
4. Метод, основанный на аналогичных случаях.
Метод, основанный на
аналогичных случаях, строится на поиске в прошлом подобных ситуаций и уже
готовых решений. Этот метод также называется методом "ближайшего
соседа". У этого метода есть ряд существенных недостатков: он не создает
каких-либо моделей или правил, обобщающих предыдущий опыт, выбор меры близости,
от которой зависит результат классификации и прогноза.
Заключение
В
развитии систем Data Mining
принимают участие почти все крупнейшие корпорации. Системы интеллектуального
поиска данных применяются в основном в двух направлениях: в исследовательской
деятельности и для коммерческих целей. Несмотря на большое количество методов Data
Mining приоритетным на данный момент является метод, основанный на
логических функциях. Результаты таких алгоритмов легко интерпретируются в
понятной для пользователя форме. Внедрение Data Mining позволяет обнаружить
закономерности в базах данных и использовать полученные сведения для принятия
различного рода решений и может быть применен повсеместно, где есть большие
объемы данных. Прежде всего, Data Mining
нашел применение в розничной торговле, страховании, телекоммуникациях, медицине
и бизнесе.
Проблемы
развития Data Mining обусловлены
необходимостью серьезных экономических затрат, наличия большого объема
анализируемых данных, что ограничивает область его применения.
Тем
не менее, Data Mining является перспективным
направлением, поскольку позволяет оптимизировать экономические издержки, в
частности в сфере крупного бизнеса, и принимать на основе проведенного
интеллектуального анализа данных оптимальные управленческие решения.
Литература:
1. Гик Дж., Ван.
Прикладная общая теория систем. Изд. Мир. 1981.
2. Гонсалес Р., Вудс Р.
Цифровая обработка изображений. Изд. Техносфера. 2012.
3. Дюк В., Самойленко А.
Data Mining: учебный курс. СПб.: Питер. 2001.
4. Gregory Piatetsky-Shapiro. Data mining and knowledge discovery 1996 to 2005: overcoming the hype
and moving from “university” to “business” and “analytics”. Data Mining and Knowledge Discovery.Volume
15. Issue 1. 2007. pp 99-105.
5. Ian H. Witten, Eibe Frank and Mark A. Hall Data Mining: Practical
Machine Learning Tools and Techniques. 2011.
6. Knowledge Discovery Through Data Mining: What Is Knowledge Discovery?
Tandem Computers Inc.1996.