Сучасні інформаційні технології/Обчислювальна
техніка та програмування
Демянчук В. А.
Мясіщев О. А.
Хмельницький національний
університет, Україна
Дослідження
ефективності використання технології
CUDA для вирішення задач, які використовують великі масиви даних
Постановка задачі
У теперішній час послідовні системи обчислень на базі одного процесора не
являються перспективними для потреб високопродуктивних обчислень, тому у всьому
світі розглядаються та створюються все більше технологій пов’язаних з паралельними
обчисленнями. Для їх використання потрібні задачі, в яких є можливість
розпаралелювання. Прикладом таких завдань можуть бути задачі лінійної алгебри,
а саме матричні обчислення, у яких зі збільшенням потоків зростає швидкодія
опрацювання матриці чи матричних операцій.
Матриці досить широко
використовуються при математичному моделюванні різноманітних процесів та явищ.
Матричні обчислення являються основою для багатьох розрахунків у таких областях
науки як фізика (вивчення невпорядкованих і класично хаотичних динамічних систем,
оптичні явища), хімія (багатовимірний аналіз хімічних даних), економіка, і т.д.
Але такі обчислення являються досить
трудомісткими, і тому серйозні розрахунки раніше вимагали досить не дешевої
апаратної частини, яка б могла дати змогу їх прискорити за рахунок
багатопоточності.
На сьогодні час двох-,
чотирьох- та шестиядерні процесори, які можуть реалізовувати багатопоточність,
вже давно не рідкість, і на них досить успішно виконують паралельні обчислення.
У даній роботі розглядається
досить нова та успішна технологія паралельного обчислення з використанням
ресурсів відеокарти. Технологія CUDA (Compute Unified Device
Architecture) – програмно-апаратна архітектура, яка дозволяє робити обчислення
з використанням графічних процесорів NVIDIA, що підтримують технологію GPGPU
(довільних обчислень на відеокартах).
Програмно-апаратна архітектура для обчислень на
GPU компанії NVIDIA відрізняється від
попередніх моделей GPGPU тим, що дозволяє писати програми для GPU на справжній
мові С зі стандартним синтаксисом, вказівниками та необхідністю в мінімумі
розширень для доступу до обчислювальних ресурсів відеочіпів. CUDA не залежить від графічних API і володіє
деякими особливостями, призначеними спеціально для обчислень загального
призначення.
В
якості обчислювальної системи №1 використовувався персональний комп'ютер на
базі двохядерного процесора Intel Core 2 Duo E8500 3.16Ггц з оперативною
пам'яттю 4 Гбайта, відеокарта NVIDIA
GeForce GTX460, нижче приведена її специфікація:
· Частота ядра - 715 МГц
· Частота пам'яті - 3600 МГц
· 256-розрядна шина пам'яті
· Частота шейдерного блоку
- 1430МГц
· 336 CUDA ядер
· 1Гбайт оперативної пам'яті
Операційна система Windows 7
Максимальна 32-бит
Програмне забезпечення, що
використовується: Microsoft Visual Studio 2008, CUDA SDK 3.2, developer Drivers
270.51.
У якості прикладу для порівняння будемо
використовувати дані, обчислені на
системі №2, побудованій на базі одного чотирьохядерного процесора Intel Pentium
Core 2 Quad Q6600 2.4ГГц з оперативною пам'яттю 4 Гбайта. У якості операційної
системи була використана 32-х розрядна Linux Ubuntu ver. 9.04 desktop,
компілятори фортран F77 та gfortran ver. 4.3.3, які входять в склад цих
дистрибутивів. Для матричних обчислень використовують пакет Scalapack. Так як
обчислювальна система базується на чотирьохядерному процесорі, то програми
повинні передбачати процедури розпаралелювання обчислювального процесу. Для
цієї мети були використані бібліотеки MPI.
Бібліотека
Scalapack вимагає, щоб всі об'єкти (вектори і матриці), що є параметрами
підпрограм, були попередньо розподілені по процесорах. Для виконання цього
необхідно, щоб глобальні матриці A, B, C були представлені у вигляді окремих
блоків, які і повинні бути по блочно-циклічному способу розподілені по
процесорах (ядер процесора). Наприклад:
![]()
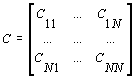 =AB=
=AB=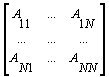
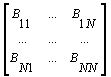
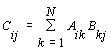
Тут ![]() - блочні матриці розміром
NB=(n/N)x(n/N), N - кількість блоків по рядкам або стовпчикам.
- блочні матриці розміром
NB=(n/N)x(n/N), N - кількість блоків по рядкам або стовпчикам.
Отримані результати
Нижче
приведемо результати обчислень на системі №2
та порівняємо їх з результатами обчислень на обчислювальній системі №1.
Числа
одинарної точності 32-х розрядна версія Linux Ubuntu ver. 9.04 desktop. Використовується компілятор F77, бібліотеки scalapack-1.8.0 blas і atlas3.8.3.
Обчислення
матриць одним ядром та чотирма ядрами з використанням бібліотеки blas, та порівняння з
результатами технології CUDA представлено у таблиці 1.
Таблиця
1
|
Розмір матриці |
Бібліотека blas |
|
|
||
|
Одне ядро |
Чотири ядра |
Приск. |
CUDA |
Приск. |
|
|
1000х1000 |
1.34/1497 |
0.33/5980 |
3.99 |
0,01889 |
70,9 |
|
2000х2000 |
10.58/1512 |
2.70/5935 |
3.93 |
0,15321 |
69,05 |
|
4000х4000 |
84.87/1508 |
21.29/6012 |
3.99 |
1,22543 |
69,25 |
|
5000х5000 |
172.0/1453 |
41.95/5959 |
4.10 |
2,38564 |
72,09 |
Обчислення
матриць одним ядром та чотирма ядрами з використанням бібліотеки atlas3.8.3, та порівняння з
результатами технології CUDA представлено у таблиці 2.
Таблиця
2
|
Розмір матриці |
Бібліотека atlas3.8.3 |
|
|
||
|
Одне ядро |
Чотири ядра |
Приск. |
CUDA |
Приск. |
|
|
1000х1000 |
0.17/11912 |
0.06/34724 |
2.92 |
0,01889 |
8,99 |
|
2000х2000 |
1.25/12829 |
0.38/41887 |
3.27 |
0,15321 |
8,16 |
|
4000х4000 |
9.72/13167 |
2.68/47819 |
3.63 |
1,22543 |
7,93 |
|
5000х5000 |
18.9/13200 |
5.19/48155 |
3.65 |
2,38564 |
7,92 |
Обчислення, які виконуються на відеокарті, ми виконуємо у shared-пам’яті,
яка характеризується високою швидкодією, але має малий розмір. Для цього розіб’ємо
результуючу матриці на підматриці розміром 16х16, обчисленням кожної такої
підматриці буде займатись один блок. Це і підніме нам швидкодію, у порівнянні з
обчисленням на CPU. Мінусом цієї технології є те, що відеокарти ще не досить
добре пристосовані до обчислень з подвійною точністю, і тому вони в цьому
випадку можуть поступатись обчисленням процесорів.
Висновок:
Представлена
компанією NVIDIA програмно-апаратна архітектура для розрахунків
на відеочіпах CUDA добре підходить для вирішення широкого кола завдань з
високим паралелізмом. Проведені обчислення показали, що технологія CUDA при
правильній програмній реалізації в
обчисленні чисел з одиночною точністю впевнено обходить чотирьохядерний
процесор. Це досягається завдяки можливості розпаралелювання задачі на більш
прості підзадачі.
Література:
1. Боресков А. В., Харламов А. А. Основы работы с технологией CUDA. –М.: ДМК Пресс, 2010. - 232 с.: ил.
2. Мясіщев О. А.
Достижение наибольшей производительности перемножения матриц на системах
с многоядерными процессорами.
3. Бересков А. В. Массивно-параллельные вычисления с
использованием технологии CUDA (видео-лекции)
http://www.intuit.ru/video/59/.
4. Матеріал з Вікіпедії.
CUDA - http://ru.wikipedia.org/wiki/CUDA.
5. Шикин А. В., Боресков А.В. Компьютерная графика.
Полигональные модели –М.: ДИАЛОГ-МИФИ, 2001. - 464с.
6. David B. Kirk, Wen-mei W. Hwu, Programming Massively
Parallel Processors: A Hands-on Approach, Morgan Kaufmann 2010, 280p.