Прохорова В.В.,
кандидат економічних наук, доцент
Харківський
національний економічний університет
Шакіна М.Ю.,
студентка Харківського торговельно–економічного інституту КНТЕУ
Кластерний
аналіз підприємств за рівнем фінансової стійкості
Кластерний аналіз – це
сукупність методів, що дозволяють класифікувати багатомірні спостереження,
кожне з яких описується набором вихідних змінних Х1, Х2.....Хn.
Метою кластерного аналізу є утворення груп схожих між собою об'єктів, які
прийнято називати кластерами. Слово кластер англійського походження (cluster),
переводиться воно як згусток, пучок, група. Родинні поняття, використовувані в
літературі – клас, таксон, згущення.
Методи кластерного аналізу
дозволяють вирішувати наступні завдання:
·
проведення
класифікації об'єктів з урахуванням ознак, що відображають сутність, природу
об'єктів. Рішення такого завдання, як правило, приводить до поглиблення знань
про сукупність класифікованих об'єктів;
·
перевірка висунутих
припущень про наявність
деякої структури в досліджуваній сукупності об'єктів, тобто пошук існуючої структури;
·
побудова
нових класифікацій для маловивчених явищ, коли необхідно встановити наявність
зв'язків усередині сукупності й намагатися привнести в неї структуру.
Існують наступні групи методів
кластерного аналізу:
1) ієрархічні методи;
2) ітеративні методи;
3) факторні методи;
4) методи згущень;
5) методи, що використовують
теорію графів.
До найпоширенішим в економіці відносять ієрархічні й
ітеративні.
Для проведення класифікації
необхідно ввести поняття подібності об'єктів за спостережуваними змінними. У
кожний кластер (клас, таксон) повинні потрапити об'єкти, що мають подібні
характеристики.
Якщо алгоритм кластеризації
заснований на вимірі подібності між змінними, то в якості міри подібності
можуть бути використані:
·
відстань;
·
лінійні
коефіцієнти кореляції;
·
коефіцієнти
рангової кореляції;
·
коефіцієнти
контингенції й т.д.
Залежно від типів вихідних змінних вибирається один з
видів показників, що характеризують близькість між ними.
Вибір відстані між об'єктами є
вузловим моментом дослідження, від нього багато в чому залежить остаточний
варіант розбивки об'єктів на класи при даному алгоритмі розбивки.
У кластерном
аналізі для кількісної оцінки подібності вводиться поняття метрики. Подібність
або розходження між класифікованими об'єктами встановлюється залежно від
метричної відстані між ними. Якщо кожний об'єкт описується k ознаками, то він
може бути представлений як точка в k-мірному просторі, і подібність із іншими
об'єктами буде визначатися як відповідна відстань. У кластерному аналізі
використаються різні міри відстані між об'єктами:
1) Евклідова
відстань: 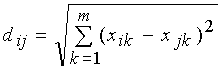 (3.12)
(3.12)
2) взважена
Евклідова відстань: 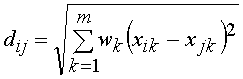 (3.13)
(3.13)
3) відстань city-block: 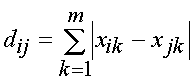 (3.14)
(3.14)
4) відстань Московського: 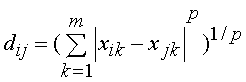 (3.15)
(3.15)
5) відстань
Махаланобіса: ![]() (3.16)
(3.16)
де dij— відстань між i-м и j-м
об’єктами;
xik, xjk — значення k-й змінної відповідно у i-го та j-го
об’єктів;
Xi,Xj— вектори значень змінних у i-го та j-го об’єктів;
S*— загальна коваріаційна матриця;
wk — вага, що приписується k-й змінній.
Алгоритм ієрархічного агломеративного
кластерного аналізу можна представити у
вигляді послідовності процедур:
1) нормуються вихідні дані;
2) розраховується матриця
відстаней або матриця мір подібності;
3) перебуває пара
найближчих кластерів, по обраному
алгоритмі поєднуються ці два кластери. Новому кластеру привласнюється менший з
номерів поєднуваних кластерів;
4) процедури 2, 3 і 4
повторюються доти, поки всі об'єкти не будуть об'єднані в один кластер або до
досягнення заданого "порогу" подібності.
До ітеративних методів
угруповання відноситься метод k-середніх зручний для обробки великих
статистичних сукупностей. Обчислювальні процедури більшості ітеративних методів
класифікації зводяться до виконання наступних кроків:
1. Вибір числа кластерів, на
які повинна бути розбита сукупність, завдання первісної розбивки об'єктів і
визначення центрів ваги кластерів.
2. Відповідно до обраних мір подібності визначення нового
складу кожного кластера.
3. Після повного перегляду всіх
об'єктів і розподілу їх по кластерах здійснюється перерахування центрів ваги
кластерів.
4. Процедури 2 і 3 повторюються
доти , поки наступна ітерація не дасть такий же склад кластерів, що й
попередня.