ИДЕАЛЬНАЯ
ЛИНГВОМАТЕМАТИЧЕСКАЯ МОДЕЛЬ
Кажикенова С.Ш., Шурыгина Е.
Как известно, для расчета энтропии
необходимо иметь полное распределение
вероятностей возможных комбинаций. Поэтому для вычисления энтропии той или иной
буквы необходимо знать вероятности появления каждой возможной буквы. Мы предлагаем идеальную
лингвоматематическую модель для анализа структуры текста. Она построена на
основе фундаментального закона сохранения суммы информации и энтропии с
применением формулы Шеннона [1-4]. При общей характеристике
энтропийно-информационного (энтропия - мера беспорядка, а информация – мера
снятия беспорядка) анализа текстов мы использовали статистическую формулу
Шеннона для определения совершенства, гармонии текста:
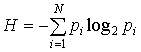 , (1)
, (1)
где рi – вероятность обнаружения какого-либо однородного
элемента системы в их множестве ![]() ;
; 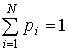 ,
, ![]()
![]() .
.
До опубликования созданной Шенноном теории Хартли
предложил определять количество максимальной энтропии по формуле
![]() .
.
Большой
интерес представляют исследования в области теории информации. Важным для
языкознания измерением является энтропия языка. Энтропия языка является общей
мерой вероятностно-лингвистических связей в тексте данного языка. В связи с эти мы проводим сопоставление данных,
характеризующих численную оценку этих измерений на казахском и русском языках.
Так как русский алфавит содержит 32 буквы (31 буква, 1
пробел), то согласно этому результату
![]() бит.
бит.
![]() - максимальное значение энтропии текста, заключающегося в
приеме одной буквы русского текста (информация, содержащаяся в одной букве),
при условии, что все буквы считаются одинаково
вероятными;
- максимальное значение энтропии текста, заключающегося в
приеме одной буквы русского текста (информация, содержащаяся в одной букве),
при условии, что все буквы считаются одинаково
вероятными;
бит- единица измерения информации.
Нами был
проведен информационно-энтропийный анализ
отрывка из курса лекций по
экономической теории. Выделенный нами отрывок из лекций представляет собой текст
научного стиля, в котором четко выражены признаки и особенности языка науки.
Для
вычисления информации научного текста нами были подсчитаны вероятности появления одной буквы, двухбуквенных, трехбуквенных.
четырехбуквенных, пятибукве6нных, а также шестибуквенных сочетаний в данном тексте. При подсчете учитывались
31 буква русского алфавита (буквы е
и е, ъ и ь принимаются
как одна буква) и пробел, все остальные знаки (скобки, кавычки, запятые и пр.) не рассматривались.
Учитывается и такой аспект в
характеристике текста, как мера вероятности прагматической информации,
спроецированной на потенциального читателя. Если эту меру вероятности прагматической (новой, полезной,
воспринимаемой данным читателем) информации обозначить термином «энтропия», то
по отношению к функционально разным текстам эта мера определится следующим
образом: для официально-деловых текстов адекватность энтропии принципиальна,
для научных – ограничена специальным кругом читателей, потому вполне
предсказуема; для публицистических и газетных текстов адекватность энтропии
принципиальна, но непредсказуема; для
художественных – непринципиальна и непредсказуема.
Чтобы вычислить относительную частоту каждой буквы,
необходимо количество каждой буквы разделить на общее количество всех знаков
(500).
|
ква |
Число появления буквы: количество всех букв |
Относит. частота |
буква |
Число появления буквы: количество всех букв |
Относит. частота |
|
а |
26:500 |
0,052 |
р |
27:500 |
0,054 |
|
б |
4:500 |
0,008 |
с |
24:500 |
0,048 |
|
в |
25:500 |
0,05 |
т |
29:500 |
0,058 |
|
г |
4:500 |
0,008 |
у |
11:500 |
0,022 |
|
д |
10:500 |
0,02 |
ф |
3:500 |
0,006 |
|
е |
30:500 |
0,06 |
х |
2:500 |
0,004 |
|
ж |
5:500 |
0,01 |
ц |
1:500 |
0,002 |
|
з |
10:500 |
0,02 |
ч |
2:500 |
0,004 |
|
и |
45:500 |
0,09 |
ш |
3:500 |
0,006 |
|
й |
6:500 |
0,012 |
щ |
2:500 |
0,004 |
|
к |
14:500 |
0,028 |
ы |
6:500 |
0,012 |
|
л |
18:500 |
0,036 |
ъ,ь |
2:500 |
0,004 |
|
м |
9:500 |
0,018 |
э |
5:500 |
0,01 |
|
н |
34:500 |
0,068 |
ю |
3:500 |
0,006 |
|
о |
55:500 |
0,11 |
я |
13:500 |
0,026 |
|
п |
14:500 |
0,028 |
пробел |
58:500 |
0,116 |
Расположим
относительную частоту знаков последовательно, в порядке убывания:
|
Буква частота |
Пробел 0,116 |
О 0,11 |
И 0,09 |
Н 0,068 |
Е 0,06 |
|
Буква частота |
Т 0,058 |
Р 0,054 |
А 0,052 |
В 0,05 |
С 0,048 |
|
Буква частота |
Л 0,036 |
К 0,028 |
П 0,028 |
Я 0,026 |
У 0,022 |
|
Буква частота |
Д 0,02 |
З 0,02 |
М 0,018 |
Й 0,012 |
Ы 0,012 |
|
Буква частота |
Ж 0,01 |
Э 0,01 |
Г 0,008 |
Б 0,008 |
Ю 0,006 |
|
Буква частота |
Ф 0,006 |
Ш 0,006 |
Ъ, Ь 0,004 |
Х 0,004 |
Ч 0,004 |
|
Буква частота |
Щ 0,004 |
Ц 0,002 |
|
|
|
Вычислив энтропию текста при учете 1, 2, 3, 4, 5, 6 букв, мы пришли к следующим показателям:
Н1=
4, 364бит,
Н2=
Нα1 (α2)= Н (α1α2)- Н (α1)=
7,3406-4,364= 2,9766
Н3= Нα1α2
(α3)= Н
(α1α2 α3)-
Н (α1 α2)= 8,123-7,3406=0, 7824
Н4=
Нα1α2 α3 (α4)= Н (α1α2 α3 α4)- Н (α1
α2 α3)= 8,4656 - 8,123= 0, 3426
Н5=
Нα1α2 α3 α4 (α5)= Н (α1α2 α3 α4 α5)-
Н (α1 α2 α3 α4)=
8, 5271 - 8,4656 = 0,0615
Н6=
Нα1α2 α3 α4 α5 (α6)= Н
(α1α2 α3
α4 α5 α6)- Н (α1
α2 α3 α4 α5)=8,5808
- 8, 5271 =
0,
0537
Таким образом, в русском языке
![]()
![]()
![]()
![]()
![]()
![]()
4, 364
2, 9766 0,7824 0,3426 0,0615 0,0537
Таким образом, полный анализ показывает,
что план построения сложной информационной системы может формироваться только
на верхних иерархических уровнях и оттуда спускаться на нижележащие уровни,
задавая на них тот или иной порядок чередования элементов.
Используемый теорией информации
статистический метод учета межбуквенных корреляций в литературных текстах обоих
языков зависит от смыслового контекста
и одна, и две, и три буквы и т.д. могут
быть в одних случаях самостоятельным словом, а в других - входить в состав
других слов.
Очевидно, что рассматриваемые сочетания букв относятся к различным иерархическим
уровням текста, однако подобное разграничение уровней может осуществляться
только по смыслу, который заключает в себе анализируемый текст.
Литература
1 Кажикенова С.Ш., Оспанова Б.Р. Информационно-энтропийный анализ
структуры текста // Караганда: Изд-во КарГТУ, 2012.
– 251с.
2 Кажикенова
С.Ш., Оспанова Б.Р. К
вопрос у о формировании концептуальной системы целевого языка в структуре
коммуникативной компетенции // Язык и
культура. – Томск, 2012.- №3. – С. 111-121.
3 Кажикенова
С.Ш., Оспанова Б.Р. О некоторых аспектах
языковой модели в теории информации //
Международный журнал экспериментального образования. – М., 2012. - №8. – С.
115-120.
4 Кажикенова С.Ш., Оспанова Б.Р. Лингвосинергетический подход к исследованию текста как
самоорганизующегося объекта // Хаос и структуры в нелинейных системах.
Материалы междунар. науч.-практ.
конф.(18-20 июня)/КарГУ. – Караганда: Изд-во КарГУ, 2012. – С.546-550