18-СИ/ 1. Компьютерная инженерия
Швачич Г.Г.
Национальная металлургическая академия Украины,
г.
Днепропетровск, Украина
О ПАРАЛЛЕЛЬНЫХ КОМПЬЮТЕРНЫХ ТЕХНОЛОГИЯХ КЛАСТЕРНОГО ТИПА РЕШЕНИЯ
МНОГОМЕРНЫХ НЕСТАЦИОНАРНЫХ ЗАДАЧ
Суть проблемы
исследований. Создание новых или реструктуризация существующих
технологических процессов требует проведение экспериментов (лабораторных или
промышленных). Однако в настоящее время существенно сократился объем средств,
выделяемых на разработку и создание новых материалов или технологических
процессов. В этой связи в новых экономических условиях требуются принципиально
другие подходы к созданию прогрессивных ТП. Перспективное направление –
моделирование и создание компьютеризированных ТП.
Особенности математических моделей рассматриваемого типа
задач. В
металлургическом производстве
сталкиваются с множеством самых разнообразных и взаимосвязанных
процессов. Это и теплоперенос, и тепло – и массообмен, включающий гидродинамические
процессы в расплавах с учетом изменения агрегатного состояния вещества и
деформационных явлений под действием
силовых и термических нагрузок и
т.п. Большинство таких процессов может быть описано на основе дифференциальных
уравнений механики сплошных сред, отражающих объективные законы сохранения
массы, количества движения и энергии
[1,2].
Такие тепло - и
массообменные процессы во многих случаях
следует рассматривать как большие системы, спецификой которых является не
только большое число входных и выходных величин, но и их взаимосвязь.
Исследуемые объекты рассматриваемого
класса задач являются трехмерными и нестационарными. Очевидно, что математическое моделирование многомерных
задач невозможно без применения средств вычислительной техники. Нынешний этап
научных исследований отличается тем, что имеет место огромная вычислительная
мощность современных средств вычислительной техники, при помощи которых
проводится соответствующий этап математического моделирования. Однако
существует широкий класс задач, решение которых при помощи классического
(последовательное) моделирования (особенность его состоит в том, что
реализуется на однопроцессорном компьютере) занимает неприемлемо долгое время
(недели и месяцы). К таким задачам относятся, например, численное моделирование
процессов гидродинамики и металлургической теплофизики, задачи распознавания
образов, оптимизационные задачи с большим числом параметров и т.д.
Очевидно, что для решения
указанного типа задач необходимо применять параллельные вычислительные системы
[3,4]. Параллельные вычислительные
системы развивались очень быстро, а с появлением вычислительных кластеров
параллельные вычисления стали и доступными многим. Это объясняется тем, что для
построения кластеров, как правило, используются массовые процессоры,
стандартные сетевые технологии и свободно распространяемое программное
обеспечение [5].
Основные предпосылки и проблемы формирования параллельного
процессора. Во-первых,
появление новых и недорогих средств коммуникации вычислительной техники стимулировало
развитие новых информационных технологий (ИТ): структурного программирования;
сетевых операционных систем; объектно-ориентированного программирования, систем
параллельной обработки информации и т.д.
Во-вторых, к настоящему
времени наметились определенные тенденции по развитию вычислительных методов со
сложной логической структурой, имеющих по сравнению с традиционными
конечно-разностными методами более высокий порядок точности.
В-третьих, использование неявных схем при этом приводит
к системам линейных алгебраических уравнений (СЛАУ), имеющих трехдиагональную
структуру.
В-четвертых, известно,
что наибольший эффект от параллельного процессора достигается в тех случаях, когда он применяется для
выполнения матричных вычислений линейной
алгебры.
Для того чтобы в полной мере использовать преимущества, предоставляемые
такими ЭВМ, необходимо решить следующие задачи:
- сконструировать алгоритмы
решения задач с учётом возможностей параллельной обработки данных
несколькими процессорами одновременно;
- реализовать процесс вычислений таким образом, чтобы каждый процессор
использовался наиболее полно, и при этом
суммарное время решения задачи стремилось к минимуму.
Проблемы, возникающие при разработке параллельных вычислительных систем,
отвечающих заданным характеристикам, как правило, являются первостепенными и
требуют глубокого изучения и исследования.
Действительно, распределенное (параллельное) компьютерное моделирование
охватывает весь спектр современной вычислительной техники: суперкомпьютеры,
кластерные вычислительные системы, локальные и глобальные сети. Кроме того,
распределенное моделирование позволяет решать задачи, требующие большого
количества процессорного времени, интегрировать математические модели, которые
обрабатываются на различных (в том числе и географически отдаленных)
вычислительных системах.
Заметим, что компьютерные вычислительные кластеры дополнительно
стимулировали развитие новой области знаний – технологии параллельных
вычислений (ТПВ), основные особенности которой для рассматриваемого класса
задач освещаются в следующем разделе статьи.
Некоторые принципы конструирований
параллельных алгоритмов.
Очевидно, что при использовании
многопроцессорных систем камнем преткновения становится проблема так
называемого «распараллеливания алгоритмов» для программирования на
многопроцессорной структуре. Последовательные алгоритмы, используемые при
работе на однопроцессорных компьютерах, как правило, не приспособлены для
такого распараллеливания. Это объясняется тем, что при практическом применении
технологии параллельных вычислений возникают проблемы приобретения опыта в
разработке параллельных алгоритмов и программ, их отладке, управления
заданиями при работе кластера,
интерпретации и представления результатов работы кластерной системы и т.д.
Вообще отметим, переход от парадигмы последовательной алгоритмизации к
конструированию алгоритмов параллельной обработки данных требует определенного
переосмысления технологии программирования. В этой связи вопросы алгоритмизации
ТПВ на сегодняшний день, по мнению авторов, являются наиболее важными и
актуальными.
Рассмотрим некоторые
принципиальные особенности
конструирования алгоритмов для параллельного процессора.
При этом проиллюстрируем основные
алгоритмические идеи формирования параллельного процессора на фоне решения
следующей задачи.
Итак,
рассмотрим решение краевой задачи Дирихле для одномерного уравнения
теплопроводности
|
|
(1) |
с начальным
|
|
(2) |
и граничными условиями
|
|
(3) |
Уравнение (1) при помощи неявной
схемы по времени и центральные разности по координате x
сводится к СЛАУ
|
|
(5) |
где
|
|
(6) |
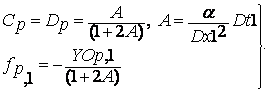
Для численного моделирования
уравнения (5) на параллельном процессоре можно использовать несколько подходов.
Рассмотрим их.
Распараллеливание СЛАУ (5) при помощи перестановок [6].В основу метода распараллеливания
одной и той же математической задачи – системы линейных алгебраических
уравнений в форме (5) с функциональным наполнением (6) полагается алгоритм «нечетно-четной» редукции [6]. Идея
этого метода состоит в исключении некоторых коэффициентов системы уравнений (5)
при помощи элементарных преобразований строк.
Множеству операций
алгоритма «нечетно-четной» редукции СЛАУ
(5) к параллельной форме поставим во взаимно однозначное соответствие некоторое
множество точек, зависящее от счетности сеточных узлов на множестве ![]() . На первом этапе редукции, понизив и повысив в СЛАУ (5)
индекс р на единицу, найдем:
. На первом этапе редукции, понизив и повысив в СЛАУ (5)
индекс р на единицу, найдем:
|
|
(7) |
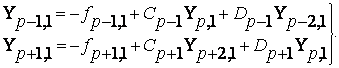
Соотношение (7) является достаточно удобным для реализации вычислений на
параллельном процессоре. После замещения в (5) крайних слагаемых по формулам
(7) получают уравнение трехдиагональной структуры относительно ![]() . Повторное применение этого процесса редукции приводит к уравнению относительно
. Повторное применение этого процесса редукции приводит к уравнению относительно ![]() и т.д. до тех пор,
пока не приходят к одному уравнению относительно элемента
и т.д. до тех пор,
пока не приходят к одному уравнению относительно элемента ![]() , соответствующего центральному узлу. При этом необходимо
принять, что число узлов
, соответствующего центральному узлу. При этом необходимо
принять, что число узлов ![]() является степенью двойки. Применение изложенного алгоритма
для решения трехдиагональных систем на параллельных вычислительных процессорах
весьма перспективно [6].
является степенью двойки. Применение изложенного алгоритма
для решения трехдиагональных систем на параллельных вычислительных процессорах
весьма перспективно [6].
Распараллеливание СЛАУ (5)
численнно-аналитическим методом прямых [7].
Рассмотрим
вариант распараллеливания СЛАУ (5) для случая, когда ее функциональное
наполнение представлено в виде
гиперболических функций, которые
являются линейными комбинациями базисного решения двухточечной краевой
задачи. Для реализации распараллеливания СЛАУ (5) предлагается использовать
метод прогонок.
Известно, что в методе прогонок процедура прямой прогонки реализуется
рекуррентно формированием двух последовательностей Ер, Gp , (![]() ) по формулам:
) по формулам:
|
|
(8) |
 ,
,где старт для данной задачи
обеспечивается входными параметрами
|
Е0=0, G0= |
(9) |
После завершения процедуры прямой
прогонки в направлении возрастания индекса p вплоть до р=2m-1, процедура обратной
прогонки выполняется по рекуррентной формуле:
|
Yp,
1= Ep Yp+1, 1 +Gp |
(10) |
в направлении убывания индекса p от р=2m-1 до р=1. Старт этой
процедуры обеспечивается выполнением условия Y2m,1 =![]() , реализующего ввод в алгоритм прогонок правого
граничного условия (3).
, реализующего ввод в алгоритм прогонок правого
граничного условия (3).
Вычисление ![]() при таком подходе реализуется в явном виде. Процедура
обратной прогонки по формуле (10) позволяет найти решение в замкнутой форме
относительно любого узла.
при таком подходе реализуется в явном виде. Процедура
обратной прогонки по формуле (10) позволяет найти решение в замкнутой форме
относительно любого узла.
Соотношение (10) и положено в основу
разработки алгоритма распараллеливания. Такой алгоритм абсолютно устойчив для любых входных данных,
имеет максимальную параллельную форму и, следовательно, минимально возможное
время его реализации на параллельных вычислительных устройствах.
Если можно назначить один процессор на один узел расчета, то становится
возможным проведение расчетов во всех узлах
сеточной области параллельно и одновременно.
Особенности конструирования вычислительного кластера. Конструктивно вычислительный
кластер представляет собой вычислительную систему, построенную из стандартных
вычислительных узлов, объединенных быстродействующей низколатентной
(малоинерционной) компьютерной сетью. Заметим, что при освещении вопросов
конструирования и применения вычислительных кластеров часто рассматривают
понятие латентности. Под латентностью здесь понимают время самого простого
взаимодействия узлов кластера через
коммуникационную среду. Эти понятия вводятся для оптимизации сетевых
взаимодействий [8].
Практическая реализация
вычислительного кластера предполагает наличие главного (управляющего, MASTER) узла и некоторых подчиненных (SLAVE) вычислительных узлов. Как правило
компиляция и сборка исполняемых кодов программ осуществляется MASTER-машиной, инициирующей
соответствующие вычислительные процессы и рассылающей исполняемые коды программ
по SLAVE-машинам.
Данные MASTER-машиной рассылаются путем применения какого-либо из интерфейсов: MPI (Message Passing Interface) или PVM (Parallel Virtual Machine).
На рис. 1 представлена структурная схема разработанного автором
вычислительного кластера. Кластер собран из 5 системных блоков
идентичной конфигурации: Sempron 2000, 256 Mb RAM DDR 400, HDD Samsung 40 Gb,
Mb KT-600 ECS, Radeon 9200, Codegen 300 W, net card Realtek 8139. Системные
блоки подключены в сеть по технологии Ethernet 100BaseT через сетевой
коммутатор (switch), физический тип соединения – «звезда». Кластер работает под
управлением ОС Linux. Связь между узлами кластера осуществляется посредством
протоколов TCP/IP с использованием технологии MPI.
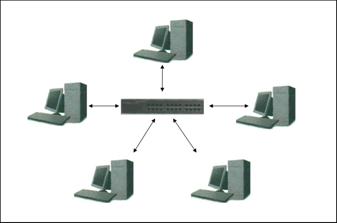
Рис. 1. Структурная схема
вычислительного кластера
В зависимости от составленного
алгоритма вычислений процесс работы такого кластера может развиваться по одному
из направлений:
- на всех компьютерах вычислительного кластера запускается одна также
программа;
- MASTER-машина готовит данные, необходимые SLAVE-машинам и рассылает их в виде MPI
- сообщений, а замет собирает с них обработанную информацию для
интерпретации.
Заметим, что внутри общей
программы MASTER-машина и SLAVE-машины идентифицируют себя посредством специальной
переменной – идентификатора.
Вычислительный кластер,
структурная схема которого представлена на рис. 1, является инструментальной
средой, предназначенной для приобретения навыков управления и программирования
многопроцессорных систем. Заметим, что вследствие применения Linux, стандартных систем программирования
и управления ресурсами, аналогичным профессиональных кластерных систем, процесс
переноса наработанного программного обеспечения на большие кластерные системы
максимально прост и удобен. Кроме того, мощные вычислительные системы не
отвлекаются на выполнение рутинных (отладочных операций).
Хотя заметим, что системное
программное обеспечение вычислительного кластера должно давать возможность
работы как в режиме Windows (подготовка текстового материала, обмен сообщений по E-Mail, привычный режим работы в INTERNET и тт.д.) и одновременно управлять
работой вычислительного кластера в среде Linux. Проблемы функционирования Windows – кластера, особенности совместной
работы Linux – кластера и операционной системы Windows автор надеется осветить в ближайших
публикациях.
Вычислительные
эксперименты. Эффективность
предложенного подхода иллюстрируется решением задач нестационарной
теплопроводности, некоторыми особенностями моделирования обратных задач
исследования теплофизических свойств материалов, задач прогноза экологических
систем под влиянием естественных и антропогенных факторов. Вычислительные
эксперименты подтверждает эффективность предложенного подхода.
ВЫВОДЫ
1. Суперкомпьютеры в
настоящее время малодоступны вследствие огромной
стоимости и цены
обслуживания. В этой связи реальной альтернативой
является
применение вычислительных систем кластерного типа, один из
вариантов,
которой освещается в данной статье.
2. Являясь достаточно новой
технологией, параллельные
вычислительные
системы
кластерного типа эффективны при решении широкого класса
нестационарных
многомерных задач, позволяя при этом повысить
производительность
и качество вычислений.
3. Применение
операционной системы LINUX позволяет
максимально
просто перейти на
мощные многопроцессорные системы, не отвлекаясь на
выполнение
рутинных отладочных операций.
4. Разработанные алгоритмы решения
исследуемых задач
отличаются высокой точностью и
эффективностью. Например, тестовый вариант решения ОЗТ при точных входных
данных абсолютно совпадает с
теплофизических характеристик материала образца.
5. Разработанное программное
обеспечение для обработки результатов
теплофизического эксперимента является саморегуляризирующимся и
достаточно просто перестраивается на
решение других и, в частности,
граничных ОЗТ.
Литература
1.
Лойцянский
Л. Г. Механика жидкости и газа.- М.: Наука. Гл.ред. физ.-мат.лит., 1987.- 840с.
2.
Роуч
П. Вычислительная гидродинамика./Пер. с англ.-М.: Мир, 1980.-616с.
3.
Воеводин
В. В. Математические модели и методы в параллельных процессах. М.: Наука,
1986.- 296с.
4.
Воеводин
В. В., Воеводин В. В. Параллельные вычисления.- СПб.: БХВ - Петербург, 2002.- 608 с.
5.
Системы
параллельной обработки: Пер. с англ./ Под редакцией Д. Ивенса.- М.: Мир, 1985.- 416с.
6.
Швачич
Г. Г., Шмукин А. А. Особенности конструирования параллельных вычислительных
алгоритмов для ПЭВМ в задачах тепло- и массообмена // Восточно Европейский
журнал передовых технологий. 2(8) 2004. с. 42-47.
7.
Швачич
Г. Г., Шмукин А. А. О концепции неограниченного параллелизма в задачах теплопроводности
// Восточно Европейский журнал передовых технологий. 3(9) 2004. с. 81-84.
8.
Лацис
А.О. Как построить и использовать суперкомпьютер. – М.:
Бестселлер, 2003, 240 с.