Современные информационные
технологии / 3. Программное обеспечение
К.т.н., доцент, Гриценко Е.М.
Сазонов С. А.
ФГБОУ ВПО «Сибирский государственный технологический
университет»
г.Красноярск
Разработка инструмента
для исследования рынка труда ИТ-специалистов
Информационные технологии с
каждым годом оказывают все большее влияние, как на экономику, так и на
повседневную жизнь людей. Этапы качественного развития большинства отраслей
(энергетики, медицины, образования, торговли, финансового сектора, страхования
и др.) и государственного управления, в том числе в военной сфере, связаны с
внедрением информационных технологий. Отрасль информационных технологий
является одной из наиболее динамично развивающихся отраслей, как в мире, так и
в России. Однако на рынке труда наблюдается острый кадровый дефицит. Дальнейшее
развитие большинства сегментов отрасли требует решения проблемы нехватки
квалифицированных кадров. [1]
В настоящее время объемы и перечень
специальностей и профессий, по которым готовят молодых рабочих и специалистов,
зачастую планируются на основе устаревшей или недостаточно проверенной
информации, не отражающей произошедших изменений на рынке труда и не
учитывающей емкости рынка трудовых ресурсов. Как следствие, часть выпускников
рискуют получить специальности, уже не востребованные рынком труда
В ходе анализа предметной области выявлено, что
первый шаг по наполнению профессиональной компетенции состоит в анализе рынка
труда, на предмет востребованности определённых областей знаний. Таким образом,
необходим сбор некой базы данных о вакансиях. Она должна содержать данные об
уровне зарплате и перечень основных требований, необходимых для работы навыков.
При разработке базы данных также необходимо было учесть, что данные о вакансиях
с сайтов могут повторяться, иметь недостаточную информацию, не иметь
необходимой информации, либо быть неприменимыми для нашего анализа (например,
вакансии в области продаж ИТ услуг, главным требованием которых является лишь
необходимость «обходить дома и предлагать услуги»).
Интернет является одним из самых богатых
источников информации. Однако для дальнейшего анализа выяснилось, что
необходимо ограничить поиск информации в рамках одной из областей. Это связано
с тем, что необходимыми данными для анализа являются данные по уровню зарплаты,
а специфика уровня зарплаты в нашей стране в том, что он разнится для разных
регионов (от 10000 руб. в Красноярске, до 30000 руб. в Москве). Кроме того по
данным службы статистики большинство выпускников вузов (около 80%) не покидают
регион, где они получали образование, после окончания учебного заведения. Таким
образом, для получения наиболее адекватных данных решено было ограничиться
сбором информации о вакансиях в Красноярске и Красноярском крае.
Автоматизация сбора данных из Интернета явление
не новое. В основном оно распространено в неформальной среде (спамеры,
сквоттеры, кликеры, фишеры и др.) для сбора адресов электронной почты, данных о
доменах, воровстве сайтов и другим (нами руководят более возвышенные идеалы).
Парсинг (процесс сбора информации) веб-страниц в большинстве случаев сводится к
вырезанию необходимой информации из определённых тегов веб-страницы. Для работы
в интернете необходима связка LAMP (Linux,
Apache, MySQL, PHP)
или её аналог.
Реализовать парсер можно различными способами и
на разных языках для веб-программирования.
В качестве инструмента отладки использовалась серверная платформа DENWER
для дальнейшего размещения скриптов на бесплатный хостинг. В итоге база данных
состоит из следующих полей (Далее в формате «название»:«тип»[«длина если
имеется»]):
id:int(11)
– уникальный ключ.
date:timestamp
- информация о дате добавления вакансии. Поле необходимо для обновления базы
данных, для сравнения вновь добавляемых вакансий по дате и обеспечения
пополнения базы только новыми вакансиями.
name:char[200]
– информация о названии вакансии. Используется для обозначения вакансии, а
также при выявлении повторяющихся вакансий.
salary:int[15]
– данные о заработной плате. Необходимы для дальнейшего исследования степени
оплачиваемости знаний. Если в вакансии нет данных о заплате (указано, что
зарплата обсуждается при собеседовании), то в базу вносится ноль. Также если в
вакансии указан диапазон значений, то вычисляется среднее.
demand:text
– содержимое заполняется необходимыми навыками и требованиями. Заполнение
происходит без обработки, так, как присутствует на сайте. Необходимо для
структурного анализа востребованных на рынке труда знаний.
company:text
– строка представляющая информацию о фирме разместившей вакансию, это
необходимо для выявления повторений.
Важно заметить, что база была наполнена только
вакансиями, присутствующими на рынке труда города Красноярск и Красноярского
края, так как в Российской Федерации существует дифференциация рынков труда по
критерию зарплаты. Так данные, например, Московской области, где зарплаты по
сходным вакансиям гораздо выше, при смешении с данными Красноярского края
сильно портят картину. Подробнее в статье «Анализ рынка труда собственными
силами»[36]
Для автоматизации наполнения базы использовались
технологии парсинга. Описание технологии дано в следующем разделе.
После каждой работы парсера в базах данных была
проведена автоматическая чистка, после чего из базы были вакансии с одинаковыми
названиями, при этом названия компании совпадает и уникальный ключ ID
новой вакансии больше чем у старой.
Обработка базы осуществлялась средствами пакета phpMyAdmin
(сортировка, поиск, удаление), входящего в состав сборки сервера Denwer.
Подробнее за описанием средств phpMyAdmin можно обратится к
документам «Документация phpMyAdmin»[35] и «Все, что нужно - phpMyAdmin!»[34].
Здесь нужно отметить, что вакансии, где не
указана зарплата, из базы не удалялись. Они необходимы при анализе, для того
чтоб шире оценить критерий распространяемости знаний.
Данные собраны за пять лет: с 2009г. по 2014г. На
текущий момент по итогам процедуры сбора данных, чистки было набрано 615
вакансий.
Данные собирались с помощью трех парсеров. В общем
случае парсинг сводится к вырезанию из тегов веб-страниц необходимой
информации. Но так как теги и наполнение веб-страниц везде разное, то для
каждого отдельного сайта нужен отдельный парсер. Всего в ходе работы было
написано 3 парсера, для сбора информации с сайтов:
1) http://rabota.ngs24.ru/
2) http://www.kras-rabota.ru/
3) http://krasnoyarsk.rabota.ru/
Данные сайты выбирались исходя из их
наполненности. У сайта rabota.ngs24.ru
на текущий момент размещено более 5 тыс. вакансий, kras-rabota.ru – более 4 тыс. и более
1 тыс. на сайте krasnoyarsk.rabota.ru.
После обработки запроса получаем порядка 600
вакансий.
Для дальнейшей работы с вакансиями необходимо
разбить их по категориям. В каждой категории собраны вакансии, отвечающие
профессиональным стандартам в области информационных технологий. Всего
получилось выделить 11 основных категорий.
В таблице 1 представлено 11 категорий,
полученных путем разделения названия вакансий.
Таблица 1 – Категории вакансий
|
№ |
Название
категории |
Количество
вакансий |
|
1 |
Веб
специалист |
72 |
|
2 |
Программирование
на ЯВУ |
68 |
|
3 |
Системный
администратор |
45 |
|
4 |
Мобильные
специалисты |
13 |
|
5 |
1С
специалист |
71 |
|
6 |
SMM/SEO |
7 |
|
7 |
Монтажники |
15 |
|
8 |
Продажи |
73 |
|
9 |
Инженер |
67 |
|
10 |
Оператор |
19 |
|
11 |
Руководители |
18 |
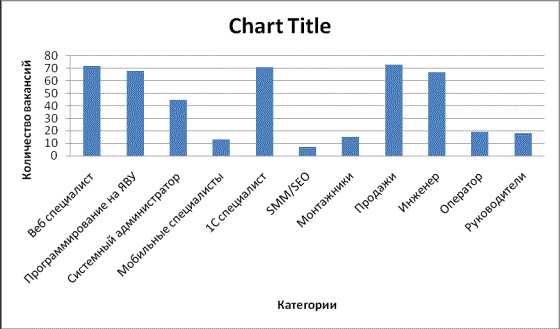
Рисунок 1- Диаграмма группировки данных по
количеству вакансий
Разработанная технология сбора данных в Интернет
позволит постоянно проводить анализ рынка труда ИТ-специалистов, исследовать
тенденции спроса на IT-специалистов. Более
подробный анализ вакансий позволит выделить знания, которыми должен обладать
ИТ-специалист по каждой категории, что необходимо для корректировки учебных
планов и рабочих программ для кафедр, выпускающих специалистов в области
информационных технологий.
Литература:
1 Стратегия развития отрасли информационных технологий
в российской федерации на 2014 - 2020 годы и на перспективу до 2025 года. Распоряжение
от 1 ноября 2013 г. № 2036-р. Москва, 2013
2 Гриценко, Е.М. Обзор развития технологий
создания web-приложений / Е.М. Гриценко, Н.В. Лачинова// Журнал «Образование и
наука без границ; Przemyl; Nauka i studia»2013. - № 4. – с. 66-74