Муравейко А.Ю.
Липецкий государственный технический
университет, Россия
Анализ возможности создания
альтернативных соединений таблиц в реляционных базах данных
В
современном мире, требующем оперативной обработки информации, широкое
распространение получили автоматизированные информационные системы (АИС), которые
по большей части основаны на реляционных системах управления базами данных
(СУБД): Oracle, MSSQL, MySQL и др. Для АИС является актуальной задача
минимизации времени получения информации (формирования отчетов, выборки данных с
выводом на экран). Очевидно, что время получения
информации в АИС прямо пропорционально времени выполнения запросов. Существующие подходы
оптимизации запросов направлены на улучшение запросов, содержащих инвариантную
(«жесткую») схему соединения таблиц [1,2]. Однако в базах данных (БД) сложных структур [4,5] при динамичном
изменении объема таблиц ранее запланированные варианты операций соединения с
течением времени могут оказаться не оптимальными в плане скорости их выполнения.
Так как классическая теория баз данных предполагает
инвариантную схему соединения таблиц, то для применения методики динамической оптимизации запросов на основе альтернативных
соединений [3, 7-9] в БД большинства существующих АИС необходимо сначала
создать альтернативные соединения. Для этого воспользуемся методикой внесения контролируемой избыточности [5,6], заключающейся в реализации следующих шагов:
1) установление иерархической цепочки таблиц [5,6] на основе анализа отдельных
связей между ними;
2) выбор альтернативных соединений, которые
будут созданы, например, путём анализа частоты выполнения запросов к таблицам,
удаленным друг от друга в иерархической цепочке;
3) модификация таблицы-потомка, включением
в ее структуру идентификатора таблицы-предка;
4) для уже существующих в БД записей заполнение
созданного связующего атрибута-идентификатора в таблице-потомке семантически
правильными значениями из таблицы-предка, создание «механизма» поддержания
целостности (актуальности наполнения созданного связующего
атрибута-идентификатора в таблице-потомке).
Рассмотрим возможность создания альтернативных
соединений на примере «АИС учета
штатных единиц образовательного учреждения» («АИС Штаты»), оперирующей с
данными в СУБД MySQL. Для анализа базы
данных необходимо узнать (считать) ее структуру. Для этого в СУБД MySQL можно
воспользоваться командами: «show databases» – получить список баз данных, «show
tables from <database>» – получить список таблиц в базе данных; «describe
<table>» – получить информацию о полях таблицы. Т.к. СУБД MySQL
реляционная, а связи между реляционными отношениями осуществляются путем
дублирования атрибутов, то связи между таблицами устанавливаются путем поиска совпадения
имени первичного ключа одной таблицы и имени поля, не являющегося первичным
ключом в других таблицах БД. Таким образом, получаем ориентированные связи от
«главной» таблицы к «подчиненным» (рис.1).
После установления структуры БД можно
приступить к поиску иерархических цепочек. Рассмотрим в качестве начала
иерархической цепочки таблицу dol (рис.2, рис.3). В таблице shrtimework
сходятся 2 иерархические цепочки, идущие из таблицы dol. Они имеют разную
семантику: 1-ая – (dol→shr→shrrest→ shrtimework) – должность
штатной единицы, изменяемой на время отпуска без содержания, 2-ая – (dol→shr→shrtimework)
– должность штатной единицы, на которую произошла замена на время отпуска без
содержания. Исходя из предметной области данная манипуляция (изменение штатной
единицы на время отпуска без содержания) может происходить в пределах одной должности
(например, с отличием в финансировании), но чаще должности меняются на другие, соответственно
внесение двух полей под значения dol_cod может привести к нарушению целостности
данных. Видимо, необходимо запретить внесение контролируемой избыточности в
данном случае для пресечения возможности нарушения целостности данных.
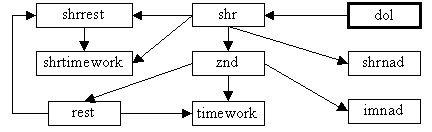
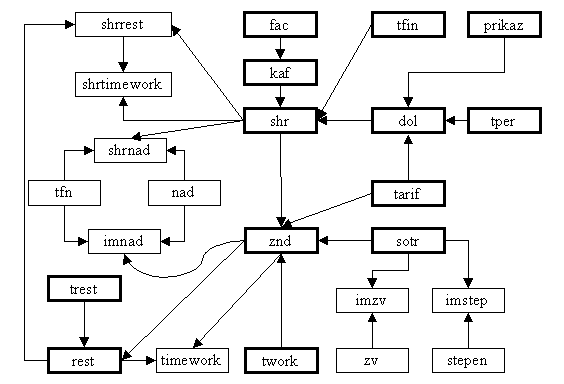
Рис.1. Схема иерархических связей для БД «АИС Штаты». Жирным выделены таблицы,
которые могут стать начальными («главными таблицами») для дополнительных
соединений
Рис.2. Схема иерархических связей для таблицы DOL
В таблице shrrest сходятся две
иерархические цепочки, идущие из таблицы dol. Они имеют одинаковую семантику: 1
– (dol→shr→shrrest), 2 – (dol→shr→
znd→rest→shrrest) – должность штатной единицы, изменяемой на время
отпуска без содержания. Казалось бы, можно внести одно поле dol_cod, однако
возникает вопрос о выборе маршрута для заполнения поля. Можно выбрать тот,
который короче. Ну а главный вопрос: «Как научить ЭВМ понимать одинаковая
семантика у сходящихся цепочек в таблице (например, таблица shrrest) или разная
(таблица shrtimework)?». На данном этапе предлагается отложить решение этой
проблемы путем исключения из анализа всех таблиц, в которых сходятся иерархические
цепочки от одной и той же главной таблицы (в рассматриваемом случае таблица dol),
поэтому отбросим из рассмотрения внесение в БД дополнительных связей таблицы dol
и таблиц shrrest, shrtimework, timework (рис.4).
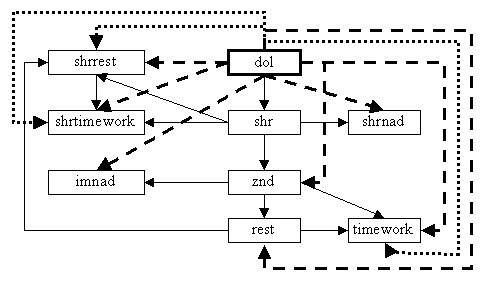
Рис.3. Варианты внесения дополнительных связей с таблицей DOL
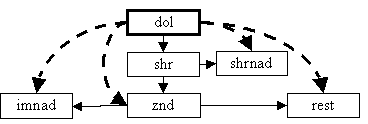
Рис.4. Варианты внесения дополнительных связей с таблицей DOL после обработки
Для большой базы данных поиск
иерархических цепочек вручную долог и утомителен, поэтому возникает задача
автоматизации данного процесса. Для решения задачи поиска иерархических цепочек
предложим следующий алгоритм (исходными данными для алгоритма будут матрица
смежности графа структуры БД, который получается путем обозначения таблиц
вершинами, а связей между таблицами – дугами графа (табл.1), а также заданная
вершина (таблица), для которой требуется создать иерархические цепочки (табл.2)):
Шаг 0. Создаем путь нулевого уровня из самой
заданной вершины. Флаг перспективности данного пути выставляем в значение
истина.
Шаг 1. Создание путей нового уровня.
Для всех маршрутов предыдущего уровня не помеченных
как «тупиковые» (флаг перспективности равен истина) по правилу обхода в ширину
создаем пути (цепочки в ориентированном графе, выходящие из заданной вершины.)
Путь следующего уровня получается добавлением к пути дуги исходящей из
«конечной вершины» пути и инцидентной ей вершины.
Шаг 2. Анализ путей нового уровня.
Выполняем проверку на то, что новая «конечная вершина»
(вершина, которой заканчивается путь) уже была «конечной вершиной» в ранее созданных
путях. Если есть такие случаи, то пути, которые заканчиваются в этой вершине,
помечаем как «тупиковые» (флаг перспективности равен ложь) и дальше эти пути не
рассматриваем.
Шаг 3. Если есть пути, для которых полустепень
исхода для «конечной вершины» пути больше 0 (то есть из нее есть исходящие
дуги) и путь не помечен как «тупиковый», то переходим на Шаг 1, иначе Конец
алгоритма.
Таблица 1. Переход от таблиц к
вершинам графа структуры БД
|
№ вер-ши-ны |
Название таблицы |
Комментарий |
№ вер-ши-ны |
Название таблицы |
Комментарий |
|
0 |
dol |
Должность |
12 |
shrtimework |
Штатная единица, измененная на время отпуска без содержания |
|
1 |
fac |
Факультет (подразделение первого уровня) |
13 |
sotr |
Сотрудник |
|
2 |
imnad |
Фактическая надбавка |
14 |
stepen |
Ученая степень |
|
3 |
imstep |
Фактическая ученая степень |
15 |
tarif |
Тариф |
|
4 |
imzv |
Фактическое ученое звание |
16 |
tfin |
Финансирование |
|
5 |
kaf |
Кафедра (подразделение второго уровня) |
17 |
tfn |
Финансирование надбавки |
|
6 |
nad |
Надбавка |
18 |
timework |
Заменяющие занимаемые должности |
|
7 |
prikaz |
Приказ о присвоении должности профессионально-квалификационной
группы |
19 |
tper |
Тип персонала |
|
8 |
rest |
Отпуск без содержания |
20 |
trest |
Тип отпуска без содержания |
|
9 |
shr |
Штатная единица |
21 |
twork |
Тип работы |
|
10 |
shrnad |
Плановая надбавка |
22 |
znd |
Занимаемая должность |
|
11 |
shrrest |
Штатная единица в отпуске без содержания |
23 |
zv |
Ученое звание |
Результаты работы
алгоритма для таблицы dol
«АИС Штаты» приведены в таблице 2 и соответствуют результату, полученному ранее
вручную (рис.4).
Таблица 2. Результат работы алгоритма для таблицы dol
|
Промежуточные результаты: |
Итоговые результаты |
||
|
№ |
Флаг |
Путь на графе |
Путь в БД |
|
0 |
0 |
0 |
|
|
1 |
0 |
0→9 |
|
|
2 |
1 |
0→9→10 |
dol→shr→shrnad |
|
3 |
0 |
0→9→11 |
|
|
4 |
0 |
0→9→12 |
|
|
5 |
1 |
0→9→22 |
dol→shr→znd |
|
6 |
0 |
0→9→11→12 |
|
|
7 |
1 |
0→9→22→2 |
dol→shr→znd→imnad |
|
8 |
1 |
0→9→22→8 |
dol→shr→znd→rest |
|
9 |
0 |
0→9→22→18 |
|
|
10 |
0 |
0→9→22→8→11 |
|
|
11 |
0 |
0→9→22→8→18 |
|
Вывод:
разработан метод поиска иерархических цепочек таблиц, позволяющий провести
анализ возможности создания альтернативных соединений таблиц в реляционных
базах данных.
[Работа поддержана грантом РФФИ № 11-07-97537-р_центр_а]
Литература:
1. Гарсиа-Молина Г., Ульман Д., Уидом Д. Системы баз данных. Полный курс. Пер. с англ.- М.: Издательский дом «Вильямс», 2003 – 1088 с.
2. Дейт К.Дж. Введение в системы баз данных, 7-е издание : Пер.с англ – М.: Издательский дом «Вильямс», 2002 – 1072 с.
3. Муравейко А.Ю., Дятчина Д.В., Погодаев А.К. Оптимизация альтернативных соединений в запросах реляционных информационных систем на основе теории графов // Сложные системы управления и менеджмент качества CCSQM’2007: Сборник трудов Международной научной конференции / Под ред. Проф Ю.И. Ерёменко. – Старый Оскол: ООО «ТНТ», 2007.- с.90-93
4. Муравейко А.Ю., Погодаев А.К. Оптимизация соединения таблиц в сложной структуре организации данных /Молодые ученые- производству. Сборник научных трудов региональной конференции. – Старый Оскол: СТИ МИСиС, 2005. с.189-192
5. Муравейко А.Ю., Погодаев А.К. Метод альтернативных соединений таблиц баз данных в информационных системах образовательных учреждений / Научно-технический журнал «Образовательные технологии», 2005, №2(15). -Воронеж, Научная книга. с.18-21
6. Муравейко А.Ю., Погодаев А.К. Оптимизация альтернативных соединений реляционных таблиц баз данных в управлении организации //Теория активных систем/ Труды международной научно-практической конф.- М. ИПУ РАН, 2005 с.141-143
7. Погодаев А.К., Муравейко А.Ю., Дятчина Д.В. Алгоритм альтернативного соединения для оптимизации запросов в реляционных системах / Журнал «Вести высших учебных заведений Черноземья», 2006, №1 (3). - Липецк, ЛГТУ с.13-15
8. Погодаев А.К., Муравейко А.Ю., Дятчина Д.В. Альтернативные соединения таблиц баз данных / Научно-технический журнал «Системы управления и информационные технологии», 2005, № 5(22). – Воронеж, Научная книга. с.99-102
9. Погодаев А.К., Муравейко А.Ю., Дятчина Д.В. Метод оптимизации запросов на основе альтернативного соединения таблиц баз данных для информационных систем предприятий / Известия ТулГУ. Серия: Машиноведение, системы приводов и детали машин. Спец. вып.- Тула: Изд-во ТулГУ, 2006. с.331-337