Математика/5. Математическое
моделирование
К.т.н. Желтов П.В.,
Семенов В.И.
Чувашский государственный университет,
Россия
Методика определения границ между гласными и согласными звуками речи с
применением непрерывного быстрого вейвлет-преобразования
Сложность проблемы распознавания речи
связана с вариативностью ее основных параметров, на которые влияет множество
факторов. Длительность, громкость и темп речи изменяются в широких пределах. При
этом различные звуки речи растягиваются или сжимаются не одинаково. Например,
гласные изменяются значительно сильнее, чем согласные, при увеличении
длительности произношения слова. Одна из основных трудностей при распознавании
состоит в неопределенной временной организации речевого сигнала. Очевидно, что
точность распознавания слов и предложений существенно зависит от точности
определения границ звуков речи. Для того, чтобы сравнить с эталоном, надо путем
деформации оси времени совместить участки, соответствующие одним и тем же
звукам. Для нелинейного согласования речи используются методы динамического
программирования (алгоритм динамического искажения времени) и марковского
моделирования.
В работе предлагается
методика определения границ между гласными и согласными звуками речи на
основе непрерывного быстрого вейвлет-преобразования (ВП).
Вейвлет-преобразование одномерного
сигнала S(t) – это его представление в виде интеграла Фурье
по системе базисных функций ψ(t):
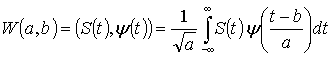
Вейвлет-спектр W(a,b) (масштабно-временной
спектр) в отличие от Фурье-спектра является функцией двух аргументов. Первый
аргумент a (временной
масштаб) аналогичен периоду осцилляций,
второй аргумент b – смещению сигнала по оси времени. Малые значения
a
соответствуют высоким частотам,
большие значения a – низким частотам. ВП обеспечивает двумерную развертку исследуемого одномерного
сигнала. Спектр W(а,b) одномерного сигнала представляет собой поверхность в
трехмерном пространстве. Трехмерное изображение спектра позволяет анализировать свойства сигнала S(t) одновременно
в физическом и в частотном
пространствах. Вейвлет-преобразование обладает подвижным частотно-временным окном,
одинаково хорошо выявляет низкочастотные и
высокочастотные характеристики сигналов.
Непрерывное вейвлет-преобразование выполняется, как
правило, прямым численным интегрированием [1], что для больших временных
последовательностей занимает большое время. Для вычисления непрерывного вейвлет-преобразования
нами разработаны алгоритмы, которые позволяют во много раз увеличить
быстродействие за счет применения быстрого преобразования Фурье (БПФ). [2,3,4,5,6].
В качестве «материнской» функции нами
выбрана симметричная, четная, гладкая функция МНАТ(t), называемая «мексиканская шляпа», которая
конструируется на основе второй производной функции Гаусса. Для записи, воспроизведения, редактирования
сэмплов и сохранения в текстовом файле используется звуковой редактор. Слово
или предложение записывается в режиме «моно», разрешение – 16 бит, частота дискретизации – 8000 герц,
время записи 4 с. Сохраненные данные
используются для преобразования в вейвлет-спектр W(a,b) исследуемых сэмплов S(t).
Для дискретной временной
последовательности S(i) (i = 32768) вычисляются вейвлет-коэффициенты (функции) W(а,b), где b меняется от 1 до 32768. Полученные вейвлет-коэффициенты
(функции) W(а,b)
разбиваются на сегменты фиксированной длительности (n = 128). Общее число сегментов 256. В каждом сегменте вычисляются
коэффициенты Фурье c(i), s(i)
функций W(а,b), используя БПФ. Используется простейшая весовая функция (окно) Дирихле.
Влияние на спектр других весовых функций (Хемминга, Бартлетта, Ханна и других)
не рассматривалось. По формуле
![]()
находится Фурье-спектр функций
W(а, b) каждого
сегмента.
Для нахождения границ между гласными и согласными буквами в словах вычисляется энергия
сегментов функций W(1,b), W(2,b) и
исследуемого слова S(t). Энергия сегментов вычисляются по формуле:
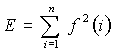 .
.
Обозначим энергию сегментов вейвлет-преобразования W(1,b), W(2,b) и исследуемого слова S(t) функциями E1(n), E2(n) и E3(n), где n меняется
от 1 до 64.
Результаты анализа показывают, что
энергия сегментов гласных звуков речи для W(1,b), W(2,b) выделяется в виде максимальных пиков, а энергия
согласных всегда ниже, чем энергия гласных звуков речи. Энергия сегментов
шипящих, свистящих звуков в E1(n) выделяются в виде максимальных пиков, в E2(n) и E3(n) – в виде
минимумов. Для нахождения местоположения гласных звуков речи нормируются
энергии сегментов E2(n), E3(n), вычисляется
их сумма, и вычисляется вейвлет-преобразование W1(4, b), с
масштабным коэффициентом a =
4, где b меняется от 1 до
256. Коэффициент a может меняться от 3 до 8. Таким образом, если
слово содержит одну гласную букву, то выделяется один положительный максимум.
Если две гласные буквы, то – два положительных максимума и так далее [7,8,9].
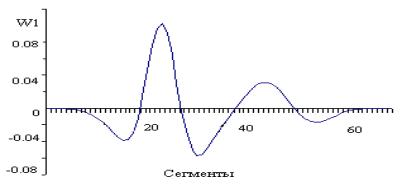
На рисунке 1 представлена функция W1(4,b) слова СИГНАЛ. Положительным значениям функции W1(4,b) соответствуют гласные звуки речи И, А.
.
Рис. 1.
Функция W1(4, b) слова СИГНАЛ.
Минимальнымм значениям – звуки
речи С (сегменты 13-19), Г, Н (сегменты 28-39), Л (сегменты 50-57). Если
последними буквами в слове являются К или Т, то они выделяются в виде
максимальных пиков, т. к. впереди этих звуков речи обычно есть пауза. Граница
между гласными и согласными звуками речи определяются с точностью до 2-3
сегментов.
Детальную картину расположения гласных и
согласных звуков речи в слове или предложении можно увидеть, исследуя
зависимость энергии сегментов вейвлет-спектра от масштабного коэффициента a. На рис. 2
представлен график зависимости энергии сегментов Е от масштабного коэффициента а
вейвлет-преобразования W(а,b) слова
СЕКУНДА. На рис. 2 масштабный коэффициент а
меняется от 1 до 50 с шагом 1.
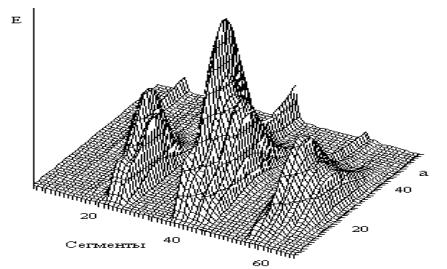
Рис. 2. Зависимость энергия сегментов вейвлет-преобразования слова СЕКУНДА от масштабного коэффициента a.
На графике видно, в
каких сегментах выделяются гласные звуки Е, У, А и согласные звуки К, Н, Д.
Гласные и согласные звуки имеют
максимальные энергии при средних значениях а.
Энергия сегментов Н (сегменты 40-47) меньше энергии гласных звуков речи, но значительно выше энергии
шума. Звуки речи К и Д выделяются при больших значениях а (сегменты 30-33 и 48-51). При вычислении энергии сегментов вейвлет-преобразования
W(а,b) с масштабным коэффициентом а меньше 1 шипящий звук речи С выделяется наравне с гласными. Такая
закономерность наблюдается при многократном повторении и не зависит от
случайных факторов. Шипящие и свистящие звуки речи при малых значениях масштабного
коэффициента а имеют энергию W(а,b) сравнимую
с энергией гласных букв. При средних значениях а они имеют энергию на уровне шума. Можно заметить, что фонемы имеют отличающуюся друг от друга
зависимость энергии W(а,b) от масштабного коэффициента а, при использовании различного
диапазона частот. Это позволяет выделять по отдельности две или три рядом
стоящие гласные фонемы. Так же можно отделить друг от друга согласные звуки
речи, если они расположены рядом.
Например, звуки П, Т, К выделяются при больших а в виде кратковременного пика. Звуки речи М, Н, Л заметны
лишь при средних значениях масштабного
множителя а и имеют энергию W(а, b) меньшую, чем
гласные звуки.
Для распознавания слова или
предложения, в интервале, где выделяются гласные звуки речи, подсчитывается количество распознанных букв А (т.е. количество сегментов в которых
выделилось буква А по сформулированному признаку). Аналогично, для других
гласных звуков по отдельности находится количество распознанных букв. Из них
выделяются 3 гласные буквы, для которых
эти числа наибольшие. Так же подсчитываются
согласные и шипящие буквы в интервале, где W1(4,b) имеет отрицательное значение. Из них выделяются 3
буквы, также как для гласных букв. Интервал для подсчета согласных букв выбирается
шире, чтобы учитывать погрешность определения границ. По распознанным буквам
формируется слово или предложение по определенному алгоритму.
Литература:
1.
Астафьева Н.М. Вейвлет-анализ: Основы теории и
принципы применения. // УФН, т. 166, № 11, ноябрь, С. 1145 – 1170.
2. Свидетельство об официальной регистрации программ
для ЭВМ №2007615024. Непрерывное быстрое вейвлет-преобразование/ Семенов В.И.;
зарегистрировано в Реестре программ для ЭВМ
4 декабря 2007 г.
3.
Свидетельство о государственной регистрации программы для ЭВМ № 2009616896.
Непрерывное быстрое m + 1 шаговое вейвлет-преобразование / Семенов В.И.,
Желтов П.В.; зарегистрировано в Реестре программ для ЭВМ 11 декабря 2009 г.
4.
Свидетельство о государственной регистрации программы для ЭВМ № 2010610456.
Непрерывное быстрое двухшаговое
вейвлет-преобразование / Семенов В.И., Желтов П.В.; зарегистрировано в
Реестре программ для ЭВМ 11 января 2010
г.
5.
Свидетельство о государственной регистрации программы для ЭВМ № 2010616103.
Непрерывное сверхбыстрое вейвлет-преобразование / Семенов В.И..;
зарегистрировано в Реестре программ для ЭВМ
16 сентября 2010 г.
6 Свидетельство
о государственной регистрации программы для ЭВМ № 2011610159. Непрерывное
быстрое не избыточное вейвлет-преобразование / Семенов В.И.; зарегистрировано в
Реестре программ для ЭВМ 11 января 2011
г.
7. Желтов
П.В. Семенов В.И. Выделение границы между
гласными и согласными фонемами при
распознавании речи. // Сборник научных трудов. Выпуск 1, Казань: Изд-во Казан.
гос. техн. ун-та, 2008, 80с.
8.
Желтов П.В. Семенов В.И. Распознавание
речи на основе вейвлет-преобразования. // Чуваш.гос.ун-т.-Чебоксары,
2008.-16с.-Деп. в ВИНИТИ РАН 29.02.08, №174-В2008.
9. Патент № 2008141557/09(053961). Способ
распознавания ключевых слов в слитной речи. / Желтов П.В., Семенов В.И.