Современные информационные системы / 2. Вычислительная техника и
программирование
Kryuchin O.V., Rakitin A.A.
Tambov State University named after
G.R. Derzhavin, Russia
The
information processes for the function coefficient minimization efficiency
increasing using quasi-Newton methods
In optimization theory quasi-Newton methods are algorithms for finding a
local maximum and minimum of function
|
|
(1) |
where ![]() is the minimized vector.
Quasi-Newton methods are based on the Newton method to find the stationary
point of a function (1), where the gradient is equal to 0. Newton method
assumes that function (1) can be locally approximated as a quadratic in the
region around the optimum and uses the first
is the minimized vector.
Quasi-Newton methods are based on the Newton method to find the stationary
point of a function (1), where the gradient is equal to 0. Newton method
assumes that function (1) can be locally approximated as a quadratic in the
region around the optimum and uses the first
|
|
(2) |
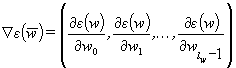
and the second
derivatives
|
|
(3) |
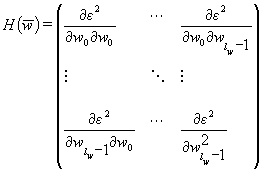
to find the
stationary point. In formulas (2)-(3) ![]() is the vector
is the vector ![]() size. In quasi-Newton methods
Hessian matrix (3) to be minimized does not need to be computed. The Hessian is
updated by analyzing successive gradient vectors instead. Quasi-Newton methods
are a generalization of the secant method to find the first derivative root for
multidimensional problems. In multi-dimensions the secant equation is under-determined,
and quasi-Newton methods differ in how they constrain the solution, typically
by adding a simple low-rank update to the current estimate of the Hessian [1].
size. In quasi-Newton methods
Hessian matrix (3) to be minimized does not need to be computed. The Hessian is
updated by analyzing successive gradient vectors instead. Quasi-Newton methods
are a generalization of the secant method to find the first derivative root for
multidimensional problems. In multi-dimensions the secant equation is under-determined,
and quasi-Newton methods differ in how they constrain the solution, typically
by adding a simple low-rank update to the current estimate of the Hessian [1].
This paper aim is to develop quasi-Newton method which can be used with
the large information resource elements (IR-elements) number and to do
experiments for checking the developed algorithms efficiency.
As in Newton method
|
|
(4) |
thus we can
calculate new vector ![]() values by formula
values by formula
|
|
(5) |
where ![]() is the approximate Hessian
inverse [2].
is the approximate Hessian
inverse [2].
If we have n IR-elements (for example a computer cluster or a
network computing) so as it done by the classic parallel gradient algorithms
one IR-element (which will calling “lead”) calculates ![]() elements of a gradient and a
gradient changing and other IR-elements calculate
elements of a gradient and a
gradient changing and other IR-elements calculate ![]() elements [3]. We can divide
matrix
elements [3]. We can divide
matrix ![]() similarly and so we can develop
few information process steps:
similarly and so we can develop
few information process steps:
1.
calculating parts of gradient ![]() , gradient changing
, gradient changing ![]() and matrix
and matrix ![]() by the different IR-elements and
passing the calculated gradient and the gradient changing by non-lead
IR-elements to the lead;
by the different IR-elements and
passing the calculated gradient and the gradient changing by non-lead
IR-elements to the lead;
2.
passing gradient changing ![]() by the lead IR-element to other;
by the lead IR-element to other;
3.
each non-lead IR-element calculates matrix
|
|
(6) |
rows and vector
|
|
(7) |
elements; the lead IR-element calculates scalar
|
|
(8) |
4.
passing calculated matrix ![]() and vector
and vector ![]() elements by non-lead IR-element
to the lead;
elements by non-lead IR-element
to the lead;
5.
passing formed matrix ![]() and vector
and vector ![]() elements by the lead IR-element
to non-lead;
elements by the lead IR-element
to non-lead;
6.
the lead IR-element calculates
|
|
(9) |
|
|
(10) |
and
|
|
(11) |
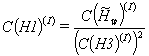
at that time other IR-elements calculate
|
|
(12) |
|
|
(13) |
and
|
|
(14) |
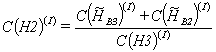
7.
non-lead IR-elements sends to the lead matrix ![]() ;
;
8.
the lead IR-element calculates matrix ![]() and new weights and sends it to
other IR-elements.
and new weights and sends it to
other IR-elements.
For checking the developed algorithms efficient we have done an experiment.
The efficiency coefficient which was calculated by formula
|
|
(15) |
(where t
is serial algorithm time expenses and ![]() is parallel algorithm time expenses
with n IR-elements usage) is about 80% So we can see that parallel
quasi-Newton algorithms are very efficient and can be used for the function
minimization.
is parallel algorithm time expenses
with n IR-elements usage) is about 80% So we can see that parallel
quasi-Newton algorithms are very efficient and can be used for the function
minimization.
Reference:
1.
William C. Davidon, Variable Metric Method for Minimization // SIOPT,
1991 – Vol. 1, Issue 1 – P. 1-17.
2.
Fletcher R. A New Approach to Variable Metric Algorithms // Computer Journal,
1970 – Vol. 13, Issue 3 – P. 317-322.
3.
Kryuchin O.V., Arzamastsev A.A., Troitzsch K.G. A universal simulator
based on artificial neural networks for computer clusters // Arbeitsberichte
aus dem Fachbereich Informatik , № 2/2011,
http://www.uni-koblenz.de/~fb4reports/2011/2011_02_Arbeitsberichte.pdf