Сучасні
інформаційні технології\1. Комп`ютерна інженерія
К.т.н. Маслій Р. В., Дрозд І. М.
Вінницький
національний технічний університет, Україна
Класифікація
зображень з використанням дерев рішень
В роботі пропонується підхід до класифікації зображень з використанням
локальних бінарних шаблонів у якості дескриптора зображень з метою отримання
вектору ознак зображення та метод випадкових лісів у якості класифікатора.
Розглянемо особливості локальних бінарних шаблонів та методу випадкових лісів.
Локальний бінарний шаблон (ЛБШ) представляє собою опис околу пікселя
зображення у двійковій формі. Оператор ЛБШ, що застосовується до пікселя
зображення використовує вісім пікселів околу, приймаючи центральний піксель у якості порогу. Пікселі, які мають значення більші, ніж
центральний піксель (чи дорівнюють йому), приймають значення «1», ті, які,
менше центрального, приймають значення «0». Таким чином утворюється
восьмирозрядний бінарний код, який описує окіл пікселя [1].
Приклад роботи оператора ЛБШ над напівтоновим зображенням показано на
рисунку 1.
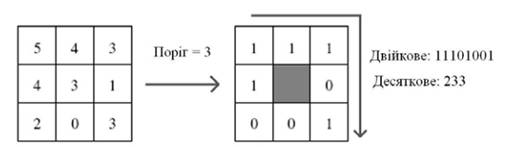
Рисунок 1 – Приклад роботи ЛБШ оператора
У якості вектора ознак зображення для класифікатора пропонується
використати гістограму ЛБШ, яка представляє собою розподіл значень ЛБШ, що
отримані зі всього зображення. Гістограма містить 256 стовпчиків, кожен з яких
відповідає за певне значення ЛБШ. Після оброблення кожного пікселя зображення
на одиницю збільшується відповідний стовпчик зображення. Наприклад, після
обчислення ЛБШ для околу пікселя представленого на рисунку 1, стовпчик
гістограми ЛБШ під номером 233 збільшився на 1. Після оброблення всього
зображення значення гістограми ЛБШ нормалізується.
Дерево
рішень – це один з методів автоматичного аналізу великих масивів даних. Ідея, яка лежить в основі методу дерева рішень,
полягає у розбитті множин можливих значень вектора ознак (незалежних змінних)
на множини, які не перетинаються і підгонці простої моделі для кожної такої
множини [2].
Метод випадкових лісів заснований на побудові великого числа (ансамблю)
дерев рішень (перший параметр методу), кожне з яких будується за вибіркою, яка
отримується з вихідної навчальної вибірки за допомогою бутстрепа (тобто вибірки
з поверненням). На відміну від класичних алгоритмів побудови дерев рішень в
методі випадкових лісів при побудові кожного дерева на стадіях розщеплення
вершин використовується тільки фіксоване число випадково відібраних ознак
навчальної вибірки (другий параметр методу) і будується повне дерево (без
усічення), тобто кожен лист дерева містить спостереження тільки одного класу. Класифікація
здійснюється за допомогою голосування класифікаторів, що визначаються окремими
деревами, а оцінка регресії – усередненням оцінок регресії всіх дерев.
Ймовірність коректної класифікації ансамблів класифікаторів істотно залежить
від того, наскільки корельовані їх рішення. А саме, чим різноманітніші
класифікатори ансамблю (менша корельованість їх рішень), тим вище ймовірність
коректної класифікації [3].
Для досліджень був створений набір аерофотозображень з бази UCMerced,
що складається з 12 класів по 90 зображень у кожному класі. Це такі класи як:
сільське господарство (agricultural), літаки (airplane), будівлі (buildings), гавань (harbor),
ліс (forest), автострада (freeway), автостоянка (parkinglot),
житловий район (mediumresidential), перехрестя (intersection), естакада (overpass),
річки (river), порожня дорога (runway).
Для дослідження були встановлені такі параметри випадкового лісу: кількість
дерев – 200, mtry
– 16. Після проведення досліджень у середовищі RGui
були отримані наступні результати для 12 класів (рисунок 2).
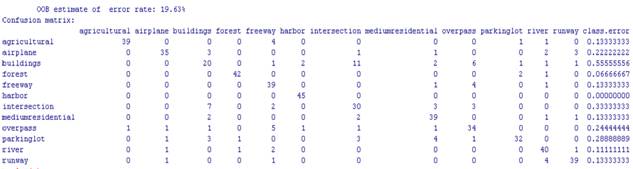
Рисунок 2 – Помилка out-of-bag
для набору аерофотозображень з бази UCMerced
Запропонований
підхід дозволяє показати досить високий рівень класифікації для зображень
класів, які мають виражену текстуру (наприклад, клас forest –
6.6% помилки out-of-bag, клас
river – 11.1%
помилки out-of-bag).
Але у випадку зображень класів, які містять в собі об’єкти різної текстури рівень
класифікації набагато нижчий (наприклад, клас buildings –
55.5% помилки out-of-bag).
Перевагою запропонованого підходу є швидкий етап тренування класифікатора в
порівнянні, наприклад, з нейронними мережами.
Литература:
1. Маслій Р.В. Використання локальних бінарних шаблонів для розпізнавання
облич на напівтонових зображеннях / Маслій Р.В. // Наукові праці ВНТУ, 2008. – Т. 4. – C. 6.
2. Маслій Р.В. Застосування випадкових лісів для
класифікації даних / Р.В. Маслій, О.Ю. Філіпчук // Veda a technologie: krok do budoucnosti–2014. – 2014. Praha. – Dfl. 30. – C. 24-27.
3. Філіпчук О. Ю. Застосування
випадкових лісів в
задачах класифікації зображень [Електронний ресурс] – Режим доступу: http://conf.vntu.edu.ua/allvntu/2015/inaeksu/txt/filipchuk.pdf.