Петренко А.С., Червинський
В.В.
Донецький
національний технічний університет, Україна
Алгоритм балансування
навантаження при розподілі запитів до серверів віддалених IP-мереж
Екстенсивне
зростання трафіку у мережі Інтернет призводить до збільшення кількості запитів
до популярних сайтів. У зв’язку з цим користувачі можуть відчувати затримки при
доступі до інформації.
Зміна
інфраструктури сайту на локальний кластер не забезпечує повного вирішення
проблеми так як канал між кластером та глобальною мережею може стати вузьким
місцем даної інфраструктури.
Більш
ефективним вирішенням є розподіл серверів географічно так, щоб вони
розташовувалися в окремих мережах. Роль балансування навантаження у таких
мережах зростає, оскільки об’єкт, що розподіляє запити, може здійснювати цей
процес на базі як загрузки мережі та серверів, так й на базі відстані між
клієнтом та серверами.
Система балансування
навантаження повинна виконувати наступні задачі: моніторинг стану серверів та
мережевого обладнання, вибір сервера, який буде відповідати на запит клієнта та
управління трафіком між клієнтом і сервером.Ефективність системи балансування
навантаження залежить від алгоритму розподілу запитів. Існуючі алгоритми
балансування навантаження поділяються на статичні та динамічні. В останньому
випадку розподілювач навантаження здійснює періодичний моніторинг стану
серверів та обирає, той, що підходить найбільш для обслуговування конкретного
запиту.
К статичним
дисциплінам відносяться Random та Round-Robin (RR). У Random
сервер обирається випадковим чином за допомогою
рівномірного розподілу. Дисципліна Round-Robin є
найвідомішою та найбільш поширеною та реалізує принцип циклічного перебору – i-ий запит направляється на сервер з індексом, що дорівнює
результату цілочисельного ділення i на кількість серверів. До динамічних дисциплін відносяться: Weighted Round-Robin, Least Loaded (LL) та Least Connected
(LC). Новий алгоритм буде порівнюватися саме з Round-Robin та
LL, як найбільш розповсюдженими.
Та всі зазначені алгоритми не враховують стану каналу зв’язку до серверу,
що не припустимо в глобальних мережах та враховано у алгоритмі, що
запропоновується у даній статті.
Модель, у якій будуть застосовуватися алгоритми складає джерела запитів,
пристрій балансування, канали зв’язку та сервера.
Сервера
моделюються за трирівневою схемою та мають наступний алгоритм обробки
клієнтських запитів: якщо запитується статична сторінка, що зберігається на
сервері, то web-сервер одразу посилає клієнту HTTP-відповідь. Якщо запитується
динамічна сторінка, то запит передається на обробку до сервера додатків. Якщо
потребується отримання або оновлення інформації з бази даних, то сервер
додатків звертається до відповідного серверу баз даних. Відповідь сервера баз
даних посилається на сервер додатків, який, у свою чергу, посилає відповідь на Web-сервер, задача
якого - генерація HTTP-відповіді та її
передача клієнту.
Балансування навантаження виконується
розподіленим алгоритмом, що знаходиться на спеціальних пристроях – диспетчерах.
Диспетчери мають однакову anycast-адресу
та анонсують її DNS-серверам. DNS-сервер повертає клієнтам саме anycast-адресу, таким чином запит одразу надходить до
найближчого диспетчеру.
Кінцеві користувачі моделюються декількома
джерелами запитів. Інтенсивності надходження запитів характеризується
самоподібним (α = 1,) розподілом Парето з параметром Херста Н=0.6.
Самі запити не є однорідними,
кожен має параметр обчислювальної складності. Цей показник є абстрактним, та
характеризує частку процесорних ресурсв, що необхідно задіяти для обробки запиту,
генерації та передачі у канал відповіді. Складність розподілюється згідно закону Парето, що визначає дуже великий рівень
дисперсії. Для розмірів файлів, типовими є значення α у діапазонні від 1.1
до 1.3 [1]. Розподіл є обмеженим, так як на реальних серверах складність запиту має
певне максимальне значення.
На практиці сервісний час, який потребує кожен
запит на кожному віддаленому сервері не може бути відомий, проте, він
представляє з себе випадкову величину, що залежить від параметрів серверних
ресурсів та потоку запитів. Аналіз літературних джерел [2] показує, що ключовий вплив на цю величину оказує
поточна утилізація сервера W:
![]()
де ![]() – тривалість обробки самого запиту.
– тривалість обробки самого запиту.
Диспетчер обирає з пулу серверів той, на який буде
направлятися кожен конкретний запит. Задачу цього пристрою можна описати як
мінімізацію комплексної метрики, що запропонована у минулому розділі:
![]()
де τканалу – мережева затримка між
сервером та користувачем (one way end to end latency), τобробки – сервісний час для
заданого запиту.
Задача обчислення затримки між кожним користувачем
сайту та кожним з серверів потребує гігантських накладних витрат та привнесе
додаткову затримку у роботу алгоритму, метою якого є мінімізація затримки. Тому
реально користувачі кластерізуються на деякому масштабі – наприклад на рівні
автономної системи (AS)
та затримка τканалу розраховується для AS.
Пристрій балансування отримує потрібні значення 2τканал завдяки сервісу
періодичного ping-ування шлюзів AS. τобробки
є доступним з системного монітору серверної операційної системи та також
періодично посилається кожним сервером. Моделювання роботи алгоритмів
відбувається у пакеті AnyLogic. Результуючі значення параметру середньої
затримки обробки запиту наведено на рис. 1.
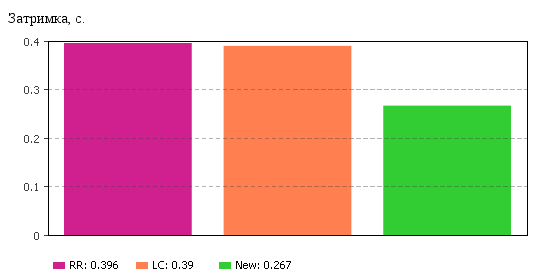
Рисунок 1 – Середня затримка обробки запиту
Висновки. У статті було запропоновано методику
для підвищення якості надання послуг операторами зв’язку та
контент-провайдерами за рахунок впровадження алгоритму балансування
навантаження. Запропонований алгоритм розподілює запити таким чином, щоб
мінімізувати загальну затримку, яку відчувають клієнти, результатом є зменшення
очікування на 129 та 123 мс відповідно до RR
та LC алгоритмів.
Література:
1.
Crovella,
M.E., Bestavros, A.: A self-similarity
in World Wide Web traffic: evidence and possible causes. IEEE/ACM Transactions
on Networking 5(6) (1997).
2. Лихтциндер Б.Я., Кузякин М.А., Росляков А.В., Фомичев С.М. Интеллектуальные сети связи. – М.: Эко-Трендз, 2000.