Современные
информационные технологии / 3. Программное обеспечение
К.т.н. Гусев М.Н.
ФГУП НИИ «Квант», Санкт-Петербург, Россия
michael.n.gusev@gmail.com
Д.т.н., проф. Дегтярев В.М.
Санкт-Петербургский государственный университет
телекоммуникаций им. проф. М.А. Бонч-Бруевича, Санкт-Петербург, Россия
degtyrev@sut.ru
Плотникова Е. В.
Санкт-Петербургский государственный университет
телекоммуникаций им. проф. М.А. Бонч-Бруевича, Санкт-Петербург, Россия
ne.nya@mail.ru
ОПРЕДЕЛЕНИЕ НЕРЕЧЕВЫХ СИГНАЛОВ
По каналам связи в
телефонной сети передаются различные виды звуковых сигналов. Прежде всего – это
речевой сигнал, составляющий основную долю трафика. Поэтому очень важно уметь
определять наличие в канале речевого сигнала. Однако речевым сигналом дело не
ограничивается. Фрагменты речевого сигнала разделяются паузами и шумом, речь
может смешиваться с музыкой, музыка может передаваться сама по себе. Также
возможна передача управляющих тональных сигналов (DTMF, FAX,
АОН), сеансы передачи данных… Алгоритм работы принимающей системы зависит от
вида принимаемого сигнала. Поэтому требуется уметь определять не только речевой
сигнал, но и другие виды неречевых сигналов.
Подходы к решению
Речевой сигнал
характеризуется определенным набором объективных характеристик: временной структурой
сигнала, длительностью звучания, спектральным составом и т.д. Структура
речевого сигнала определяется не только семантикой передаваемого высказывания.
Речь несет также и информацию и информацию об эмоциональном состоянии диктора,
его индивидуальные параметры, позволяющие отличать дикторов друг от друга.
Спектр речи постоянно
изменяется во времени, но если наблюдать его достаточно долго, то можно получить
довольно устойчивую спектрограмму. Спектром речи называется зависимость
среднего в течение длительного времени спектрального уровня речи от частоты [1]. Эта зависимость показывает распределение
энергии по различным частотам, характерное для данного языка.
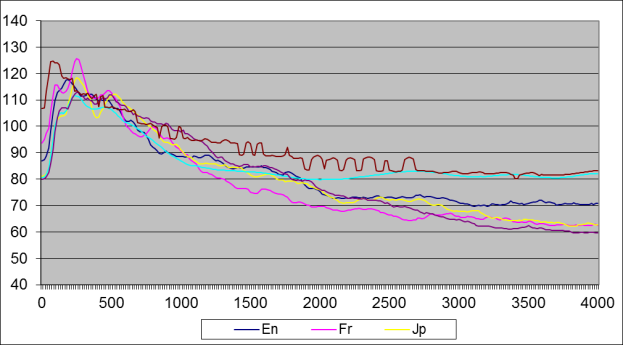
Рисунок 1 – Спектры речи
и музыки
Для примера на рисунке 1
представлены спектры речи для пяти языков: английского (En)
французского (Fr), японского (Jp), русского (Ru)
и итальянского (It). Кроме того, на рисунке 1 приведена
кривая, соответствующая спектру музыкального сигнала.
Видно, что спектры речи
на различных языках различаются. Также, видно, что спектр музыкальных записей
отличается от спектра речевого сигнала. Это позволяет говорить о возможности
вынесения музыкальных сигналов в отдельный класс и определение их по общей
схеме в разработанном программном обеспечении.
Структура системы
Авторами была
разработана система определения языка звучащей речи, в которой принимаемый
сигнал мог быть либо тишиной, либо речевым. Представляется естественным
расширить возможности разработанной системы определением различных видов
сигналов и прежде всего – определением музыки. Параметризация идентифицируемого
сигнала основана на спектральном анализе. Функции цифровой обработки сигналов
были заимствованы из системы оценки качества передачи звука AQuA
[2]. Схема работы системы представлена на рисунке 2.
В разработанной системе
предусмотрено два режима работы: режим определения языка звучащей речи и режим
построения модели языка. В режиме определения языка на вход системы подается
один звуковой файл. В режиме обучения система работает не с одним звуковым файлом,
а с набором записей. Выполняется предварительная проверка качества записей по
соотношению сигнал/шум. Только не содержащие шума записи используются в
обучении. После проверки принятые к обработке записи объединяются в один
звуковой поток и обрабатываются по общей схеме. Все записи, используемые для
обучения должны иметь одинаковый формат.
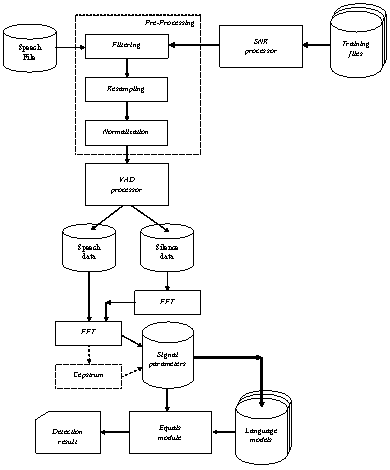
Рисунок 2 – Схема работы
системы
определения языка
звучащей речи
Входящий звук проходит
предобработку, заключающуюся в фильтрации, изменении частоты дискретизации и
нормализации уровня энергии сигнала. Изменение частоты дискретизации
выполняется только в том случае, если частота дискретизации не совпадает с
частотой дискретизации моделей языков.
Далее сигнал
обрабатывается с помощью алгоритма VAD и разделяется на речь и
«тишину». Сначала обрабатывается «тишина». По данным, отнесенным к «тишине»,
строится интегральный спектр, который передается на модуль построения спектра
речевой составляющей сигнала. В процессе построения интегрального спектра
речевых данных выполняется его коррекция на спектр «тишины». Таким образом,
выполняется очистка спектра речевых данных от стационарного шума.
В случае необходимости
по спектру речевых данных строится интегральный кепстр речевого сигнала.
Интегральные спектр и кепстр сигнала составляют его параметрическое описание. В
режиме обучение параметрическое описание сохраняется в базе моделей, а в случае
определения языка передается на модуль сравнения.
Модуль сравнения
подгружает модели языков и параметры идентифицируемого звука, а затем выполняет
сравнение параметров звука с моделями. Имя модели, ближайшей к параметрам звукового сигнала, вместе с коэффициентом
подобия принимается за результат определения языка.
Для определения музыки в
системе создается специальная «модель языка», обученная по музыкальным записям.
Для отделения других неречевых сигналов вводится значение порога подобия с
известными системе моделями звуковых сигналов.
Эксперименты по определению языка звучащей речи и музыки
Для каждого из
перечисленных языков были построены спектры речи. Длительность звукозаписей для
каждого языка составила около часа. Использовались записи с частотой
дискретизации 16 кГц. Для проверки точности идентификации на английском,
французском и японском языках использовались записи базы ITU-T
[3]. Для русского языка была создана тестовая база, включающая 260 записей, с
длительностями менее 20 секунд. (Длительность записей в базе ITU-T 8
секунд.)
Таблица 1 – Точности определения
языка на сигнале 16кГц
|
Язык |
Распознано как |
Ok |
Fail |
||||
|
EN |
FR |
JP |
RU |
It |
|||
|
EN |
183 |
4 |
0 |
0 |
0 |
97,86096 |
2,139037 |
|
FR |
3 |
185 |
0 |
0 |
0 |
98,40426 |
1,595745 |
|
JP |
0 |
0 |
188 |
0 |
0 |
100 |
0 |
|
RU |
6 |
0 |
0 |
254 |
0 |
97,69231 |
2,307692 |
|
IT |
5 |
0 |
0 |
0 |
183 |
97,34043 |
2,659574 |
|
Result |
|
491,298 |
6,042474 |
||||
Из таблицы 1 видно, что система
позволяет получить приемлемые значения точности определения языка звучащей речи
на сигнале с частотой дискретизации 16кГц.
Сложность заключается в
том, что передаваемый по каналам связи сигнал имеет меньшую частоту
дискретизации. Обычно частота дискретизации составляет 8кГц, и соответственно,
различительные возможности спектров сигналов снижаются.
Частоты дискретизации
ниже 8кГц используются крайне редко и их сложно назвать стандартными. Для
повышения универсальности системы было решено построить модели языков звучащей
речи по сигналу с частотой дискретизации 8кГц. Тогда подавляющее большинство
сигналов можно будет привести к рабочей частоте дискретизации и
идентифицировать.
Собранная и обучающая и
тестовая базы были приведены к частоте дискретизации 8кГц. Дополнительно была
создана база музыкальных записей: различные исполнители, различные языки,
различные жанры, общая длительность около 98 часов. Около пятнадцати часов
музыкальных данных было отдано для тестирования. Результаты эксперимента
представлены в таблице 2.
Таблица 2 – Точность
определения языка и музыки на сигнале 8кГц
|
Язык |
Распознано как |
Ok |
Fail |
|||||
|
EN |
FR |
JP |
RU |
It |
Music |
|||
|
EN |
187 |
0 |
0 |
0 |
0 |
0 |
100 |
0 |
|
FR |
3 |
185 |
0 |
0 |
0 |
0 |
98,40426 |
1,595745 |
|
JP |
17 |
0 |
171 |
0 |
0 |
0 |
90,95745 |
9,042553 |
|
RU |
7 |
12 |
1 |
240 |
0 |
0 |
92,30769 |
7,692308 |
|
IT |
9 |
0 |
0 |
4 |
175 |
0 |
93,08511 |
6,914894 |
|
Result Ln |
|
474,7545 |
18,33061 |
|||||
|
Music |
36 |
26 |
11 |
21 |
23 |
177 |
60,20408 |
39,79592 |
|
Result All |
|
534,9586 |
58,12652 |
|||||
Тестирование показало:
·
Понижение
частоты дискретизации сигнала снизило точность определения языка звучащей речи
примерно на 17%. Однако в рамках использования в составе системы оценки
качества передачи речи, полученные характеристики приемлемы для практического
применения;
·
Записи
речи не путаются с музыкальными записями.
·
В
61 % случаев определение музыки происходит правильно. В остальных случаях
музыка сопоставляется с одной из моделью языков. Скорее всего, модель
определяется языком исполняемой композиции и следует строить более детальные
модели музыки для повышения точности определения. Совершенствование модели
музыки – одно из возможных направлений развития исследования.
Заключение
В результате
проведенного исследования было разработано программное обеспечение (ПО)
определения языка звучащей речи и музыки, предназначенное для встраивания в
систему оценки качества передачи речи AQuA. Достигнутые показатели
точности позволяют говорить о возможности использования ПО в качестве
самостоятельного решения.
Реализована возможность
работы ПО по сигналу с частотой дискретизации 8кГц с получением приемлемых
показателей точности определения языка звучащей речи.
Достигнуть
удовлетворительной точности определения музыки по одной модели не удалось.
Дальнейшее развитие системы
связано с построением моделей для других языков и совершенствованием модели
музыки, повышением точности определения и введением в модели дополнительных
параметров.
Использованная литература
1. Покровский Н.Б.
Расчет и измерение разборчивости речи / М., Связьиздат, 1962
2. Valentin Smirnov, Mikhail Gusev Objective method of speech signal
quality estimation // Proceedings of the 11-th International Conference
"Speech and Computer" SPECOM'2006.-St.Petersburg, Anatolya
Publishers, 2006, pp. 242-244
3. ITU-T coded-speech database // Supplement 23 to ITU-T P-series
Recommendations / http://www.itu.int/rec/T-REC-P.Sup23-199802-I/en