Кудинов
Ю.И., Байков С.В., Келина А.Ю., Суслова С.А.
Липецкий государственный технический университет
Об
идентификации одного класса нечётких моделей
Для описания сложных и плохо
определенных технологических процессов и объектов широко используются нечёткие модели, известные
как TS (Takagi – Sugeno) – модели и состоящие из
продукционных правил, в правых частях которых находятся линейные уравнения [1]
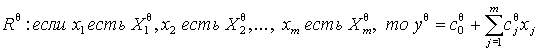 , (1)
, (1)
где ![]() – номер правила; х
= (х1, …, xm) – вектор входных переменных,
которые характеризуются соответствующими нечеткими множествами
– номер правила; х
= (х1, …, xm) – вектор входных переменных,
которые характеризуются соответствующими нечеткими множествами ![]() ,
, ![]() с функциями принадлежности
с функциями принадлежности
![]() , зависящими от входных xj переменных, а также от
векторов параметров
, зависящими от входных xj переменных, а также от
векторов параметров ![]() ,
, ![]() ,
, ![]() .
.
Нечёткие правила (1), оснащённые механизмами вывода, образуют нечёткую
модель. Механизм вывода, применённый к нечётким правилам, даёт возможность при
заданных входных переменных х1, х2,…, хm рассчитать выходную y. Для обеспечения адекватности нечёткой модели
были разработаны алгоритмы параметрической и структурной идентификации,
подробно описанные в работе [2].
Так,
количество m значимых входных переменных определяется целочисленным
генетическим алгоритмом Ym,
количество правил q – алгоритмами Yq разбиения функций принадлежности
или пересчета функций принадлежности, констант и коэффициентов линейных
уравнений с – рекуррентным
методом наименьших квадратов Yc
и параметров – вещественно-значным генетическим алгоритмом Yd. В конечном счете алгоритмы
Yc и Yd обеспечивают выполнение
условия адекватности
![]() (2)
(2)
|
*Работа выполнена при
поддержке РФФИ по проекту 08-08-00052 |
и характеризуются условием
сходимости на g-ой итерации
![]() , (3)
, (3)
где ![]() ,
,![]() - предельно допустимые значения средней модульной ошибки и
скорости ее изменения, соответственно.
- предельно допустимые значения средней модульной ошибки и
скорости ее изменения, соответственно.
Введём
также алгоритм логического выбора Ψy, использующего условия
адекватности (2) и сходимости (3). Если не выполняются условия адекватности, но
выполняются условия сходимости то, осуществляется переход к следующему
алгоритму. При выполнении условия адекватности идентификация завершается. Переход
осуществляется от алгоритма с сильно выраженным к алгоритму со слабо выраженным
локальным характером сходимости. Например, алгоритм Ψc,
как правило, находит только локальный минимум, в то время как алгоритм Ψd
способен определить глобальный минимум. Потому эти алгоритмы располагаются в
следующем порядке: Ψc, Ψd.
Ещё меньшими локальными свойствами сходимости обладают алгоритмы структурной
идентификации, расположенные в порядке Ψq, Ψm:
они без алгоритмов параметрической идентификации Ψc,
Ψd не в состоянии обеспечить сходимость к решению.
Следовательно, для достижения и поддержания требуемой точности нечёткой модели
необходимо использовать алгоритмы параметрической Ψc,
Ψd и структурной Ψq,
Ψm идентификации, а также алгоритм логического выбора
Ψy, которые выполняются в определённой
последовательности П, реализованной с помощью организующего алгоритма
![]()
и
осуществляющей т. н. гибридную идентификацию.
Рассмотрим принципы построения последовательности П или
процедуры гибридной идентификации. Вначале действуют алгоритмы параметрической
идентификации Ψc,
Ψd и
алгоритм логического выбора Ψy согласно
схеме на рис. 1.
Порядок работы алгоритмов Ψс и Ψd
параметрической идентификации можно
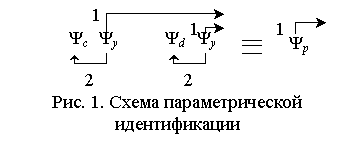 охарактеризовать стрелками 1, 2, исходящими из алгоритма Ψy.
Стрелка 1соответствует выполнению условия аде кватности
охарактеризовать стрелками 1, 2, исходящими из алгоритма Ψy.
Стрелка 1соответствует выполнению условия аде кватности
(условие сходимости может быть любым) и окончанию обучения; стрелка 2 –
нарушению условий адекватности и сходимости и продолжению идентификации алгоритмами Ψс или Ψd. При нарушении условия адекватности
и выполнении условия сходимости осуществляется переход к следующему
находящемуся справа от Ψy
алгоритму. Приведем последовательность алгоритмов Ψc ,
Ψy, Ψd ,
Ψy к виду
Ψр (рис. 1) и назовем ее схемой параметрической
идентификации.
Алгоритмы, определяющие
количество правил Ψq и переменных Ψm
нечеткой модели, осуществляют преобразование пространств правил
![]()
и входных переменных
![]() ,
,
сопровождающееся изменением
количества коэффициентов линейных уравнений и параметров ФП как в первом
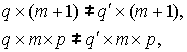
так и во втором случаях
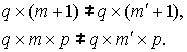
 Следовательно, после
преобразования пространств Rq
и Xm алгоритмами Ψq и Ψm за каждым из них должны
следовать алгоритмы Ψc, Ψd
параметрической идентификации Ψр, уточняющие коэффициенты
линейных уравнений c и параметры ФП d.
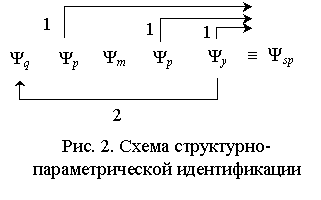
По аналогии получим последовательность алгоритмов Ψq,
Ψp, Ψm, Ψp, Ψy, составляющих схему структурно
– параметрической идентификации Ψsp, изображённую на рис. 2. Гибридная идентификация
(рис. 3) начинается с параметрической Ψp и завершается структурно –
параметрической Ψsp идентификацией. Реализация
последовательности запуска и завершения алгоритмов параметрической Ψр
и структурно – параметрической Ψsp идентификации
возлагается на организующий алгоритм
Ψ.
Следовательно, после
преобразования пространств Rq
и Xm алгоритмами Ψq и Ψm за каждым из них должны
следовать алгоритмы Ψc, Ψd
параметрической идентификации Ψр, уточняющие коэффициенты
линейных уравнений c и параметры ФП d.
По аналогии получим последовательность алгоритмов Ψq,
Ψp, Ψm, Ψp, Ψy, составляющих схему структурно
– параметрической идентификации Ψsp, изображённую на рис. 2. Гибридная идентификация
(рис. 3) начинается с параметрической Ψp и завершается структурно –
параметрической Ψsp идентификацией. Реализация
последовательности запуска и завершения алгоритмов параметрической Ψр
и структурно – параметрической Ψsp идентификации
возлагается на организующий алгоритм
Ψ.
i + 1
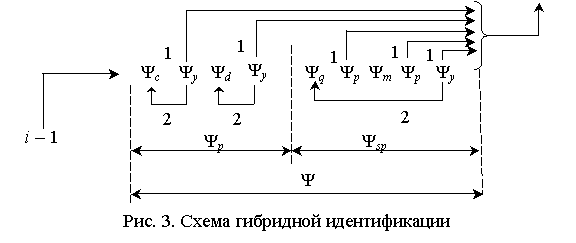
Здесь
идентификация i – ой нечеткой модели
заканчивается переходом к идентификации i + 1 – ой нечеткой модели.
Такой подход был использован при построении системы прогнозирования дефектов
металлопродукции на конвертерном производстве [3].
Литература:
1.
Takagi
Y., Sugeno M. Fuzzy identification of Systems and its application to modeling
and control // IEEE Trans. Systems Man and Cybern, 1985. – V. SMC – 15. – P.
116-132.
2. Кудинов Ю.И., Кудинов И.Ю., Суслова С.А. Нечёткие модели динамических процессов: Монография. – М.: Научная книга, 2007. – 184 с.
3. Кудинов Ю.И., Кудинов И.Ю. Принципы построения нечеткой системы прогнозирования дефектов металлопродукции // Материалы 4-ой Всероссийской конференции «Нечёткие модели и мягкие вычисления». Ульяновск: УлГТУ, 2008. – С. 13-18.