УДК 004.272.43
О. Н.
РОМАНЮК, В. В. ВОЙТКО, С. С. ВОЗНИЙ
Вінницький національний технічний університет
СЕМАНТИЧНИЙ АНАЛІЗАТОР НА ОСНОВІ GPU
У статті розглянуто можливості використання відеокарт для
неграфічних розрахунків, таких як: швидке опрацювання символів у системі ASCII,
мультипроцесорний перебір, паралельне порівняння слів, сортування тексту за
ознаками.
Ключові слова: семантика, символи, текст, переклад,
мультипроцесори.
Постановка задачі
У семантичних обчисленнях значну
роль відіграють мовні корпуси, які в собі несуть інформацію про особливості
тієї чи іншої мови. Використання корпусів дає змогу з певною достовірністю
здійснювати переклад текстів.
Визначення мови тексту є
трудомістким і потребує чимало ресурсів. Саме за таких умов використання
потужності відеокарт дає змогу збільшити продуктивність обрахунків.
Метою статті є обґрунтування можливості
використання відеокарт у семантичних операціях, а саме, у багатопоточному паралельному порівнянні, що в перспективі
дасть змогу створювати ефективні
системи для машинного перекладу.
Аналіз публікацій по темі
досліджень
Методи семантичного аналізу використовують мовні корпуси або спеціалізовані
бази даних. Найпоширенішим методом визначення мови є «метод повного перебору за
словником». У цьому методі відбувається циклічний перебір всіх слів тексту та
пошук їх у мовні базі. За кількістю збігів визначається мова тексту. Цей метод
забезпечує високу достовірність результату, проте його основним недоліком є
потреба у використанні великих об’ємів пам’яті та ресурсів мікропроцесора [1,2].
Метод «символьного аналізу»[1] не потребує великих затрат пам’яті. Він оперує з кодами
символів у системі ASCII. Під час аналізу тексту
аналізується кожен символ, а не слово, тому немає
потреби використовувати мовні корпуси. Недоліками цього методу: тривалий час на
обробку символів, потреба в паралельних обчисленнях [3].
Корпусна
лінгвістика - розділ мовознавства, що займається розробкою, створенням та
використанням текстових корпусів.
Лінгвістичним
корпусом називають сукупність текстів, зібраних відповідно з певними
принципами, розмічених за стандартом і забезпечених спеціалізованою пошуковою
системою.
Використання
корпусу є ключовим у перекладі тексту. Для визначення мови не потрібно використовувати
цілий корпус. Для цього слід використовувати лише словники, а якщо врахувати
символьні особливості певних мов, то вистачить і символьних таблиць ASCII, а
також таблиць спеціальних символів та ієрогліфів. Виявлення характерного коду
символів свідчить про приналежність
певній мовній групі. Цей метод має обмежене використання через велику
кількість помилок у визначені мов, а також через відсутність можливості
визначити діалектичні ознаки мовної приналежності. Цю задачу вирішує метод
повного словникового перебору.
Незалежно
від методу, визначення мови тексту потребує використання багатопроцесорних
комп’ютерів для обрахунків. Процес визначення мови є трудомістким тому на
процесорах з відносно малою кількістю ядр (менше 4) є не достатньо ефективним [2,3].
Необхідності
визначення мов методом перебору потребує використання потужних
багатопроцесорних систем. Вирішити цю задачу
можна за рахунок використання відеокарти персонального комп’ютера.
Реалізація семантичного аналізу тексту на GPU
Відеокарта містить швидку
глобальну пам'ять з доступом до неї всіх мультипроцесорів, локальну пам'ять у
кожному мультипроцесорі, а також спеціальну пам'ять для констант. Ядра
виконують одні й ті ж інструкції одночасно. Такий стиль програмування є
звичайним для графічних алгоритмів і багатьох наукових завдань.
Відеокарта може використовуватись
і у семантичному порівнянні та сортуванні. Використання відеокарт дасть змогу
за малий проміжок часу проводити порівняння значних масивів даних, сортування
за ознаками та паралельне виконання обчислень [2,4,5].
При використанні GPU у
семантичному аналізі символи з тексту можна паралельно порівнювати,
використовуючи ALU. При цьому слід виділити процесори для підрахунку виявлення
відповідностей кодів символів з еталонними символьними корпусами. В цьому
випадку можна буде проводити паралельне порівняння цілих масивів символів і
відслідковувати збіги. При завершені аналізу порівнюються індекси збігів по
корпусах. Найбільший індекс свідчить про
приналежність до певної мови.
При використанні GPU у семантичних багатопоточних розрахунках є
можливість реалізувати декілька режимів роботи аналізатора. Робота аналізатора
буде полягати в опрацюванні багатьма логічними процесорами потоку даних, до
кожного з таких ALU
буде застосовуватись однакова командна інструкція. Аналізатор такого типу можна
побудувати на основі SIMD (Single Instruction, Multiple Data).
Даними в аналізаторі буде
використовуватись лінгвістичний символьний або мовний корпус. До кожного ALU буде застосована процедура порівняння слів з
тексту із повним перебором слів з корпусу. Також слід виділити окремий
процесор, що буде підраховувати індекси співпадань і процесор для визначення
результату обрахунку при порівнянні індексів. Аналізатор буде здійснювати
повний словниковий перебір слів з тексту зі словами мовного корпусу. Структуру
аналізатора зображено на рисунку 1.
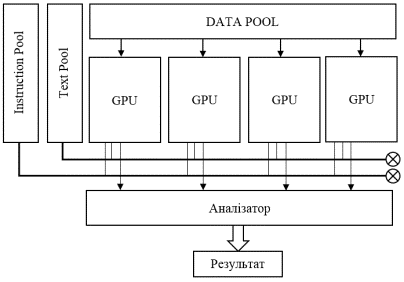
Рисунок 1 – Структура семантичного
аналізатора на основі GPU
Побудований аналізатор буде
визначати мову тексту, проводячи повне семантичне порівняння значно швидше, ніж
аналоги на CPU. Крім того слід очікувати підвищення результатів
достовірності у визначені мови.
Висновки
У роботі запропоновані можливі
реалізації семантичних аналізаторів на основі GPU. Проаналізовані можливості
обробки значних масивів текстових даних за допомогою відеокарти.
Розробка семантичних аналізаторів на основі GPU забезпечить швидке та більш точне визначення мов
текстів.
Література
1. Dovnar PY, Alexander Vorontsov
Linguistic processor. Development / P. Yu Dovnar / / International Journal of
Computer Science with: information systems and technology: Proceedings of the
International Scientific Congress. - 2011. - Vol. 15. - S. 18-96.
2. Straka AM Corpus Linguistics (using
the hull definition text) [E resource] / A. Straka / / Corpus Linguistics.
Access mode: http://ru.wikipedia.org/wiki/ASCII.
3. Mitin OV, AS Evdokimenko Methods of
text analysis: methodological foundations and program implementation [E
resource] / O. Mitin, AS Evdokimenko. - Mode of access:
http://cyberleninka.ru/article/n/metody-analiza-teksta-metodologicheskie-osnovaniya-i-programmnaya-realizatsiya.
- Title screen.
4. History of machine translation [E
resource] / / History of machine translation. Access mode:
http://mrtranslate.ru/guessers.php.
5. Jennings T. An annotated history of
some character codes or ASCII American Standard Code for Information
Infiltration / T. Jennings, / / American Standard Code for
Information Infiltration. - 2004. - № 1. - Pp. 11 ¬ -66.
6. National versions ASCII [E
resource] / / National versions ASCII. Access mode:
http://ru.wikipedia.org/wiki/ASCII.
7. Smirnov Non-graphic computing on
the graphics card (NVIDIA CUDA and AMD Stream) [E resource] / M. Smirnov / /
Non-graphic computing on the graphics card. Mode of access:
http://poisk-videokart.ru/article/articles/negraficheskie-vychisleniya-na-videokarte-nvidia-cuda-i-amd-stream/19.html
8. Berillo A. NVIDIA CUDA -
non-graphic computing on GPU [E resource] / A. Berillo / / NVIDIA CUDA -
non-graphic computing on GPUs. Access mode:
http://www.ixbt.com/video3/cuda-1.shtml
9. CUDA.NET for. NET-developer [E
resource] / / CUDA.NET for. NET-developer. Access mode:
http://habrahabr.ru/sandbox/22562/.