Система мониторинга ситуации
на рынке и поддержки принятия решений в области торговли кредитными
деривативами.
Аннотация. Представлено описание решений, моделей и методов для
создания инструментов доступа к многомерным данным в области торговли
кредитными деривативами и последующего их анализа для людей, не являющихся
техническими специалистами в области баз данных, благодаря интуитивно-понятным
пользовательским интерфейсам и алгоритмам, автоматизирующим низкоуровневые
операции с данными, позволяя абстрагироваться от них.
Ключевые
слова: мониторинг, система поддержки
принятия решений, пользовательский интерфейс, хеджирование, кредитный
дериватив.
Abstract. Solutions, models,
algorithms providing access and analysis of multidimensional data structures in
context of credit derivatives trading, targeting on people without any
technical skills in databases. Due to intuitive measuring user interfaces and
algorithms automating low-level data operations allowing to abstract away from
them.
Keywords.
monitoring, decision support system, user interface, hedging, credit
derivative.
Введение
Кредитные операции – самая доходная статья
банковского бизнеса. Управление рисками при торговле производными кредитными
продуктами позволяет банку защититься от неблагоприятных изменений цен на рынке
акций, процентных ставок, и т.п. Для быстрого и верного принятия
управленческого решения, требуется проанализировать достаточный объем
информации, адаптированной для понимания, то есть правильно обработанной
специализированной системой мониторинга и поддержки принятия решений. [1] Для
некоторых областей, например бюджетирования и планирования имеется довольно
много хорошо проработанных программных решений от таких производителей как SAP,
Oracle, PeopleSoft. [2, 3]. Однако все
еще есть области, в которых автоматизация процесса анализа и принятия управленческих
решений требуют усовершенствований. Одной из таких областей и является
управление рисками при торговле производными кредитными продуктами ‑ кредитными
деривативами.
Кредитные деривативы позволяют
отделить кредитный риск от всех других рисков, присущих конкретному
инструменту, и перенести такой риск от продавца риска (приобретателя кредитной
защиты) к покупателю риска (продавцу кредитной защиты). Основной набор таких
инструментов – это кредитные дефолтные свопы (CDS), опционы, фьючерсы и т. д.
Обычно, целью покупки
дериватива является не получение базового актива, а хеджирование (страхование, снижение риска от потерь)
ценового или валютного риска во времени, или получение спекулятивной прибыли от
изменения цены базового актива. Операции на рынке осуществляются биржевыми
торговцами – трейдерами, функция которых включает анализ текущей ситуации на
рынке и заключение торговых сделок.
В статье приводится описание разрабатываемой
специализированной системы анализа рыночных сделок (САТС), которая позволяет пользователям,
не имеющим достаточной квалификации, выполнять операции с большими объемами многомерных
данных и использовать инструментарий интеллектуального анализа данных. Система
обеспечивает поддержку принятия решений, наглядность, гибкость и высокую производительность
работы специалистам в области биржевого трейдинга, без участия технических
специалистов.
1. Структура
распределенной системы анализа трейдерских сделок
Система представляет собой Интернет (Web)
портал, посредством которого приложения, выполняемые на стороне клиента,
организуют взаимодействие с серверной частью. Функциональная (структурная)
схема системы на высоком уровне представлена на рисунке 1.
Зарегистрированный трейдер работает с
порталом через клиентскую прикладную программу, пользовательский интерфейс
которой включает ряд инструментов (описываемых ниже) для удобной и наглядной работы
с данными.
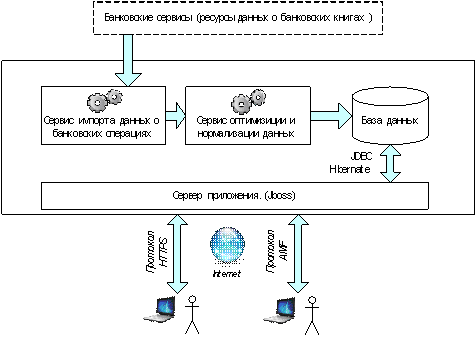
Рисунок 1. Структурная схема
компонентов системы САРС
Серверная часть, получая запросы от
программ-клиентов, производит необходимые операции с данными и передает
требуемую информацию. Серверная логика разработана на платформе Java Enterprise
Edition (язык программирования Java) с использованием технологий Spring и ORM
Hibernate. Hibernate ‑ библиотека для языка программирования Java,
предназначенная для решения задач объектно-реляционного проецирования
(object-relational mapping — ORM). Hibernate решает задачу связи классов Java с
таблицами базы данных, осуществляет автоматическое обновление струкруры таблиц,
построение запросов и обработки полученных данных. [4]
В качестве серверной платформы был выбран
JBoss Application server, ‑ Java Enterprise Edition сервер приложений с
открытым исходным кодом, разработанный одноимённой компанией. Достаточно
хорошая реализация делает его конкурентом для аналогичных проприетарных
программных решений, таких как IBM WebSphere
или Oracle WebLogic.
Клиентское приложение обменивается
информацией с сервером по протоколам HTTPS (шифрованный HTTP) и AMF (Adobe
Media Format). AMF - это специальный протокол, используемый для обмена данными
и вызова удаленных серверных процедур c
клиентского приложения, разработанного на платформа Adobe Flex. [5] Flex
является высокоэффективной средой разработки с открытым кодом для создания
динамичных мобильных, настольных и веб-приложений. Среда Flex позволяет
разрабатывать мобильные и веб-приложения с использованием базы типовых кодов,
что значительно сокращает время разработки приложений.
Данный подход позволяет без лишних затрат
вычислительных ресурсов обрабатывать большие объемы данных, использую
многофункциональный и «дружественный» пользовательский интерфейс.
2. Процесс
обработки информации
Понятие «ситуация на рынке» выражается
совокупностью данных из различных источников информации, таких как курсы валют,
котировки акций на фондовых рынках, открытые позиции других трейдеров и т.д. За
временную единицу мониторинга обычно принимается один банковский день. Сделки
представляют собой покупку/продажу дериватива определенного типа (облигаций,
кредитных дефолтных свопов и т.п). В процессе сделок, в зависимости от типа
продукта, требуется вести мониторинг изменений около 300 свойств, некоторые из
которых, представлены сложными структурами данных. В конце каждого рабочего банковского
дня на корпоративных серверах банков появляются официальные данные обо всех
сделках, произведенных в этот день. Сервис импорта собирает предоставленную
всеми банками-партнерами информацию с их серверов, обрабатывает, сортирует и
передает во внутреннее временное хранилище. Процесс обычно проходит в течение
нескольких часов в ночное время, так как разные банки делают нужную информацию
доступной на своих серверах в разное время. В некоторых банках информация предварительно
проверяется специальными людьми.
Процесс уменьшения избыточности информации
в базе данных называется нормализацией.
Приведение данных в нормализованный вид позволяет: обеспечить быстрый доступ к
данным в таблицах, исключить ненужное повторение данных, которое может являться
причиной ошибок при вводе и нерационального использования памяти сервера. [6] Утром
до начала рабочего дня, запускается сервис оптимизации, который преобразует
собранную предыдущим сервисом денормализованную информацию из временного
хранилища в структурированный нормализованный вид и пополняет внутреннюю базу
данных. Таким образом, к началу рабочего дня, внутренняя база данных системы
содержит проиндексированную информацию обо всех торговых сделках за предыдущий
интервал времени, например за рабочий день, в оптимизированном и готовом к
работе виде.
Рассмотрим основные инструменты разработанной
системы, позволяющие трейдерам принимать решения о сделках, анализируя наиболее
важную информацию, выбранную из огромного массива данных и представленную в
удобном восприятия и анализа виде. Приложение состоит из нескольких модулей: модуль
визуализации отчета о совершенных сделках, модуль создания и редактирования
режимов агрегации, модуль определения подмножества данных.
3. Модуль
визуализации отчета о совершенных сделках
Данный модуль является ключевым для трейдера,
он позволяет пользователю просматривать информацию о нужных сделках в
структурированном и удобном для восприятия виде, в виде гипертаблицы. Гипертаблица представляет собой новый нестандартный элемент
пользовательского интерфейса. Сочетает в себе функциональность таблицы с
древовидной структурой и включает элементы управления для просмотра изменений значений,
отображаемых в ячейках, во времени. Гипертаблица является способом наглядной
визуализации гиперкуба данных, в котором данные сгруппированы по заданным
параметрам и уровням агрегации. Она предоставляет возможность ориентироваться в
многоуровневой и многомерной древовидной структуре данных в реальном времени.
Пример фрагмента таблицы
представлен на рисунке 2.
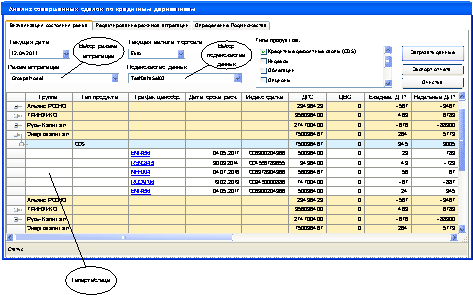
Рисунок 2. Экран
пользовательского интерфейса модуля визуализации отчета о совершенных сделках.
Отличительно особенностью гипертаблицы
является то, что число строк в таблице – величина не статичная, сами строки по
характеру и функциональности не равнозначны, так как некоторые из них являются
группирующими. Группирующие или агрегационные строки являются узловыми и
показывают суммарную информацию по соответствующим колонкам, принадлежащим им
строк нижних уровней агрегации. В свою очередь, группирующие строки так же
могут принадлежать группирующим строкам верхних уровней агрегации. Выпадающие
списки (рис. 2 – список 1 и 2) позволяют выбрать режим агрегации данных и
подмножество выборки соответственно. Элементы в выпадающих списках являются
метками для заранее создаваемых пользователем наборов параметров, редактируемых
при помощи отдельных модулей.
С агрегационными строками связана
специальная кнопка, которая работает аналогично узловому элементу древовидного
списка – позволяет скрыть или показать содержимое выбранной группы. Актуальное
число строк гипертаблицы динамично и варьируется в зависимости от состояния
группирующих строк. Еще одно ключевое свойство гипертаблицы – это возможность
быстрого просмотра и анализа изменения величин во времени. При загрузке данных
в таблицу, с сервера приходит информация о значениях выбранных колонок данных для
всех строк и для каждого торгового дня из выбранного диапазона времени.
Временной диапазон определяется при задании подмножества данных.
Гипертаблица позволяет в
реальном времени посмотреть график изменения любой выбранной величины за нужный
период времени (рис. 3). Передвигая ползунок на временной шкале, можно видеть
изменения значений всех остальных ячеек таблицы, тем самым анализируя
интересующие области согласно графику.
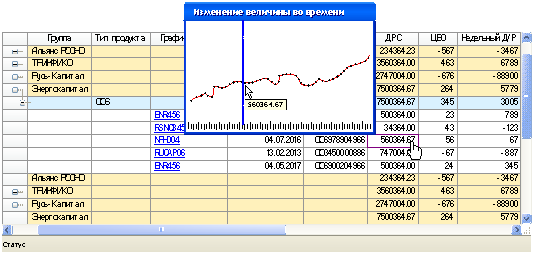
Рисунок 3. Просмотр
изменения выбранной величины во времени.
Кроме гипертаблицы на экран выводится панель
инструментов, при помощи которой задаются параметры загрузки и визуализации
данных. Также пользователю
предоставляется имеется возможность поиска в таблице и другие инструменты
работы с данными. Режим и параметры многоуровневой агрегации (группировки)
данных в соответствии с которым гипертаблица визуализирует информацию, задается
пользователем при помощи специального инструмента на отделном экране приложения.
При выборе режима агрегации задается вид гипертаблицы, определяются видимые
столбцы значений, количество и характер уровней группировки данных, а также
цветовые обозначения.
4. Модуль
создания и редактирования режимов агрегации
Для того чтобы добавить новый режим агрегации,
которым в дальшейшем будет определяться вид и содержание таблицы данных о
биржевых сделках, пользователю необходимо воспользоваться инструментами,
предоставленными этим модулем, определить набор параметров режима агрегации и
сохранить его под определенным названием, чтобы в дальнейшем можно было
воспользоваться им для отображения гипертаблицы (рис 4).
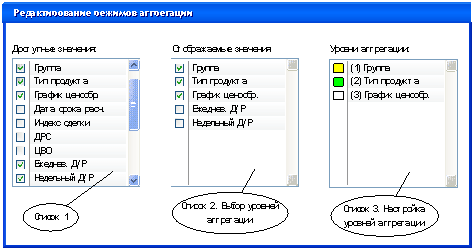
Рисунок 4. Экран
пользовательского интерфейса модуля создания и редактирования режима агрегации.
При конфигурировании режима отображения
данных, пользователю в начале работы следует определить колонки значений,
которые будут показаны в гипертаблице. В первом списке имеются все доступные
для добавления колонки. Этот список определяется характеристиками, хранящимися
в базе данных по каждой торговой сделке из банковских книг, а также значениями,
вычисляемыми на основе этих характеристик. Во втором списке отображаются
выбранные пользователем колонки, значения которых пользователь счел нужными для
просмотра и анализа. Именно эти значения будут отображаться при просмотре
гипертаблицы, и именно по ним будет производиться группирование записей.
Для того чтобы лучше ориентироваться в
большом числе записей, полезной является возможность многоуровневой группировки
значений и возможность дальнейшего отображения древовидной структуры этих
данных с помощью гипертаблицы.
Для задания уровня агрегации необходимо
выбрать колонку значений (отметив ее во втором списке) по которой будут
группироваться строки. Эти строки могут содержать подгруппы, сгруппированные по
другим, нужным пользователю критериям, если будет добавлен следующий уровень
агрегации, который в свою очередь может также содержать подгруппы, если будет
добавлен еще один, низлежащий уровень агрегации и так далее.
Все вложенные уровни в гипертаблице
отображаются в виде дополнительных группирующих строк, содержащих суммарные
значения соответствующих колонок строк нижних уровней агрегации. Для каждого
уровня агрегации имеется возможность задать цветовой индикатор, для еще большей
наглядности и облегчения работы с таблицей. Строки таблицы, соответствующие
определенному уровню будут окрашены в заданные цвета.
Все эти инструменты дают дополнительные
возможности и удобство просмотра и анализа информации. При этом пользователь,
не являясь специалистом в области баз данных и информационных технологий, может
без особого труда выполнять все необходимые действия с большими массивами
данными, оперируя понятиями только той области, специалистом которой он является.
5. Модуль
определения подмножества данных
При всем многообразии доступной для
просмотра информации необходим инструмент, позволяющий пользователю выбирать
именно те данные, которые необходимы для анализа конкретного случая, чтобы не
переводить внимание на нерелевантные в данный момент записи.
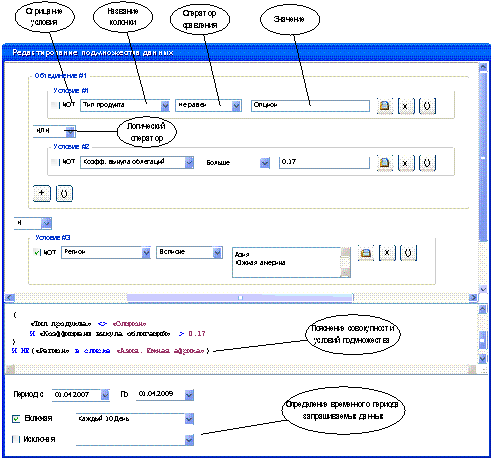
Рисунок 5. Экран
пользовательского интерфейса модуля определения подмножества данных.
Условия, по которым определяется
подмножество данных, интересующи пользователя, могут быть достаточно сложны. В
реляционных базах данных для этих целей используют многоуровневые запросы и
срезы данных (это фильтрующие элементы управления, которые ограничивают данные,
отображаемые в сводных таблицах и сводных диаграммах).
Данный модуль дает возможность
пользователям с экономическим образованием, не являющимся специалистами в
области баз данных и информационных технологий, создавать запросы на выбор
данных оперируя только понятиями предметной области – биржевого трединга.
Модуль представляет из себя конструктор,
позволяющий задавать неограниченное количество гибких запросов выборки данных с
разными условиями и критериями. Форма пользовательского интерфейса модуля (рис.
5) состоит из конструктора условий выборки данных, наглядной интерпретации результата
и выбора временного диапазона.
Конструктор условий выборки данных
содержит компоненты, определяющие условия, по которым во время загрузки данных
будут проверяться все строки заданного временного диапазона на предмет выборки
для анализа или исключения из рассмотрения. Компонент пользовательского
интерфейса, определяющий каждое условие, включает: флаг «NOT» для возможности отрицания условия; поля названия
колонки, значение которой будет проверяться; оператор проверки условия
(доступны все операторы сравнения, плюс некоторые дополнительные, например «В
списке»); поле со значением, с которым будет сравниваться значение колонки при
помощи оператора сравнения.
Значение колонки может быть
непосредственным, введенным в текстовое поле, либо ссылкой на значение другой
колонки. Дополнительно имеются кнопки удаления условия – «х», добавление нового условия – «+», и группировки условий аланогично взятию выражения в скобки –
кнопка «( )». При объединении
условий появляется компонент для установки логического оператора «И», «ИЛИ»,
«НЕ ИЛИ».
Составленное условие выборки вместе с условием
выбора временного диапазона передается с клиента на сервер в виде
сериализованной (кодированной последовательности байт) структуры объектов Action Script 3
по протоколу AMF и затем конвертируется в Java-объекты. На сервере по структуре объектов строится
сложный запрос на HQL – Hibernate Query Language (язык запросов библиотеки
Hibernate). HQL-запрос является более
универсальным в отличие от SQL запроса, не
зависит от используемой базы данных и оперирует объектами а не реляционными
сущностями. Затем с использованием библиотеки Hibernate, и при помощи драйвера базы данных и драйвера SQL-диалекта генерируется многоуровневый запрос к базе
данных на совместимом с ней языке. Такая абстрагированность позволяет скрыть от
пользователя все низкоуровневые операции с данными и работать только гибким и понятным конструктором.
Заключение
Разрабатываемая система позиционируется
как наиболее специализированная для области торговли кредитными деривативами.
Предоставляет инструменты облегчающие доступ к данным и последующий анализ.
Ориентирована на самих трейдеров, давая им возможность работать с системой без
помощи дополнительных технических специалистов, благодаря интуитивно-понятным
«дружественным» пользовательским интерфейсам и алгоритмам, автоматизирующим
низкоуровневые операции с данными, позволяя абстрагироваться от них.
В системе были разработаны и кратко
описаны в статье: модуль визуализации отчета о совершенных сделках, модуль
создания и редактирования режимов агрегации, модуль определения подмножества
данных. Далее планируется разработка модуля конструирования сценариев поведения
рынка и серверного приложения симуляции поведения рынка по заданным сценариям.
Эти инструменты позволят трейдерам проводить эксперименты, проверять
собственные идеи и гипотезы без каких-либо материальных затрат. Система
представляет собой Веб-портал и может использоваться как частными
трейдерами-одиночками, так и профессиональными аналитиками, работающими в
интересах крупных коммерческих банков.
Список
литературы
1. Шишкин,
А.И. Сущность, задачи и принципы мониторинга / А.И.Шишкин // Материалы рабочего
совещания 9 февраля 2003 г. «Экономический рост в регионах России». –
http://www.aspe.spb.ru/Workshop/Shishkin.pdf
2. Turban et al. (2008). Information Technology
for Management, Transforming Organizations in the Digital Economy.
Massachusetts: John Wiley & Sons, Inc., pp. 300–343. ISBN 978-0-471-78712-9
3. Лаврушин
О.И. Банковское дело: современная система кредитования: учебное пособие / О.И.Лаврушин,
О.Н.Афанасьева, С.Л.Корниенко; под ред. засл. деят. науки РФ, д-ра экон. наук, проф.
О.И.Лаврушина. – 3-е изд., доп. – М.: КНОРУС, 2007. – 264 с.
4. Christian Bauer, Gavin King Hibernate in
Action. Manning Publications Co. 2004
ISBN: 193239415X
5. Al Hilwa, Randy Perry Adobe Flex in the
Enterprise: The Case for More Usable Software Copyright 2010 IDC http://www.adobe.com/enterprise/pdf/idc.pdf
6. Когаловский
М.Р. Энциклопедия технологий баз данных.
М.: Финансы и статистика, 2002.
800 с. ISBN 5-279-02276-4
|
Финогеев
Алексей Германович доктор технических наук, профессор, кафедра систем автоматизированного проектирования, Пензенский государственный университет |
Finogeev Aleksey Germanovich Doctor of engineering sciences,
professor, sub-department of CAD systems, Penza State University |
|
|
|
|
Овечкин
Роман Михайлович аспирант, кафедра систем автоматизированного проектирования, Пензенский государственный университет |
Ovechkin Roman Mikhailovich Post-graduate student, sub-department
of CAD systems, Penza State University |
|
|
|
|
Богатырев
Василий Евгеньевич аспирант, кафедра систем автоматизированного проектирования, Пензенский государственный университет |
Bogatyrev Vasily Evgenyevich Post-graduate student, sub-department
of CAD systems, Penza State University |