УДК 007.001.362
Е.А. САВВИНА
ДИАГНОСТИКА
ИНВАРИАНТНЫХ СОСТОЯНИЙ СИСТЕМ МЕТОДОМ КЛАСТЕРНОГО АНАЛИЗА В МУКОМОЛЬНОМ
ПРОИЗВОДСТВЕ
ФГОУ ВПО «Воронежский Государственный Университет
Инженерных Технологий»
Предложена
классификация качества муки методом двухэтапного кластерного анализа. Показано,
что выявление специфических признаков влияет на точность классификации.
Ключевые
слова: коэффициент корреляции, двухэтапный кластерный анализ, специфический
признак.
Качество белого хлеба из пшеничной муки
зависит от качества рецептурных компонентов и точности соблюдения норм
технологического процесса. Поэтому задача определения взаимосвязи между
показателями качества муки и качеством хлеба весьма актуальна.
Цель работы: выявить специфические
признаки, присущие определенному классу качества, провести классификация
методом двухэтапного кластерного анализа и выявить ошибки.
Наиболее распространенные методы
кластеризации: иерархическая и k-средними.
Недостатком иерархических методов кластеризации является то, что модель
предлагает несколько вариантов разбиения или объединения данных в кластеры,
выбор результирующей модели остается за человеком. Кластеризация k-средними, или «метод ближайшего соседа» основан на
том, что число кластеров задается изначально. Недостатками данного метода
являются необходимость применения процедуры несколько раз для различного числа
кластеров, не всегда разбиение оптимально для заданной задачи.
Модель двухэтапного подхода кластеризации
решает некоторые из приведенных выше проблем, позволяет кластеризовать
различные группы по отдельности, а после этого объединять полученные результаты
в конечную структуру кластеров [3].
На первом этапе двухэтапного кластерного
анализа рассчитывается межкластерная дисперсия, логарифмическая функция
правдоподобия и первоначальное количество кластеров через критерии Акаике и
Байеса. Дисперсия ξi в
кластерах v=(i,s) рассчитывается:
![]() (1)
(1)
и состоит из двух частей:
![]() - мера дисперсии непрерывных переменных хi в пределах кластера и
- мера дисперсии непрерывных переменных хi в пределах кластера и ![]() мера дисперсии категориальных переменных.
Кластеры с минимальным расстоянием d(i, s) будут
объединены на каждом шаге итерации. Логарифмическая функция правдоподобия для
шага с k-кластерами вычисляется по формуле [2]:
мера дисперсии категориальных переменных.
Кластеры с минимальным расстоянием d(i, s) будут
объединены на каждом шаге итерации. Логарифмическая функция правдоподобия для
шага с k-кластерами вычисляется по формуле [2]:
![]() (2)
(2)
Число кластеров в двухэтапном кластером
анализе может быть задано автоматически. Информационный критерий Акаике (AIC):
![]() , (3)
, (3)
где ![]() - число параметров
или информационный критерий Байеса:
- число параметров
или информационный критерий Байеса:
![]() . (4)
. (4)
На втором этапе кластерного анализа
рассчитывается расстояние для k- кластеров:
![]() , (5)
, (5)
где dk−1
– расстояние в котором кластер k слит с
кластером (k−1). Минимальное расстояние между кластерами рассчитывается:
![]() (6)
(6)
В ходе выполнения
работы была сформирована база данных, состоящая из 150 анализов,
характеризующих качество муки и готового белого хлеба по 22 признакам. Каждый
анализ описывался химическими (массовая доля белка, массовая доля золы,
массовая доля жира, содержание клетчатки и водорастворимых углеводов) и
органолептическими показателями качества муки (влажность, титруемая и активная
кислотность, массовая доля и качество клейковины, вкус, запах, хруст и т.д.); а
также показателями качествами хлеба (влажность, кислотность, пористость). В
соответствии с классификацией, предложенной Пономаревой Е.И. [1] данные были
разделены на 4 группы. Первая группа (класс 1 высшего качества) – 35 наблюдений
(23,3%); вторая (класс 2 хорошего качества) – 50 (33,3%); третья (класс 3
плохого качества) – 35 (23,3%); четвертая (класс 4 очень плохого качества) – 30
(20,0%).
По критерию Колмогорова-Смирнова
установлено, что для подавляющего большинства признаков распределение
отличается от нормального, на уровне значимости P=0,05. Нормальному закону распределения подчиняются
признаки: газообразующая способность и содержание водорастворимых углеводов.
Качество хлеба оценивается качественными и
количественными признаками. Для улучшения классификации необходимо
формализовать качественные признаки. Одним из методов формализации признаков
является переход из качественных характеристик в бинарные признаки.
В базе данных присутствуют категориальные
признаки (вкус, запах, хруст, зараженность вредителями), значения которых были
кодированы цифрами. Исходные категориальные признаки были преобразованы в
бинарные, где каждый признак имел 2 состояния (0 – признак отсутствует, 1 –
присутствует). В результате в базе данных количество признаков увеличилось с 22
до 26.
Для принятия решений об отнесении хлеба к
определенному классу необходимо отобрать специфические признаки. Для выявления
специфических признаков использовался
коэффициент корреляции Пирсона, затем, по отобранным признакам проводилась
классификация методом двухэтапного кластерного анализа.
Для класса 1 был выявлен 1 информативный
признак (содержание водорастворимых углеводов), для которого коэффициент
корреляции равен 0,823. Для 6 признаков r находится в диапазоне 0,512 до 0,604 по модулю, и
имеет среднюю тесноту связи с классом качества. Во второй группе специфических
признаков обнаружено, значение r не
превышает 0,492, лишь для 2 признаков коэффициент корреляции больше 0,5. В
группе 3 специфических признаков также не обнаружено, теснота связи не
превышает 0,5. Класс 4 имеет корреляцию с 7 признаками, теснота связи сильная.
Для 9 признаков в данной группе коэффициент корреляции r находится в диапазоне от 0,546 до 0,698, теснота
связи средняя (больше 0,5).
Была получена двухкластерная структура
данных. К одному классу (класс II) относится
хлеб очень плохого качества, к другому (класс I) остальные наблюдения. Было допущено 10 (6,7 %)
ошибок, класс плохого качества был ошибочно отнесен к классу очень плохого
качества. Ошибки попадания наблюдений плохого качества в очень плохое, не
являются существенными для классификации, так как классы (3 и 4) не должны
использоваться в хлебопечении. Следовательно, в классификации задан порог
чувствительности выше необходимого.
Однако разделить класс I на подклассы 1, 2 и 3 не удалось. Объединение
наблюдений из данных классов (1, 2 и 3) в один кластер происходит из-за
отсутствия специфических признаков в данных группах. Добавление в систему
классификации признаков, коэффициент корреляции которых меньше 0,7 приводит к
размытию классификации и объединению классов в один.
Результаты двухэтапного кластерного
анализа представлены в таблице 1.
Таблица 1
Результат двухэтапного
кластерного анализа
|
Классы качества |
Распределение по кластерам |
% |
% ошибок |
|
N |
|||
|
Класс I (хлеб
разного качества) |
110 |
73,3% |
0% |
|
Класс II (хлеб очень плохого качества) |
40 |
26,7% |
6,7% |
|
ИТОГО |
150 |
100,0% |
6,7% |
По результатам корреляционного анализа
построили иерархическую схему классификации (рис. 1).
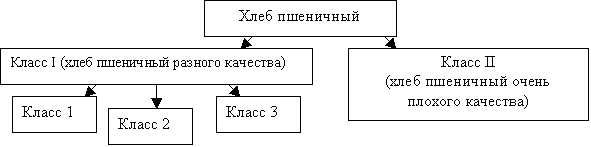
Рис. 1. Иерархическая схема
классификации
ВЫВОДЫ:
1.
Предложен двухэтапный
анализ для отбора наиболее информативных признаков, где на первом этапе
проводится корреляционный анализ, на втором этапе – двухэтапный кластерный
анализ. Показано, что значение коэффициента корреляции влияет на точность
классификации.
2.
Построена иерархическая
схема классификации, где на первом этапе выделяются группы I (хлеб разного качества) и II (хлеб очень плохого качества) с точностью 93,3%; на
втором этапе – класс 1 (хлеб плохого качества) и класс 2 (хлеб хорошего
качества), точность 96,0%; на третьем – класс хорошего качества разбивается на
классы очень хорошего и хорошего качества с точностью 100%.
Список используемых источников
1.
Бююль А., Цёфель П. SPSS: искусство обработки информации, анализ
статистических данных и восстановление
скрытых закономерностей.- СПб.: ООО «ДиаСофтЮП», 2002.-608с.
2.
Бессокирная Г.П. –
Дискриминантный анализ для отбора информативных переменных.- М.: Статистические методы и анализ данных, 2003. №16.-25с.
3.
Johann Bacher, Knut Wenzig. SPSS TwoStep Cluster – A First Evaluation.
–Universitet Erlanger-Nurnberg. - (2004).