Гданский Н.И., Рысин М.Л., Леванов Д.Н., Альтиментова Д.Ю.
Российский государственный социальный университет,
кафедра моделирования информационных систем и сетей
РАЗРАБОТКА НОВЫХ АДАПТИВНЫХ МОДЕЛЕЙ
ДИАЛОГА В КОМПЬЮТЕРНЫХ ОБУЧАЮЩИХ СИСТЕМАХ
Широкое распространение информационных технологий в корне изменило традиционное представление преподавания только как обучение учеников учителем. Компьютерные технологии за счет высокой емкости носителей информации и высоких скоростей их обработки позволяют, во-первых намного расширить рамки материалов, используемых в учебном процессе. Во-вторых, за счет использования развитых способов анализа диалога с пользователем компьютерные технологии могут в значительной степени адаптировать передачу знаний к конкретному учащемуся, приблизив сам процесс по качеству к индивидуальному обучению.
1. Существующие подходы к адаптационному обучению
Одним из преимуществ обучения является возможность реализации многовариантного адаптивного процесса построения учебного процесса, при котором учитывается общий уровень обучаемого, скорость усвоения им учебного материала, его возможности по практическому применению усваиваемого материала для решения задач и т.д.
Общепризнанным является тот факт, что потребность в адаптации возникает в тех случаях, когда привычные способы поведения системы становятся невозможными или утрачивают свою актуальность в связи с низкой эффективностью.
Адаптивность предполагает совместные
усилия педагогов и учащихся. Основные ее наиболее распространенные принципы
заключаются в том, что:
- преподаватель использует приёмы гибкого построения
процесса индивидуализированного режима и темпа учебной работы,
- учащиеся
сами могут планировать ход обучения,
- преподаватель создаёт специальные учебные материалы
для самостоятельной работы,
- используется гибкое сочетание индивидуальных и
групповых форм учебной деятельности.
В РФ закон «Об образовании»,
провозглашающий построение адаптивной системы образования, был принят в 1992 г.
Опытный педагог реализует достаточно
сложные модели адаптивности в преподавании, прежде всего, на основе своих
знаний и многолетнего опыта, причем значительную часть своих действий он
выполняет автоматически, не формулируя их для себя в некотором явном виде.
Принципиальным отличием введения
адаптивности в автоматизированных системах обучения является то, что основные
принципы и правила для них должны быть четко сформулированы в виде алгоритмов и
реализованы в программной обеспечении. Очевидно, что формы и степень
адаптивности в автоматизированных системах практически реализуются только в тех
пределах, которые реально внесены в информационное и программное обеспечения
данных систем.
Основными элементами адаптивного
компьютерного обучения являются адаптивное обучение и адаптивный тестовый
контроль. Их совместное применение позволяет практически реализовать
индивидуализацию обучения - одно из самых важных условий для подготовки
квалифицированных специалистов.
В настоящее время выполняется много разработок в области адаптивного обучения, основанных на различных интерпретациях самого процесса и его отдельных составляющих, а также использовании различных математических и программных средств. В статье [5] предложен подход, позволяющий автоматически подбирать учебные материалы в соответствии с текущей целью обучения и индивидуальными особенностями и предпочтениями учащихся. Статья [4] содержит описание алгоритма адаптации к учебной ситуации, основанного на закономерностях итеративного обучения с использованием языка UML. В работе [2] рассматривают периодические стратегии управления качеством профессиональной подготовки обучаемых с учетом интенсивности забывания, основанные на оптимальном планировании повторений для восстановления знаний. В работе [1] подчеркивается возрастающая необходимость разработки интеллектуальных информационных систем образовательного назначения с возможностью адаптации контента к характеристикам пользователя. В работе [3] предлагается для повышения мотивации учащихся использовать элементы компьютерных игр.
В целом обзор научных публикаций по адаптивному обучению показывает, что основными направлениями в области адаптации компьютерных систем к пользователям являются:
1) проблема обеспечения компьютерных систем механизмами поиска нужной пользователю информации в целях экономии человеческих, временных и материальных ресурсов;
2) проблема понимания компьютерными системами естественного языка, мимики, жестов;
3) проблема представления информации в компьютерных системах, доступной для удобного восприятия пользователем (вопросы моделирования данных об окружающем мире, эргономических свойств интерфейсов);
4) проблема извлечения новых знаний о мире;
5) проблема оценки эффективности взаимодействия пользователя и компьютерной системы;
6) проблема выбора оптимальных траекторий взаимодействия.
Проведенный анализ диссертационных исследований за период 2010 – 2012 гг. показал, что проблема адаптации компьютерных систем к пользователям нашла тесное соприкосновение с одноименной проблемой в области дистанционного обучения и стала предметом исследований представителей широкого круга профессий.
На основании обзора защищенных работ можно сделать заключение, что к числу основных решаемых исследователями задач относятся:
1) задача создания универсальных средств разработки электронных учебных курсов;
2) задача разработки адаптивных систем управления обучением;
3) задача разработки новых моделей контента в электронных учебных курсах;
4) задача разработки моделей, методов и алгоритмов проверки качества обучения.
Традиционный тест является методом педагогического измерения
знаний. В общем случае он содержит: 1) формулировки заданий, 2) указания по их
применению, 3) оценки либо правила оценивания заданий, 4) рекомендации по
интерпретации получаемых итоговых оценок. Основным общепринятым критерием его качества
является минимум числа заданий,
необходимых для выявления уровня подготовленности учащегося. Данный показатель
отражает основную цель традиционного тестирования, выполняемого преподавателем
- за короткое время, быстро,
качественно и с наименьшими затратами сравнить знания как можно большего числа
учащихся. При отсутствии компьютерной техники и развитых информационных
технологий данная формулировка является бесспорной. Однако современные
тенденции развития аппаратного и программного обеспечения позволяют расширить
круг задач, решаемых при тестировании. В связи с этим также нуждается в
уточнении и дополнении традиционный критерий
качества тестирования.
С
системной точки зрения традиционный тест представляет собой единство трех
основных систем:
1) системы
содержательного наполнения знаний, задаваемой при помощи языка проверяемой
учебного материала;
2) формальной системы заданий, расположенных по
возрастающей трудности;
3) системы статистических характеристик отдельных заданий
и построения результатов всего теста.
Необходимость адаптации процесса
контроля знаний вытекает из очевидных недостатков обычного тестирования,
которые заключаются в следующем. Учащемуся с высоким уровнем знаний нет смысла
давать легкие тестовые задания, поскольку он правильно решит их с высокой
вероятностью. Аналогично, учащемуся со слабой подготовкой нет смысла давать
сложные задания.
Поэтому логично для проверки использовать
такие задания, которые соответствуют уровню подготовленности учащегося. Это
существенно повышает точность измерений и сокращает необходимое число оценочных
тестов, а, следовательно, и время индивидуального тестирования.
Адаптивное тестирование заключается
в том, что при успешном ответе ЭВМ подбирает следующее задание более трудным,
при неуспешном ответе – более легким.
Такой алгоритм тестирования требует
предварительной апробации всех тестовых заданий, определения их меры трудности,
а также создания банка заданий и соответствующей программы.
Обычно выделяют три варианта
адаптивного тестирования.
Первый вариант называют
пирамидальным тестированием. В нем при отсутствии предварительных оценок всем учащимся
дается задание средней трудности и уже затем, в зависимости от их ответа,
каждому испытуемому дается задание легче или труднее.
Второй вариант заключается в том,
что начало контроля производится с любого подходящего уровня трудности с
постепенным приближением к реальному уровню знаний.
Третий вариант заключается в том,
что тестирование производится с использованием банка заданий, который
предварительно разделен по уровням трудности. При правильном ответе следующее
задание берется из верхнего уровня, при неправильном ответе - из нижнего.
Таким образом, традиционный адаптивный тест представляет собой
вариант автоматизированной системы тестирования, в которой заранее известны
параметры трудности и дифференцирующая способность каждого задания. Система представляет
собой компьютерный банк заданий, которые упорядочены в соответствии с
интересующими характеристиками заданий. Главной характеристикой заданий
адаптивного теста является уровень их трудности. В общем случае он может быть определен
опытным путем в результате эмпирической проверки на достаточно большом числе
типичных учащихся. Данный подход является общепринятым в теории вероятности и
статистике.
Определение уровня трудности
является одним из главных недостатков в адаптивном тестировании. Его сложная
процедура существенно затрудняет внесение изменений в набор тестовых заданий.
Само понятие сложности теста
является довольно субъективным и может значительно варьироваться даже для
учащихся, проходящих обучение в одной группе. Это обусловлено влиянием
личностных качеств учащегося на результат тестирования. В итоге для одного
студента более простыми могут оказаться задания одного типа, для другого –
задания. Для выработки более результативного подхода к определению сложности
теста необходимо дать конструктивное определение сложности тестового задания.
К основным моделям тестовых вопросов относятся:
· Выбор одного варианта ответа из множества;
· Выбор множества вариантов ответа из множества;
· Соотнесение множества смысловых сущностей множеству других;
· Упорядочение смысловых сущностей;
· Указание ответа знаковым вводом.
Функциональность существующих моделей тестовых вопросов заключается в определении того, правильный или ошибочный ответ дал пользователь. Далее, на основании суммы правильных ответов, выводится заключение пройдено тестирование или нет. При этом результаты передаются и фиксируются в LMS. Учет любых других данных, характеризующих уровень знаний, умений и навыков обучаемого не предусмотрен. Кроме того, все перечисленные модели вопросов, кроме вопроса на указание ответа знаковым вводом, позволяют предугадать правильный ответ, что порождает проблему объективности оценки знаний в электронном тестировании. Таким образом, существующие модели тестовых вопросов способны лишь косвенно отражать уровень подготовки обучаемого.
Основными задачами по улучшению методик электронного тестирования на сегодняшний день являются учет объективности оценки знаний и учет индивидуальных особенностей обучаемого. Очевидно, что обе проблемы взаимосвязаны. В связи с этим, главным направлением в научных исследованиях должна стать разработка новых моделей взаимодействия с обучаемым, имитирующих функции преподавателя, поскольку только преподаватель – человек, обладающий разнообразным социальным опытом, на протяжении всей своей жизни и научно-педагогической деятельности сталкивавшийся с новыми обстоятельствами, вырабатывая при этом новые шаблоны поведения, наиболее соответствующие той или иной ситуации, способен дать объективную оценку знаниям обучаемого.
2. Новые модели тестовых
вопросов
Рассмотрим новую модель тестового вопроса, в которой предусмотрено вычисление результата не только на основании истинности ответа, но и с учетом таких показателей как внимательность и время ответа на вопрос. Формальное описание модели таково:
1 Вопрос и варианты
ответа озвучены диктором. Для прослушивания на слайде имеется специальная
кнопка. После завершения озвучивания вопроса и вариантов ответа начинается
отчет времени обдумывания вопроса пользователем. Отчет времени завершается
после нажатия кнопки «Ответить».
2. Изначально на слайде с вопросом также
расположены кнопки с порядковыми номерами или буквами, к которым привязаны
озвученные варианты ответа, а также, кнопка «Ответить».
3. Есть возможность повторного прослушивания
вопроса без вариантов ответа.
4. Уточнить варианты ответа возможно, наведя
курсор на кнопки с номерами вариантов ответа и прочитав всплывающие подсказки.
Таким образом, предлагается оценивать
результат ответа на вопрос R по значениям трех
показателей: V– истинность ответа, A –
внимательность, T – время ответа. В свою
очередь, V – логическая величина (true/false), A –
число обращений за помощью (подсчет событий повторения вопроса и открытия
всплывающих подсказок), T – время ответа в
секундах, N– число вариантов
ответа.
Внимательность оценивается на основании
попадания значения в изначально определенные интервалы, например,
если A ≤ 1, то
внимательность «высокая»,
если 1
<A ≤ N+2, то внимательность «средняя»,
если A>N+2, то внимательность
«низкая».
По аналогичному принципу ведется оценка
времени, затраченного пользователем на ответ, например:
если T ≤ 10, то
время ответа «допустимое»,
если 10
<T ≤ 30, то время ответа «предельное»,
если T> 30, то
время ответа «неприемлемое» (пользователь мог успеть обратиться за
дополнительной помощью к посторонним источникам информации).
Теперь зависимость результата R
характеризуется следующим списком правил:
R = «ответ верный», если V = true и A =
«высокая» и T = «допустимое»;
R = «ответ верный», если V = true и A =
«средняя» и T = «допустимое»;
R = «ответ верный», если V = true и A =
«средняя» и T = «предельное»;
R = «ответ верный», если V = true и A =
«низкая» и T = «допустимое»;
R = «ответ верный», если V = true и A =
«низкая» и T = «предельное»;
R= «ответ неверный», если V = true и A =
«высокая» и T = «предельное»;
R = «ответ неверный», если V = true и A =
«высокая» и T = «неприемлемое»;
R = «ответ неверный», если V = true и A =
«средняя» и T = «неприемлемое»;
R = «ответ неверный», если V = true и A =
«низкая» и T = «неприемлемое»;
R = «ответ неверный», если V = false и A =
«высокая» и T = «допустимое»;
R = «ответ неверный», если V = false и A =
«высокая» и T = «предельное»;
R = «ответ неверный», если V = false и A =
«высокая» и T = «неприемлемое»;
R = «ответ неверный», если V = false и A =
«средняя» и T = «допустимое»;
R = «ответ неверный», если V = false и A =
«средняя» и T = «предельное»;
R = «ответ неверный», если V = false и A =
«средняя» и T = «неприемлемое»;
R = «ответ неверный», если V = false и A =
«низкая» и T = «допустимое»;
R = «ответ неверный», если V = false и A =
«низкая» и T = «предельное»;
R = «ответ неверный», если V = false и A =
«низкая» и T = «неприемлемое»;
Нетрудно заметить, что внимательность в
большинстве случаев не влияет на результат, но учет данного свойства может
способствовать принятию правильных решений как тьютором, так и адаптивным
электронным курсом на последующих этапах взаимодействия с конкретным
пользователем.
Приведем пример тестового вопроса,
построенного на основании вышеописанной модели. Текст озвучивания: «На какой
сигнал светофора разрешено движение? Красный – нажмите на кнопку 1, желтый –
нажмите на кнопку 2, зеленый – нажмите на кнопку 3». Графически модель
представлена на рис. 1.
Приведенная в примере модель тестового вопроса учитывает некоторые факторы своего окружения, а именно внимательность и скорость мышления тестируемого пользователя, в связи с чем, модель является адаптивной.
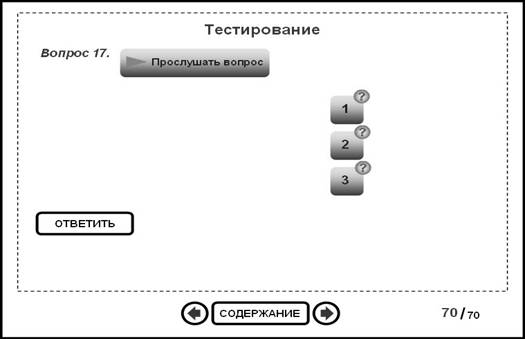
Рис. 1. Пример тестового вопроса с вычислением результата ответа с учетом истинности ответа, внимательности пользователя и затраченного времени на ответ
Еще
одной важной составляющей на пути преодоления проблемы объективности оценки
знаний, умений и навыков стоит задача разработки моделей классификации обучаемых
после прохождения тестовых мероприятий или выставления оценки/итогового балла. Возможности
современной вычислительной техники, развитие новых информационных технологий и
анализ традиционных методик в подходе к оцениванию знаний учащихся в
совокупности подводят к этапу рассмотрения идеи применения иных
способов/подходов, хотя и не совершенных и, как следствие, созданию новых
систем, балансирующих между сложностью разработки и эффективностью.
Проведем анализ двух моделей-классификаторов. Первая модель представляет собой гибридную структуру, объединяющую в себе две технологии, а именно, алгоритм нечеткого логического вывода, реализованный посредством многослойной сети прямого распространения информации (персептрона). Вторая модель является нейронной сетью автоматической кластеризации – самоорганизующейся картой Кохонена. В первом случае знания о предметной области (тестовом задании) организованы в виде базы нечетких правил и функций принадлежности, а в случае с сетью Кохонена знания о предметной области задаются размерностью соревновательного слоя, коэффициентами весов связей и функциями активации нейронов.
В качестве примера был принят один из психологических тестов - тест Холланда на определение профессиональной направленности личности. Предложены модели, способные стать альтернативами алгоритму, лежащему в основе данного психологического теста. Проведен анализ оценки точности вычислений и выявлены преимущества рассмотренных моделей при проектировании электронных тестирующих систем.
Методика
проведения тестирования заключается в следующем. Пользователю предлагается из
каждой пары профессий выбрать в заданной таблице одну, предпочитаемую. Всего
необходимо сделать 42 выбора (ответа на вопрос).
Каждому
типу личности соответствуют определенные виды профессий. Сделать однозначный
вывод о принадлежности к одному определенному типу личности можно только в том
случае, если оценка по этому типу на несколько баллов выше, чем оценки по
другим типам.
Наиболее точный вывод о профессиональной
направленности личности можно сделать, определив три типа, имеющие наибольшие
оценки. В соответствии с теорией Дж. Холланда шесть типов личности
сгруппированы друг с другом по степени сходства в форме шестиугольника (рис. 2).
Каждый тип наиболее схож со своими соседями и отличается от противоположного в
шестиугольнике типа личности.
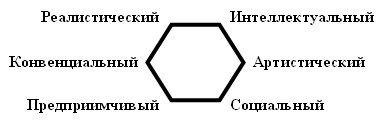
Рис. 2. Модель Джона Холланда
В случае если три типа, получившие наибольшие оценки, являются смежными, то профессиональный выбор наиболее обоснован и последователен. Для диагностики каждого из 6 типов испытуемый должен сделать выбор одной из предложенной пары профессий в каждом вопросе. Максимальное число баллов в тесте – 42, а максимальное число баллов для каждого из шести типов – 14. Например, если по результатам теста для Реалистического типа испытуемый набрал 14 баллов, то на оставшиеся пять типов будет предусмотрено только 42–14=28 баллов.
Математическая модель теста Холланда выглядит следующим образом:
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() ,
,
![]() .
.
![]() ,
,
![]() ,
, ![]() ,
,
![]() ,
, ![]() ,
,
![]() ,
, ![]() ,
,
Для
элементов векторов ![]() и
и ![]() , если
, если ![]() , то
, то ![]() .
.
Нейро-нечеткая модель. Первой была построена нечеткая продукционная нейросеть, реализующая нечеткий вывод Такаги-Сугено. Сеть состоит из четырех слоев (рис. 3):
Слой 1. Нейроны данного слоя представляют собой функции принадлежности лингвистических значений входных лингвистических переменных и выполняют фаззификацию четких значений входных признаков.
Слой 2. Нейроны второго слоя выполняют агрегирование степеней истинности предпосылок каждого правила.
Слой 3. Элементы данного слоя вычисляют нормализованные значения.
Слои 4. Элементы результирующего слоя позволяют формировать на выходе сети дефаззифицированные значения выходной величины.
В рассматриваемой модели выходной слой содержит 1 нейрон.
Тест Холланда состоит из 42 вопросов по 2 варианта ответа на каждый (признак «1» соответствует столбцу «а» в табл. 1, признак «0» - столбцу «б»). Таким образом, число сценариев прохождения теста испытуемым составляет 242=4 398 046 511 104. Чтобы построить обучающую последовательность, необходимо сделать репрезентативную выборку из множества входных массивов Xi, i=42. Также, каждому входному вектору следует отнести ожидаемый отклик сети T, представляющий собой целочисленную константу от 1 до 6: 1 – Реалистичный; 2 – Интеллектуальный; 3 – Социальный; 4 – Конвенциальный; 5 – Предприимчивый; 6 – Артистический.
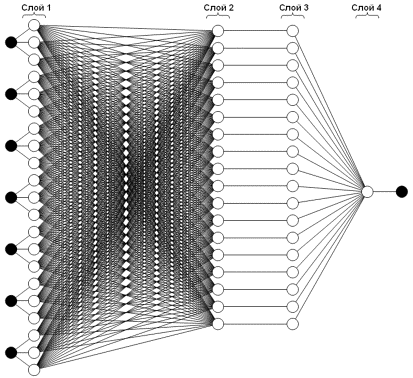
Рис. 3. Структура нечеткой продукционной нейросети
Задача подготовки обучающей последовательности упрощена путем сокращения размерности входных векторов. Их размерность принята Xi, i=7, но, при условии что их элементы примут не бинарные значения, а суммы ответов на каждые 6 вопросов теста Холланда. Тогда для фаззификации получим 7 входных лингвистических переменных: x1 (балл за первые 6 вопросов), x2, x3, x4, x5, x6, x7. Использованы 3 лингвистических значения для каждой из них: n (низкий), s (средний), v (высокий). Функции принадлежности для термов – треугольные.
Даны 6 нечетких правил для выявления типа профессиональной направленности:
R1: IF x1=v AND x2=n AND x3=s AND x4=s AND x5=n AND x6=s AND x7=n THEN y=1
R2: IF x1=n AND x2=s AND x3=n AND x4=v AND x5=n AND x6=s AND x7=n THEN y=2
R3: IF x1=n AND x2=s AND x3=n AND x4=n AND x5=s AND x6=n AND x7=s THEN y=3
R4: IF x1=n AND x2=n AND x3=s AND x4=n AND x5=s AND x6=n AND x7=s THEN y=4
R5: IF x1=n AND x2=n AND x3=n AND x4=n AND x5=s AND x6=n AND x7=s THEN y=5
R6: IF x1=n AND x2=n AND x3=n AND x4=n AND x5=n AND x6=n AND x7=s THEN y=6
Построена обучающая последовательность, состоящая из 174 пар «вход» – «требуемый выход».
Перед обучением нейро-нечеткой сети была задана точность E=0,005 и число эпох C=1000. Сходимость сети достигнута за 568 эпох.
Проверка возможности сети правильно классифицировать пользователей выполнена на 84 парах «вход» – «требуемый выход», которые не использовались при обучении. В итоге было подучено только 3 ошибочных решения.
Также выполнено исследование нейросетевой модели теста Холланда, разработанной по принципу самоорганизующейся карты Кохонена. На входе модель принимает ответы на тестовые вопросы и определяет класс (тип профессиональной ориентации), которому соответствует испытуемый пользователь. Как и в гибридной модели, для настройки использована та же обучающая выборка, но за исключением того, что входные векторы были размерности i=42 и состояли из бинарных значений, а данные типа T (требуемый выход) не использовались при настройке сети. Алгоритм кластеризации Кохонена «Победитель забирает все» не требует участия учителя, т.е. в выборке для настройки сети отсутствуют данные типа «требуемый выход».
Соревновательный слой первой модели состоял из 9 нейронов на гексагональной сетке 3x3. После 1000 эпох настройки сети была получена топографическая карта, показанная на рис. 4. Положение нейронов определяется массивом весовых векторов.
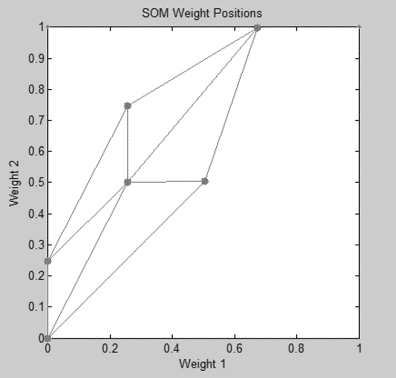
Рис. 4. Топографическая карта
Полученная сеть была проверена с помощью тестовой выборки из 84 входных векторов. Точность распознавания составила 61,3%.
Заключение
Появление автоматизированных средств обучения позволило по-новому сформулировать требования адаптивного обучения и контроля знаний. Поскольку основную часть рутинной работы берет на себя компьютерная техника, то сегодня во главу угла ставится не только и не столько оптимальная загрузка преподавателя, сколько достижение более высокого уровня знаний учащимися.
Совершенствование адаптивных методов обучения и контроля знаний и умений является одним из основных трендов развития современной системы образования. Это актуально не только для дистанционных форм обучения, но и для обычного обучения с участием преподавателей. В этом случае адаптивные компьютерные методы обучения выполняют существенную корректирующую роль, выступают в качестве одной из главных компонент самостоятельной работы студентов.
Наряду с зарубежными разработками в настоящее время выполняется много отечественных исследований в данной области. Однако острой остается проблема повсеместного внедрения новых разработок. Результаты перспективных исследований ограничиваются внедрением в рамках предприятия, вуза или, максимум, сети вузов и теряют со временем свою актуальность. Внедрение в масштабах государства или в мировых масштабах невозможно в связи с неприемлемыми издержками покупателей: затратами на пересылку, развертывание и поддержку программных продуктов. Необходимость создания условий преодоления этого барьера, а именно, регламентации процессов разработки электронных учебных материалов и приведения программных продуктов к соответствию стандартам, прослеживается во многих трудах.
В целях воплощения идеи адаптивного диалога между пользователем и обучающей программой и с учетом массовости электронного обучения, разработчики пришли к необходимости разделения электронных учебных курсов и систем управления обучением. Тенденция к стандартизации процессов разработки материалов образовательной направленности получила международное признание среди предприятий и организаций, специализирующихся в данной отрасли. Практика следования стандартам не ограничивает набор технологий для разработки электронных учебных материалов, а лишь снабжает разрабатываемые системы набором полезных свойств, одним из которых является машинонезависимость. Кроме того, на фоне такого подхода, задача создания универсальных средств разработки электронных учебных курсов приобретает материалистический характер и по-прежнему может рассматриваться как отдельная проблема или в рамках задачи разработки адаптивных систем управления обучением.
По-прежнему не полностью освещенными остаются вопросы моделирования новых элементов учебного контента, механизмов оценки знаний и управления последовательностью изложения учебных материалов.
В связи с недостаточной проработкой данных вопросов в условиях перехода к стандартизации электронного обучения, появляется актуальная задача их рассмотрения в рамках международных стандартов и спецификаций.
1. Живенков А.Н. Аналитические и процедурные
модели в интеллектуальной информационной системе адаптивного структурирования
образовательного контента. Дис. к.т.н., Тамбов, 2012.
2. Залещанский А.П., Свиридов А.П., Шалобина
О.А., Шалобина Е.А. Экономические стратегии управления процессами динамики
знаний. Открытое образование, №4, 2011.
3. Катаев А.В. Программно-информационная
поддержка процесса разработки обучающих компьютерных игр. Дис. к.т.н., Волгоград,
2012.
4. Курзыбова Я. В. Проектирование алгоритма
функционирования адаптивных обучающих модулей в нотации UML. Открытое образование, №1, 2011.
5. Смирнов А.В., Левашова Т.В., Шилов Н.Г.
Конфигурирование сервис-ориентированных сетей ресурсов для интеллектуальной
поддержки дистанционного образования. Открытое образование», №4, 2010.