Дьякова В.Н.., доценты Дьяков И.А.,
Коробова И.Л.
ФГБОУ ВПО «ТГТУ», Россия
МОДИФИКАЦИЯ АЛГОРИТМА РАСПОЗНАВАНИЯ
КЛАВИАТУРНОГО ПОЧЕРКА
Рассматриваемый алгоритм идентификации личности основывается на
биометрических особенностях каждого человека, и использует особенности набора
текста на клавиатуре, которыми являются время удержания клавиши и время между
нажатиями клавиш.
Для идентификации пользователей создаётся
база данных контрольных фраз, содержащая следующие параметры [1]:
-
минимальное время
удержания каждой для клавиши;
-
максимальное время
удержания каждой для клавиши;
-
среднее время удержания
для каждой клавиши ![]() ;
;
-
минимальная пауза между
нажатиями для каждой пары клавиш;
-
максимальная пауза между
нажатиями для каждой пары клавиш;
-
средняя пауза между нажатиями
для каждой пары клавиш ![]() ;
;
-
идентификатор
пользователя (имя пользователя).
Предлагается модифицировать классический
алгоритм следующим способом. На этапе создания БД для уменьшения погрешности
вводимых данных необходимо скорректировать интервал с учетом возможной ошибки. Вариантом
такой корректировки является размещение полученного интервала симметрично
относительно найденной средней величины времени.
Рассмотрим пример ввода контрольной фразы
«password». На рисунке 1 представлены результаты экспериментов. Мы видим, что
пользователь вводил фразу 6 раз. Для паузы между парой букв «sw» мы имеем 6
значений времен: 27, 25, 23, 20, 18, 3
при этом значение 3 явно выделяется из общего набора. Это число и вносит
погрешность в данные, растягивая интервал вниз, хотя мы видим что наиболее
вероятной зоной является интервал (18;27). Поэтому, чтобы это исправить, мы
находим среднее значение ~19 и длину интервала 24, затем откладываем по
половине значения длины интервала в обе стороны от среднего значения, тем самым
центрируя интервал относительно среднего значения, получая новый интервал (7;31).
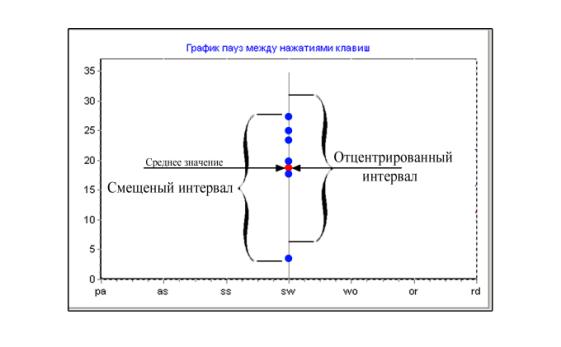
Рис.1.
Иллюстрация к расчёту временных характеристик
Таким образом, полученный новый интервал
смещен в более вероятную область. Также можно смещать интервал пропорционально
количеству значений в данной области, т.е. т.к. в верхней области находится
~80% значений, то интервал можно разместить ближе к верхней части. Для этого
можно использовать формулу:
Верхняя часть интервала должна быть
смещена на U, а нижняя на D относительно среднего значения
![]() ,
, ![]()
где L
– общая длина интервала; k – общее количество значений; n,m–количество значений
над и под средним значением соответственно.
Для входа в систему пользователь вводит
контрольную фразу один раз. При этом мы
получаем два массива: первый со временами удержания, а второй с паузами между
нажатиями клавиш. После чего мы должны идентифицировать пользователя среди
зарегистрированных, в противном случае выдать сообщение об отказе в доступе.
Сравнение происходит по следующему
алгоритму.
Сначала нормируются все максимальные и
минимальные значения, разделив их на соответствующие средние значения:
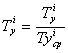
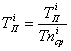
где ![]() - время удержания i-й клавиши,
- время удержания i-й клавиши, ![]() -среднее время удержания i-й клавиши;
-среднее время удержания i-й клавиши; ![]() - пауза между нажатиями i-й пары клавиш,
- пауза между нажатиями i-й пары клавиш, ![]() -средняя пауза между нажатиями этой же пары клавиш.
-средняя пауза между нажатиями этой же пары клавиш.
Далее нормируются значения, которые пользователь
ввел для входа в систему:
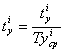
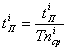
где t - характеристики,
которые пользователь вводит один раз для входа в систему; T - эталонные значения характеристик для n-ого
пользователя из базы зарегистрированных пользователей.
Далее все работы выполняются в приведенных
эталонных максимальных и минимальных значениях времен удержания и пауз, а также
приведенных проверяемых (тестируемых) наборах значений (характеристик).
Литература
1. Широчин, В.П. Динамическая
аутентификация на основе анализа клавиатурного почерка // В.П Широчин, А.В. Кулик,
В.В./ http://masters.donntu.org/2002/fvti/aslamov/files/Bio_Autentification.htm