Образование
и наука XXI века - 2010 / 3. Программное обеспечение
к.т.н.,
доц. Томашевський О.М.
Львовский
филиал Европейского университета, Украина
Анализ результатов мониторинга вычислительного кластера
средствами NAGIOS
Мониторинг
рабочих станций (РС) вычислительного кластера необходим для определения
максимальной пропускной способности ресурсов последнего, планирования и
определения параметров нагрузки на систему, что обуславливает эффективное
использование кластера для решения распределенных задач. Качество наблюдений за
основными характеристиками РС, такими как загруженность RAM Usage
(Random-Access Memory, оперативной памяти), центрального процессора CPU
(Central Processing Unit) и системы в целом System Load, входящего/исходящего
трафика IO (Input/Output), непосредственно влияет на результаты мониторинга.
Однако, даже при равномерном съеме показателей загруженности системы, с
достаточными для достижения необходимой точности временными интервалами, анализ
результатов может усложниться несоответствующим отображением или хранением
полученных данных.
Современные
средства мониторинга компьютерных систем и сетей представлены рядом программ:
как коммерческих – Solar Winds, 3COM Network Superviser, HP OpenView и т.д.;
так и с открытым кодом – например Nagios [2], Big Brother, Angel Network
Monitor, HiWayS, MARS, Autostatus, NocMonitor, RITW, Zabbix, NetXMS, OpenNMS.
Средства с открытым кодом (Open Source), в отличие от коммерческих приложений,
бесплатны и компенсируют, как правило, меньшую функциональность возможностью
неограниченного расширения свойств путем создания дополнительных модулей
(скриптов, плагинов). У каждого из вышеупомянутых приложений для мониторинга
работы компьютерных систем есть свои преимущества и недостатки, что определяет
целесообразность их использования с учетом специфики конкретной задачи или
конфигурации компьютерной системы. Также, от особенностей средства мониторинга
зависит представление результатов, их предварительная обработка и сохранение.
Рассмотрим специфику сохранения результатов мониторинга загруженности РС
вычислительного кластера в зависимости от временного интервала инструментом
Nagios.
Программа
Nagios, известная ранее как Netsaint, разработана Этаном Галстадом (Ethan
Galstad), который продолжает поддерживать и развивать систему сегодня, вместе с
командой разработчиков выпуская официальные и неофициальные плагины.
Первоначально, Nagios предназначалась для работы под GNU/Linux, но на
сегодняшний день она также корректно работает и под другими операционными
системами, такими как Sun Solaris, AIX и HP-UX.
Среди
возможностей Nagios необходимо отметить следующие [3]:
· мониторинг сетевых сервисов (SMTP, POP3, HTTP, NNTP,
ICMP, SNMP);
· мониторинг состояния хостов (загруженность процессора,
использование дисков, системные логи);
· поддержка удаленного мониторинга через шифрованные
туннели SSH или SSL;
· простая архитектура модулей расширения (плагинов),
позволяющая использовать любой язык программирования по выбору: Shell, C, Perl,
Python, PHP, C # и другие (пример кода плагина приведен ниже);
· параллельная проверка сервисов;
· возможность задавать иерархию хостов сети, определять
и отличать неисправные и недоступные;
· отправка сообщения при проблемах с сервисом или хостом
(с помощью электронной почты, пейджера, SMS, или любым другим
способом, заданным пользователем через модуль системы);
· возможность конфигурирования обработчика событий,
происходящих с сервисами или хостами для проактивного решения проблем;
· автоматическая ротация лог-файлов;
· возможность организации совместной работы нескольких систем
мониторинга с целью увеличения надежности и создания распределенной системы
наблюдения за процессами;
· утилита nagiostats, формирующая общий отчет по всем
наблюдаемым хостам.
Код модуля расширения проверки загруженности РС для
Nagios:
|
class checker : public plugin { public:
checker(int argc, char **argv);
virtual ~checker(); static
const char* temp_file; static
bool isnumeric(const char* str); static
opt long_options[]; enum
traffic_direction {d_all, d_in, d_out}; protected: private: long
long traffic; long
long difference;
string interface;
int direction; long
long warning_threshold; long
long critical_threshold;
bool help_exist;
string get_result_string()
const;
void set_option_exist(int
opt);
bool is_help_option_exist()
const;
int get_option_index(int
opt) const;
bool parse_args(int argc,
char **argv);
string
get_command(traffic_direction direct);
void save_new_data(const
string& in_result, const string& out_result,
string& old_in_result, string& old_out_result);
virtual void check_result();
virtual bool is_options_valid() const;
virtual void print_help() const;
virtual void print_options() const;
virtual void print_examples() const;
virtual void print_usage(bool badargs = false) const;
virtual void check(); friend
int main(int argc, char **argv);}; |
При
создании модуля расширения мониторинга загруженности РС вычислительного
кластера для Nagios указывалось, какие именно показатели необходимо снимать
(RAM Usage, CPU, System Load, IO), частоту наблюдения, стиль отображения
результатов – табличным способом или графически.
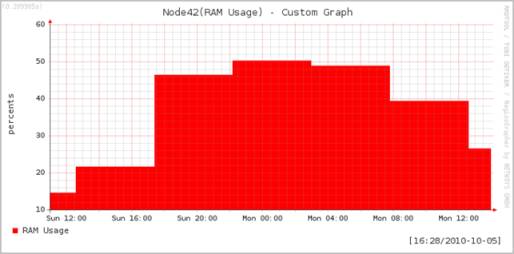
Рис.1. Результат мониторинга загруженности оперативной памяти РС
вычислительного кластера с периодом 4 ч. (по
оси абсцисс отмечено время точки наблюдения, по оси ординат – загрузка RAM в
процентах)
Графическое
отображение результатов мониторинга представляется наиболее целесообразным
вследствие лучшего визуального восприятия по сравнению с табличными данными
(рис.1). Заметим, что независимо от указанного способа представления
результатов, последние в полном виде сохраняются на жестком диске в виде
массива (таблицы) через заданные временные интервалы.
Однако,
со временем результаты наблюдений, для оптимального и экономного использования
компьютерной памяти, автоматически подвергаются усреднению 100:1 [1],
независимо от способа их отображения. Соответственно, при использовании
усредненных значений полученных результатов мониторинга невозможно отследить
реальную динамику загруженности (рис.2) в более короткий период наблюдений и
сделать вывод про критический предел запущенных в системе задач.
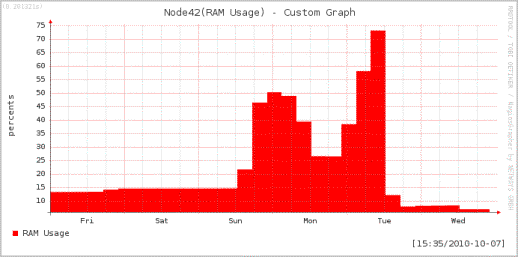
Рис.2. Усредненный
результат мониторинга загруженности оперативной памяти РС вычислительного кластера
Решением
рассмотренной выше проблемы может служить реализация автоматического
распределенного сохранения всех результатов мониторинга – добавление в плагин
контроля загруженности процедуры копирования содержания результирующей таблицы
с заданным временным интервалом, что исключает процесс усреднения, на
специально предназначенный жесткий диск – данной РС или сервера. При этом нужно
учесть дополнительную нагрузку на CPU РС
во время проведения копирования, которая может повлиять на результаты мониторинга
системы в целом, и внести необходимые модификации в код модуля проверки
загруженности РС.
Литература:
1.
Wolfgang
Barth. Nagios. System and Network Monitoring. 2nd Edition. – San Francisco: “No
Starch Press”, 2008.– 719 с.
2.
http://www.nagios.org/
3.
http://en.wikipedia.org/wiki/Nagios

