Филологические науки/
7. Язык, речь, речевая коммуникация
К.филол.наук
Цапенко Л.Е., к.филол.наук Попович Е.С., Гвоздь О.В.
ИСПОЛЬЗОВАНИЕ МЕТОДОВ
ЛИНГВОСТАТИСТИКИ
ДЛЯ ОПИСАНИЯ СТАТИСТИЧЕСКИХ ХАРАКТЕРИСТИК
ТЕКСТОВ НАУЧНОЙ КОММУНИКАЦИИ
В связи с
ростом и усложнением научно-технической информации большое значение приобретает
глубокое и многоаспектное изучение научного стиля, который является одним из
наиболее развитых и разветвленных функциональных стилей современного языка.
Именно в научном стиле наиболее полно реализуется важнейшая социальная функция
языка – фиксировать, сохранять и передавать
научно-техническую информацию. Поэтому в последнее время возросло число
исследований, посвященных изучению научного стиля [1; 3; 4; 8].
Одной из важнейших проблем, которую разрабатывают
лингвисты, исследующие текстовые корпусы, является проблема применения
математического аппарата и методов статистики [2; 6; 10 -12].
Цель
данной работы – рассмотреть формулы и процедуры лингвостатистики, которые
используются в практике для описания статистических характеристик текстов
научно-технического дискурса, определения надежности и достоверности полученных
результатов. Тематика статьи определяет ее актуальность.
Для
достижения указанной цели необходимо было решить следующую задачи: представить
все необходимые условия, выдвигаемые лингвостатистикой, для формирования
надежных вероятностно-статистических моделей подъязыков научного дискурса.
Поскольку
для определения интегральных и дифференциальных признаков текстов научно-технического
дискурса необходимо использовать несколько подъязыков научной коммуникации, исследование
проводилось на материале следующих текстовых корпусов: “Теплотехника”, “Химическое
машиностроение” и “Акустика и ультразвуковая техника”. Они формировались на базе американских и английских журналов IEEE Transactions on Power Apparatus and Systems, IEEE
International Conference on Acoustics, Speech and Signal Processing, The Journal
of the Acoustic society of America, и др. методом сплошной выборки. Объем каждого текстового
корпуса составил не менее 100 тыс. словоупотреблений, т.е. суммарный объем был
300 тыс. словоупотреблений.
Следующим
условием является достаточность объема выборки, которая обычно проверяется по принятой
в лингвистике формуле:
![]() ,
[9, с. 296]
,
[9, с. 296]
где f – относительная частота
явлений (количество случаев, деленное на количество слов в выборке); ![]() –
относительная ошибка; Sр – применяемый в лингвистических исследованиях коэффициент,
равный 1,96 [9, с.295]; N – минимальный объем для получения достоверных сведений
суммарной выборки (в словоформах).
–
относительная ошибка; Sр – применяемый в лингвистических исследованиях коэффициент,
равный 1,96 [9, с.295]; N – минимальный объем для получения достоверных сведений
суммарной выборки (в словоформах).
Если исследование посвящено анализу
какой-либо единицы текста, то ученые-статистики рекомендуют обязательно
определить погрешность функционирования данной единицы в текстовых корпусах. В
нашей работе в качестве примера, на котором демонстрируется использование того
или иного метода лингвостатистики, были взяты глагольные словоформы. При
обследовании текстов упомянутых трех подъязыков, относительная частота (f),
например, видо-временных
парадигматических форм финитного глагола равна 0,06, так как объем одной
сплошной выборки составил 100 тыс. словоупотреблений, и из 25 журнальных статей
каждой выборки трех подъязыков было отобрано, соответственно, 6126; 5607; 6084
глаголов в личной форме. Вычисление относительной погрешности при таком объеме
каждой выборки показало, что она равна:
![]()
Полученные
данные (f, ![]() ) были
использованы в формуле
) были
использованы в формуле
![]() .
.
Иными
словами, отобранное количество примеров при ![]() =2,5 %
покрывает 97,5 % текста, т.е. при точности 97,5 % это количество обеспечивает
достоверность статистических характеристик на выборке объемом 96 000
словоупотреблений.
=2,5 %
покрывает 97,5 % текста, т.е. при точности 97,5 % это количество обеспечивает
достоверность статистических характеристик на выборке объемом 96 000
словоупотреблений.
Поскольку
принято считать, что суммарная выборка является вполне достаточной, если она
охватывает 70-60 % генеральной совокупности текстов, а относительная ошибка при
анализе лингвистических явлений принимается в пределах от 3 % до 25 % [8, с.52;
9, с.296], то объем описываемой в статье выборки, вычисленным по формулам
лингвостатистики, представляется вполне достаточным для получения надежных
результатов.
Статистический
подход к изучению текста предполагает использование определенного
математического аппарата для различных целей,
в нашем случае – для получения объективных данных по расхождению частот
языковых единиц в одном и том же массиве или в разных массивах. Таким образом,
было проведено исследование в пределах каждого подъязыка также и в
сопоставительном плане, что дало возможность выявить интегральные и
дифференциальные признаки подъязыков на любом языковом уровне.
Более
высокие или низкие частоты сравниваемых языковых единиц образуют
статистические параметры текстов и позволяют судить об их стилистической
отнесенности.
В
данной работе в качестве примера представлены математические вычисления, которые
проводились для стандартной выборки, с
ограниченным объемом в 1000 словоупотреблений. При проведении статистического
анализа для каждой видо-временной формы была вычислена средняя частота для такой
выборки по формуле
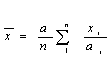 [7, с.36],
[7, с.36],
где ![]() - принятий общий объем выборки
- принятий общий объем выборки
![]() -
количество текстов выборки
-
количество текстов выборки
![]() -
абсолютная частота данной формы
-
абсолютная частота данной формы
![]() - объем
каждого текста (условно называемый подвыборкой).
- объем
каждого текста (условно называемый подвыборкой).
Затем,
после вычисления средней частоты, было выявлено среднеквадратичное отклонение (![]() ) и величина изменения средней частоты (
) и величина изменения средней частоты (![]() ) по формулам:
) по формулам:
a) ![]() [8, с. 32-34],
[8, с. 32-34],
где (![]() ) - разница между каждой абсолютной частотой и средней
) - разница между каждой абсолютной частотой и средней
![]() - количество выборки с абсолютной частотой
- количество выборки с абсолютной частотой
N - количество выборок, взятых для
исследования
б) ![]()
Кроме
того, с помощью величины колебаний средней частоты (![]() ) выявлена относительная ошибка исследования для
каждой видо-временной формы глагола:
) выявлена относительная ошибка исследования для
каждой видо-временной формы глагола:
![]()
Сравнение процентных показателей
частот сопоставляемых величин проводилось по формуле
![]()
где ![]() –
процентный показатель первой группы;
–
процентный показатель первой группы;
![]() –
процентный показатель второй группы;
–
процентный показатель второй группы;
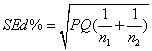 , где
, где ![]() ,
,
![]() – среднее
арифметическое процентных показателей двух групп;
– среднее
арифметическое процентных показателей двух групп;
![]()
![]() –
абсолютная частота признака первой группе;
–
абсолютная частота признака первой группе;
![]() –
абсолютная частота признака в сравниваемой группе.
–
абсолютная частота признака в сравниваемой группе.
Число
степеней свободы определяется по формуле
![]()
где ![]() – количество выборок в одном подъязыке;
– количество выборок в одном подъязыке;
![]() –
количество выборок в сравниваемом подъязыке.
–
количество выборок в сравниваемом подъязыке.
Показатель
степеней свободы служит для определения критической величины критерия Стьюдента
по соответствующей таблице, представленной в
[8]. Величины выше критической свидетельствуют о существенных
расхождениях частот.
Корреляционный
анализ проводился по формуле
с =
![]()
где с – коэффициент корреляции
рангов;
![]() – разность между
рангами частот двух признаков в одной
совокупности текстов;
– разность между
рангами частот двух признаков в одной
совокупности текстов;
![]() –число
строк (признаков).
–число
строк (признаков).
Для
оценки характера колебания частот вычислялся (по каждой форме глагола)
коэффициент вариации ( V )
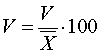
который показывает отношение
среднего квадратичного отклонения к средней частоте выраженное в процентах.
Критический порог коэффициента вариации равен 40 %, выше которого варьирование
частот в выборках не случайно, а закономерно.
Анализ
частот употребления видо-временных форм глагола в каждом подъязыке, и
сопоставление подъязыков по общей частоте дает возможность проследить
своеобразие реализации форм глагола в конкретных условиях и установить статистические параметры
подъязыков техники, образованные грамматическими категориями глагола.
Все
вышесказанное позволяет сделать следующие выводы. Изучение современных работ, посвященных данной проблематике,
практическое применение математического аппарата в исследовании статистических
характеристик текстов научного стиля, показало, что оптимальным для исследований такого характера является
сочетание методов сплошного анализа текста, структурно-вероятностного анализа,
элементов дистрибутивного анализа, сопоставительного анализа на различных
языковых уровнях с применением математических методов для установления
достоверности полученных результатов. Такое сочетание позволяет в плане
лингвостатистики наиболее полно и всесторонне осветить любую единицу или
явление текстовой выборки [11, 12].
ЛИТЕРАТУРА
1. Береснев С. Д.
Исследование лексики немецких научных текстов
с позиции получателя речи: Автореф. докт. дис./ С. Д. Береснев. – АН
СССР Ин-т языкознания, Ленингр. отд-ние. – Л., 1974. – 35 с.
2. Борисенко Т. И. Особенности
функционирования модальных глагольных конструкций в подъязыках техники / Т. И. Борисенко, М. В. Кашуба, Е. В. Мардаренко, М.В.
Циновая // Записки з романо-германської філології.– Одеса: КП ОМД, 2014. – Вип.
1(32), – С.25-34.
3. Глушко М.М. Лингвистические особенности современного
английского общенаучного языка // Функциональный стиль
общенаучного языка и методы его исследования. М.: Изд-во Моск. ун-та,
1974.
– С. 7-25. (Под ред. О.С.Ахмановой, М.М.Глушко).
4. Глушко М. М.
Синтактика, семантика и прагматика научного текста / М. М. Глушко. – М.: Изд-во
МГУ, 1977. – 207 с.
5. Кауфман С. И. Об
именном характере технического стиля /С. И. Кауфман // Вопросы языкознания. –
1961. – № 5. – С. 103-108.
6. Лутцева М. В. Лексикографическое
описание юридической терминологии в неспециальной сфере использования (На
материале произведений Дж. Гришема): Автореф. дис. ... канд. филол. наук: 10.02.19
“Теория языка”; 10.02.04 “Германские языки” / М. В. Лутцева. - Ярославль, 2008. – 20 с.
7. Носенко И. А.Начала статистики для лингвистов
/ И. А. Носенко. – М.: Высшая школа, 1981. – 160 с.
8. Перебійніс В.І. Методи дослідження. Визначення матеріалу дослідження /
В. І. Перебійніс // Статистичні параметри стилів. – Київ, 1967. – С.23-43.
9. Пиотровский Р.Г. Математическая лингвистика / Р. Г. Пиотровский, К. Б. Бектаев, А. А. Пиотровская.— М.: Высшая школа, 1977 – 383 с. (Учеб. пособие для пед.
институтов).
10. Прянишников Е. А.
Лингво-статистическое исследование текста закона / Е. А. Прянишников //
Актуальные проблемы теории и практики применения математических методов и ЭВМ в
деятельности органов юстиции. V Всесоюзная конференция по проблемам правовой кибернетики.
– М., 1975. – Вып. 2. – С. 129-130.
11. Томасевич Н.П.
Терминологическая лексика подъязыка автомобилестроения и её взаимодействие с
другими лексическими слоями: Автореф. дис. ... канд. филол. наук: 10.02.04 “Германские
языки” / Н.П.Томасевич. – Одесса, 1984.
–20 с.
12. Шапа Л.Н. Формы и
функции имен прилагательных в научно-техническом тексте (на материале
английского подъязыка “Электроснабжение”): Дис…к.филол.наук: 10.02.04 /
Л.Н.Шапа. – Одесса, 1989. – 201 с.