Современные информационные технологии/2.Вычислительная
техника и программирование.
Кратенок А.В.
Белорусский
Государственный Университет Информатики и Радиоэлектроники, Республика Беларусь
Модель исправления ошибок для канала
с шумами
Модель шумового канала применяется к
широкому спектру проблем, включая проверку орфографии. Эти модели состоят из
двух компонентов: исходная модель и модель канала. Для многих приложений люди
потратили много сил и времени, улучшая эти компоненты, в результате получив
улучшение точности во всей системе. Однако, применительно модели проверки
орфографии, относительно небольшие исследования проводились для улучшения
модели канала.
Не рассматривая проблему исправления
специфичных слов, приводящих к сумятице (to, too, two). Проблема проверки
правописания определяется более абстрактно: данному алфавиту ![]() , со
словарём
, со
словарём ![]() состоящим
из строк в
состоящим
из строк в ![]() и
есть строка
и
есть строка ![]() , где
, где ![]() и
и ![]() ,
найдётся такое слово
,
найдётся такое слово ![]() , на
которое похоже ошибочное введённое
, на
которое похоже ошибочное введённое ![]() .
Требование
.
Требование ![]() может
быть опущено, но так следует поступать в контексте достаточно мощной языковой
модели. В вероятностной системе, нужно найти
argmaxw
может
быть опущено, но так следует поступать в контексте достаточно мощной языковой
модели. В вероятностной системе, нужно найти
argmaxw ![]() .
Применяя правило Байеса и опуская постоянный знаменатель ненормированное
постериорное значение: argmaxw
.
Применяя правило Байеса и опуская постоянный знаменатель ненормированное
постериорное значение: argmaxw![]() . Теперь
есть модель канала с шумами для проверки правописания, состоящая из двух
компонентов: исходная модель
. Теперь
есть модель канала с шумами для проверки правописания, состоящая из двух
компонентов: исходная модель ![]() и
модель канала
и
модель канала ![]() .
Модель предполагает, что текст естественного языка выглядит следующим
образом: прежде всего человек выбирает слова в соответствии с распределением
вероятности
.
Модель предполагает, что текст естественного языка выглядит следующим
образом: прежде всего человек выбирает слова в соответствии с распределением
вероятности ![]() . Затем человек
пытается выбрать слово
. Затем человек
пытается выбрать слово ![]() , но
канал с шумами побуждает человека выбрать строку
, но
канал с шумами побуждает человека выбрать строку ![]() вместо
этого, согласно распределению
вместо
этого, согласно распределению ![]() .
Например, в обычных условиях можно было бы ожидать высокое распределение
.
Например, в обычных условиях можно было бы ожидать высокое распределение ![]() ,
, ![]() относительно
высокое и
относительно
высокое и ![]() чрезвычайно
низкое. За модель ошибок можно
определить множество в строке
чрезвычайно
низкое. За модель ошибок можно
определить множество в строке ![]() включая саму
включая саму ![]() вместе со всеми словами
вместе со всеми словами ![]() в
словаре
в
словаре ![]() такими,
что
такими,
что ![]() может быть получено из
может быть получено из ![]() путем применения одной из четырех операций
редактирования:
путем применения одной из четырех операций
редактирования:
– добавление
единичного символа;
– удаление
единичного символа;
– замена
одного символа на другой;
– перестановка
двух соседних символов;
Пусть ![]() - число
слов в множестве
- число
слов в множестве ![]() . Они
определили модель ошибок для всех
. Они
определили модель ошибок для всех ![]() в множестве
в множестве ![]() как:
как:
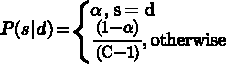
Это очень простая модель ошибок, где слово, введённое до ![]() , правильно
и остальная масса вероятности равномерно распределяется между всеми другими
словами во множестве. Улучшения
можно сделать, связывая вероятности с отдельными операциями редактирования.
Здесь предлагается более общая модель ошибок. Пусть
, правильно
и остальная масса вероятности равномерно распределяется между всеми другими
словами во множестве. Улучшения
можно сделать, связывая вероятности с отдельными операциями редактирования.
Здесь предлагается более общая модель ошибок. Пусть ![]() -
алфавит. Данная модель позволяет проводить все операции редактирования
типа
-
алфавит. Данная модель позволяет проводить все операции редактирования
типа ![]() ,
где
,
где ![]() .
. ![]() -
вероятность того где пользователи намерены ввести строку
-
вероятность того где пользователи намерены ввести строку ![]() вместо
введённой
вместо
введённой ![]() . Кроме того, модель зависит от позиции в
строке над которой выполняется редактирование,
. Кроме того, модель зависит от позиции в
строке над которой выполняется редактирование,
![]() , где
, где ![]() ={начало
слова, середина слова, конец слова}. Позиция определяется по месту нахождения
подстроки
={начало
слова, середина слова, конец слова}. Позиция определяется по месту нахождения
подстроки ![]() в
источнике (словаре) слово. Информация о позиции является мощным средством при
операциях редактирования.
в
источнике (словаре) слово. Информация о позиции является мощным средством при
операциях редактирования.
Используя более общий подход к
моделированию ошибки, можно более точно создать модели ошибок которые делают
люди. Формальное представление модели следующее: пусть функция, которая выделяет
часть слова ![]() , может
дать множество возможных разбиений слова
, может
дать множество возможных разбиений слова ![]() на смежные подстроки (возможно пустые). Для
частичного разбиения
на смежные подстроки (возможно пустые). Для
частичного разбиения ![]() , где
, где ![]() (
(![]() состоит
из
состоит
из ![]() смежных
сегментов). Пусть
смежных
сегментов). Пусть ![]() -
- ![]() -ый
сегмент. Согласно модели:
-ый
сегмент. Согласно модели:
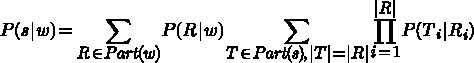
Одна конкретная пара выравнивания
![]() и
и ![]() показывает набор изменений, разделяющий
показывает набор изменений, разделяющий ![]() и
и ![]() . При
рассмотрении лучшего разбиения можно упростить
. При
рассмотрении лучшего разбиения можно упростить

Для обучения модели необходимо множество состоящее из ![]() строковых пар, представленных в виде слов с
ошибкой
строковых пар, представленных в виде слов с
ошибкой ![]() и правильных слов
и правильных слов ![]() .
Начинать следует с выравнивания символов
.
Начинать следует с выравнивания символов ![]() с аналогичными символами
с аналогичными символами ![]() ,
согласно минимальным редактируемым расстояниям между
,
согласно минимальным редактируемым расстояниям между ![]() и
и ![]() ,
основанным на замене, удалении или вставки единичного символа. Если производить обучение на
множестве
,
основанным на замене, удалении или вставки единичного символа. Если производить обучение на
множестве ![]() кортежей
и без наличия ассоциативного текстового блока, можно – из большой подборки представленного текста, посчитать число вхождений
кортежей
и без наличия ассоциативного текстового блока, можно – из большой подборки представленного текста, посчитать число вхождений ![]() ; аппроксимировать
число, основанное на частоте с которой люди делают
ошибки при вводе. Следует обратить
внимание, что поиск по статическому словарю D не является требованием данной
модели с ошибкой. Вполне возможно, что с другой техникой поиска, можно
применить данную модель для других языков таких, как турецкий, для которых
статической словарь не существует или сложноопределим. Учитывая, 200000 слов
словаря, и используя улучшенную модель ошибок, можно проверить правописание
строки, которой нет в словаре примерно в 10 миллисекунд, в среднем на
процессоре с частотой 1.6 ГГц.
; аппроксимировать
число, основанное на частоте с которой люди делают
ошибки при вводе. Следует обратить
внимание, что поиск по статическому словарю D не является требованием данной
модели с ошибкой. Вполне возможно, что с другой техникой поиска, можно
применить данную модель для других языков таких, как турецкий, для которых
статической словарь не существует или сложноопределим. Учитывая, 200000 слов
словаря, и используя улучшенную модель ошибок, можно проверить правописание
строки, которой нет в словаре примерно в 10 миллисекунд, в среднем на
процессоре с частотой 1.6 ГГц.