Современные
информационные технологии/Вычислительная техника и программирование
Мясищев А.А.
Хмельницкий национальный
университет, Украина
О
практическом достижении наибольшей производительности при матричном
перемножении для вычислительных систем
на базе многоядерных процессоров
При
решении, например задач теории упругости, пластичности широко используется
метод конечных элементов. Практическое решение задач этим методом сводится к
решению систем линейных уравнений. Построение этих систем уравнений сводится к
построению так называемой матрицы жесткости, что требует выполнение операций
перемножения матриц. Следовательно, использование наиболее быстрых алгоритмов
расчета для матричных произведений позволяет наиболее эффективно использовать
существующую вычислительную систему. В этой работе рассматривается возможность повышения
производительности стандартной вычислительной системы до 9 раз при решении
задач перемножения квадратных матриц путем перехода от стандартных классических
последовательных алгоритмов к использованию алгоритмов блочного представления
матриц.
Задача
матричного умножения требует для своего решения выполнения большого количества
операций.
Пусть
A,B,C – квадратные матрицы размером n x n.. Матрица C=A*B. Тогда компоненты матрицы C рассчитываются по формуле:
![]()
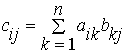
Здесь i ,j=1,…,n..
Для вычисления одного
элемента матрицы C необходимо выполнить n умножений и n-1 сложений. Следовательно, общее
количество операций с плавающей точкой для всех элементов матрицы определится
![]()
![]()
Оценку производительности компьютера будем производить в
Мегафлопсах (1 Mflops - миллион операций с плавающей точкой за одну секунду).
Разделив число операций на время, умноженное на 1000000, получим
производительность системы в Мегафлопсах. Для перемножения квадратных матриц
получим
![]()
![]() (Mflops)
(Mflops)
Наибольшую
производительность попытаемся достичь
на вычислительной системе, построенной на базе одного четырех ядерного процессора CORE 2 QUAD PENTIUM Q6600 2.4GHZ с оперативной памятью 4Гбайт. В
качестве операционной системы будем использовать 32-х и 64-х разрядные Linux Ubuntu ver. 9.04 desktop, компиляторы фортран – F77 и gfortran ver. 4.3.3, которые входят в состав
этих дистрибутивов
Так как вычислительная
система базируется на четырех ядерном процессоре, то программы должны
предусматривать процедуры распараллеливания вычислительного процесса. Для этой
цели будем использовать библиотеки MPI [1].
Рассмотрим
первый подход. В работе [2] представлен фрагмент программы по умножению матриц:
do j=1,n
do k=1,n
do i=1,n
c(i,j)=c(i,j)+a(i,k)*b(k,j)
end do
end do
end do
Показано, что при использовании цикла jki достигается максимальная производительность работы
программы для компилятора ФОРТРАН, который размещает элементы матрицы в памяти
по столбцам т.е.
![]()
Это вызвано тем, что размещаемые в
кеш-памяти элементы матриц A,B,C эффективно используются, когда
доступ к ним или их модификация в
алгоритме умножения матриц производится последовательно с переходом к соседней
ячейке памяти. Также при последовательной выборке увеличивается эффективность
использования кеш-памяти.
Однако
данный алгоритм все же недостаточно эффективно использует кеш-память первого
уровня [2]. Известно, что ее размер для используемого нами процессора не
превышает 32Кбайт для хранения данных на одно ядро. Для эффективного ее
использования целесообразно, чтобы вся матрица могла быть там размещена во время проведения операций умножения. С этой
целью рассмотрим блочное представление матриц. Представим матрицы A,B,C (глобальные матрицы) в виде блоков,
размером (n/N)x(n/N), N - количество блоков по строкам или
столбцам.
![]()
 =AB=
=AB=
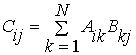
Здесь ![]() - блочные матрицы.
- блочные матрицы.
Ниже представлен
фрагмент программы, реализующий блочное умножение матриц [2].
do j=1,nn
do k=1,nn
do i=1,nn
do j1=1,m
do k1=1,m
do i1=1,m
c(i1,j1,i,j)=c(i1,j1,i,j)+a(i1,k1,i,k)*b(k1,j1,k,j)
end do
end do
end do
end do
end do
end do
Здесь nn=N,
m=n/N. Первые два индекса (i1,j1) массивов – строки и столбцы
конкретной блочной матрицы, последние два индекса (i,j) – координаты блочной матрицы в
глобальной матрице.
Ниже
представлена рабочая программа, реализующая блочный подход вычисления
произведения.
program cpu4_par
include 'mpif.h'
C
n-число
строк и столбцов матриц A,B,C
C
m-число
строк и столбцов в блоке матриц
C
nn-число
строк и столбцов матриц A,B,C,составленных из блоков
parameter (n=5120,m=20,nn=n/m)
integer ierr,rank,size,i,j,k
double precision
a(m,m,nn,nn), b(m,m,nn,nn), c(m,m,nn,nn)
double precision mf,op
double precision time1, time, time2
integer status(MPI_STATUS_SIZE)
call MPI_INIT(ierr)
C size – число ядер
call MPI_COMM_SIZE(MPI_COMM_WORLD, size,
ierr)
C rank – номер ядра
call MPI_COMM_RANK(MPI_COMM_WORLD, rank,
ierr)
do 10 i=1,nn
do 10 j=1,nn
do 10 i1=1,m
do 10 j1=1,m
a(i1,j1,i,j)=1.0d0*(i1+m*(i-1))*(j1+m*(j-1))
b(i1,j1,i,j)=1.0d0/a(i1,j1,i,j)
c(i1,j1,i,j)=0.d0
10 continue
time1 = MPI_Wtime()
c
Цикл по процессорам rank
do j=rank+1,rank+1+(nn-size),size
do k=1,nn
do i=1,nn
do j1=1,m
do k1=1,m
do i1=1,m
c(i1,j1,i,j)=c(i1,j1,i,j)+a(i1,k1,i,k)*b(k1,j1,k,j)
end do
end do
end do
end do
end do
end do
time2 = MPI_Wtime()
time=time2-time1
if(rank.eq.0) then
op=(2.0*n-1)*n*n
mf=op/(time*1000000.0)
print *,' time = ',time, 'mf=',mf
end if
c Распечатка элемента матрицы C
call prinmatr(1000,250,m,nn,c)
call MPI_FINALIZE(ierr)
end
c Подпрограмма для распечатки
элемента глобальной матрицы
subroutine prinmatr(ig,jg,m,nn,c)
double precision c(m,m,nn,nn)
il=ig-m*((ig-1)/m)
jl=jg-m*((jg-1)/m)
mg=((ig-1)/m)+1
ng=((jg-1)/m)+1
print 7,ig,jg,c(il,jl,mg,ng)
7 format(1x,'i=',i5,' j=',i5,' C=',f18.10)
end
Компиляция для F77 и запуск программы проводились
командами:
F77
–O3 –I/usr/local/mpi/include –f –o cpu4_par cpu4_par.f
/usr/local/mpi/lib/libmpich.a
/usr/local/mpi/bin/mpirun
–np 4 –machinefile machines cpu4_par
Для gfortran:
gfortran
–O3 –I/usr/lib/lam/include –o cpu4_par cpu4_par –lmpi
mpirun –np 4 cpu4_par
Программа запускалась с ключом -np 4 (для параллельной работы с 4-я
ядрами) и -np 1 (при работе на 1-м ядре)
Ниже представлены
следующие случаи расчета:
1. Числа двойной точности. 64-х
разрядная версия Linux Ubuntu ver. 9.04 desktop. Используются компиляторы F77 и gfortran. При запуске на одном ядре принимается, что размеры
глобальной блочной матриц совпадают, а при запуске на 4-х ядрах (параллельная
работа) глобальная матрица разбивается на 16 блоков с целью корректной работы
представленной программы. Если глобальная матрица имеет размерность 4000х4000
элементов, то размер блока будет равен 1000х1000 элементов. Результаты
эксперимента показаны в таблице 1. В ней представлены время расчета в секундах
произведения (числитель), производительность в Мегафлопсах (знаменатель),
ускорение счета для 4-х ядерного варианта.
Таблица 1
|
Размер матрицы |
gfortran |
F77 |
||||
|
Одно ядро |
Четыре ядра |
Уско-рение |
Одно ядро |
Четыре ядра |
Уско-рение |
|
|
500х500 |
0.09/2653 |
0.03/8112 |
3.06 |
0.12/2126 |
0.03/8111 |
3.82 |
|
1000х1000 |
1.42/1405 |
0.20/9841 |
7.00 |
1.57/1272 |
0.25/8071 |
6.35 |
|
2000х2000 |
11.81/1355 |
2.48/6442 |
4.75 |
13.00/1231 |
2.91/5499 |
4.47 |
|
4000х4000 |
101.9/1256 |
73.7/1738 |
1.38 |
106.9/1198 |
76.0/1684 |
1.41 |
|
6000х6000 |
341.0/1267 |
250.5/1725 |
1.36 |
357.9/1206 |
257.0/1680 |
1.39 |
Теоретическое ускорение
4-х ядерного варианта счета должно быть около 4-х единиц. Однако для размера
матриц 500х500 оно близко к теоретическому, а для размеров свыше 4000х4000 оно
значительно меньше теоретического и настолько, что не имеет смысла вести
процедуру распараллеливания программ. Однако, например, для размера 1000х1000
ускорение выше теоретического, что объясняется блочным представлением матрицы. Следовательно,
для повышения эффективности при параллельных расчетах необходимо уменьшать
размер блока матрицы. Из таблицы также видно, что программа, скомпилированная
на gfortran для 64-х разрядной системы, работает
быстрее, чем в случае компиляции на F77.
2. Здесь рассматриваются те же
условия расчета, что и в первом случае, но за исключением того, что размер
блочных матриц выбирается из условия достижения наибольшей производительности
расчетов, как для последовательного одноядерного варианта, так и для
параллельного многоядерного. Результаты эксперимента представлены в таблице 2.
Таблица 2.
|
Размер матрицы |
gfortran |
F77 |
||||
|
Одно ядро |
Четыре ядра |
Уско-рение |
Одно ядро |
Четыре ядра |
Уско-рение |
|
|
1000х1000 |
- |
- |
- |
0.94/2129 |
0.23/8704 |
4.09 |
|
1280х1280 |
1.14/3694 |
0.29/14425 |
3.90 |
- |
- |
- |
|
2000х2000 |
4.41/3630 |
1.15/13952 |
3.84 |
7.53/2126 |
1.56/10231 |
4.81 |
|
2560х2560 |
9.27/3618 |
2.34/14359 |
3.97 |
- |
- |
- |
|
4000х4000 |
35.4/3620 |
9.47/13509 |
3.73 |
60.5/2114 |
15.0/8548 |
4.04 |
|
5120х5120 |
74.4/3607 |
20.2/13317 |
3.69 |
- |
- |
- |
|
6000х6000 |
120.4/3588 |
34.3/12580 |
3.51 |
205.5/2102 |
50.8/8500 |
4.04 |
Размер блочных матриц,
для которых получалась наибольшая производительность для компилятора gfortran, примерно равен 20х20, для F77 – 200х200 элементов. Из таблицы
2 видно, что gfortran примерно в 1.5 раза для 64-х разрядных систем эффективнее,
чем F77.
Ускорение счета при параллельном вычислении для 4-х ядерного процессора
примерно соответствует теоретически достижимому, т.е. – четырем. Это свидетельствует о том, что кеш-память
используется эффективно. Для матриц большого размера (> 4000х4000)
производительность возросла более чем в 7 раз. С увеличением размера матрицы
производительность слабо уменьшается.
3. Здесь рассматривается те же
условия, что и во 2-м случае, однако расчеты проводятся для чисел одинарной
точности и для 4-х ядер. Результаты представлены в таблице 3.
Таблица 3.
|
Размер матрицы |
gfortran |
F77 |
|
Четыре ядра |
Четыре ядра |
|
|
1280х1280 |
0.14/30534 |
- |
|
2000х2000 |
0.51/31160 |
0.79/20150 |
|
4000х4000 |
4.34/29465 |
6.36/20138 |
|
6400х6400 |
17.8/29488 |
32.5/16131 |
|
8000х8000 |
35.9/28551 |
63.4/16139 |
Из таблицы 3 видно, что
для чисел одинарной точности производительность по сравнению с числами двойной
точности удваивается. Для больших матриц (> 6000х6000) компилятор gfortran почти в два раза эффективнее F77 для 64-х разрядных систем.
4. Числа двойной точности. 32-х
разрядная версия Linux Ubuntu ver. 9.04 desktop. Используются компиляторы F77 и gfortran. Размер блочных матриц выбирается из условия достижения
наибольшей производительности расчетов, как для последовательного одноядерного
варианта, так и для параллельного многоядерного. Результаты эксперимента
представлены в таблице 4.
Таблица 4.
|
Размер матрицы |
gfortran |
F77 |
||||
|
Одно ядро |
Четыре ядра |
Уско-рение |
Одно ядро |
Четыре ядра |
Уско-рение |
|
|
1000х1000 |
1.17/1705 |
0.24/8460 |
4.96 |
1.06/1878 |
0.24/8486 |
4.52 |
|
2000х2000 |
9.39/1704 |
1.89/8474 |
4.97 |
8.23/1939 |
1.76/9088 |
4.67 |
|
4000х4000 |
75.2/1702 |
18.9/6772 |
3.98 |
66.2/1932 |
16.7/7672 |
3.97 |
Из таблицы 4 видно, что
для 32-х разрядных систем компилятор F77 работает несколько быстрее gfortran. Сопоставление таблиц 2 и 4
показывает, что для 64-х разрядных систем компилятор gfortran примерно в 1.5-1.8 раза показывает
большую производительность, чем для 32-х. Компилятор F77 для 64-х разрядных систем не
дает существенного выигрыша в производительности по сравнению с 32-х
разрядными.
5.Условия расчета, что и для 4-го
случая, но рассматриваются числа одинарной точности. Расчеты проводятся для 4-х
ядер в параллельном режиме. Результаты представлены в таблице 5.
Таблица 5
|
Размер матрицы |
gfortran |
F77 |
|
Четыре ядра |
Четыре ядра |
|
|
1000х1000 |
0.24/8274 |
0.22/9087 |
|
2000х2000 |
1.86/8584 |
1.62/9848 |
|
4000х4000 |
14.4/8864 |
12.7/10082 |
|
6400х6400 |
75.3/6962 |
66.5/7887 |
Из таблицы 5, как и для предыдущего
случая, видно, что для 32-х разрядных систем компилятор F77 работает несколько быстрее gfortran. Сопоставление таблиц 4 и 5
показывает, что для чисел двойной и одинарной точности для 32-х разрядных
систем разница в скорости расчетов не существенная.
Выводы.
1.Существенное увеличение
производительности при матричных вычислениях для многоядерных систем возможно благодаря
блочному представлению исходных глобальных матриц. В этом случае удается
достичь теоретического ускорения при распараллеливании по ядрам процессора.
2.Использование 64-х разрядных
систем позволяет в 1.5-1.8 раз поднять производительность расчетов по сравнению
с 32-х разрядными.
3.Для 64-х разрядных систем
значительно эффективнее использовать компилятор gfortran, который по сравнению с F77 дает прирост производительности
в 1.5-1.8 раза. Для 32-х разрядных систем компилятор F77 работает немного быстрее gfortran.
4.Матричные вычисления одинарной
точности в 64-х разрядных системах выполняются в 2.0-2.2 быстрее, чем двойной точности.
Для 32-х разрядных систем существенного увеличения быстродействия не замечено.
5.Результаты вычислительного эксперимента
показали, что переход к блочному представлению матриц, к 64-х разрядному
программному обеспечению, к компилятору gfortran позволило повысить скорость
расчетов для чисел одинарной и двойной точности примерно в 8-9 раз.
Литература.
1.Гергель В.П. Теория и практика
параллельных вычислений. http://www.intuit.ru/department/calculate/paralltp/
- 2007
2.Высокопроизводительные вычисления
на кластерах: Учебное пособие/ Под ред. А.В.Старченко.- Томск: Изд-во Том.
Ун-та, 2008 – 198 с.
.