Современные информационные технологии.
Информационная безопасность.
Д.т.н. Юдін О.К, Чеботаренко Ю.Б.,
аспірант Чунарьова А.В.,
Національний авіаційний університет(НАУ), Україна
Оцінка
вірогідності сучасних
методів
декодування
Вступ.
Основна функція інформаційно-комунікаційних систем та мереж (ІКСМ) в умовах функціонування інтегрованих інформаційних комплексів полягає в організації оперативного й надійного обміну інформаційними ресурсами, а також у скороченні витрат (організаційних, економічних, технічних тощо) на передачу даних. Головний показник ефективності ІКСМ — час передачі інформації від джерела повідомлення до споживача, її кількість та якість.
Завдання
забезпечити базові властивості інформаційних ресурсів (цілісність, доступність,
конфіденційність) при використання сучасних методів завадостійкого кодування та
декодування є одним із найактуальніших питань при розробці та експлуатації
інформаційних систем та їх елементів. Ця актуальність підтверджується й
вимогами, щодо загального часу на обробку та передачу даних, а також припустимої
ймовірності появи помилок у повідомленнях, яку слід розуміти як: імовірність
порушення цілісності кодових слів, які передаються по каналах зв’язку, або обробляються.
Постановка задачі. Ефективність
роботи моделей вирішальних процедур статистичних правил прийняття рішення для
задач вірогідної ідентифікації та відновлення інформаційних потоків даних, оцінюється
рядом характеристик, до основних з яких відносять: ймовірність правильної ідентифікації
повної кодової конструкції, час на процес кодування/декодування, надмірність
(або надлишковість) кодового слова, неспотворена передача даних, тощо.
Метою роботи є проведення порівняльного аналізу розробленого методу відновлення повної кодової конструкції на основі визначення мінімально-достатньої кількості інформації з існуючими методами завадостійкого кодування/декодування.
До задач,
також віднесено формування структурно-аналітичної моделі реалізації методу
відновлення кодових конструкцій на базі мінімально-достатньої кількості
інформації, а також проведення аналізу її адекватності для задач вірогідного
декодування інформаційного потоку даних. Результатом даних досліджень повинно бути визначення оцінки ефективності, а саме
точності правильної ідентифікації вирішальних процедур статистичних правил
прийняття рішення з умов забезпечення достовірності і цілісності кодових
конструкцій. На базі математичного моделювання, в ході роботи, сформуємо
графічні залежності ймовірності появи не коригованих помилок ![]() кратності
кратності ![]() від співвідношення сигнал/шум
від співвідношення сигнал/шум
![]() .
.
Аналіз
існуючих методів кодування/декодування з умов появи не коригованих помилок
Розвиток інформаційно-комунікаційних систем та мереж тісно пов'язаний з
підвищенням достовірності передачі даних при ризькому збільшенні обсягів
переданої інформації. Вирішення даної проблеми за рахунок підвищення
енергетичних ресурсів системи на даному етапі неефективне та практично себе
вичерпало. Одним з головних напрямів забезпечення цілісності та достовірності
інформаційних потоків є використання завадостійкого канального кодування, а
саме блокових і згорткових кодів.
Сучасні ІКСМ, широко використовують існуючі надлишкові коди з виявленням помилок (вони лише
виявляють помилку) та коди з
коригуванням (ці коди виявляють
місце помилки і виправляють її). Для різних типів завад в каналі зв’язку існують різні по своїй
структурі і надмірності конструкції - завадостійкі коди. Зазвичай надмірність
коду знаходиться в межах 10…60% або трохи більше.
Також, широко використовуються: блокові коди – для швидкого виявлення помилок (NMT-450, DECT) та згорткові коди – для виправлення одиночних помилок (GSM,CDMA). Найбільш поширеними серед блокових кодів є коди з перевіркою на парність, матричні коди, коди Хемінга, циклічні коди (коди Боуза-Чоудхурі-Хоквінема та Ріда-Соломона).
На даний
час існуючі види завадостійкого кодування/декодування відрізняються один від
одного наступними характеристиками: швидкістю, надмірністю, корегуючою
здатністю, структурою, функціональним призначенням, енергетичною ефективністю.
Вибір певного типу завадостійкого коду з відповідними характеристиками
безпосередньо залежить від вимог, щодо достовірності та цілісної передачі
інформації. Ймовірність виникнення помилки![]() , надлишковість
, надлишковість ![]() і кількість канальних
біт
і кількість канальних
біт ![]() (розмір кодового
слова) є основними характеристиками завадостійкого коригувального коду, що
визначають рівень завадостійкої передачі кодових конструкцій. Основним
завданням, яке постає при оцінці ефективності розроблюваних методів це
досягнення найменших значень
(розмір кодового
слова) є основними характеристиками завадостійкого коригувального коду, що
визначають рівень завадостійкої передачі кодових конструкцій. Основним
завданням, яке постає при оцінці ефективності розроблюваних методів це
досягнення найменших значень ![]() та
та ![]() . При використанні типу завадостійкого кодування для
підвищення достовірності та цілісності інформаційних потоків ІКСМ потрібно
врахувати: розподіл помилок в каналі зв’язку; допустиму ймовірність появи
помилок в кодовій комбінації; складність алгоритмів кодування та декодування.
. При використанні типу завадостійкого кодування для
підвищення достовірності та цілісності інформаційних потоків ІКСМ потрібно
врахувати: розподіл помилок в каналі зв’язку; допустиму ймовірність появи
помилок в кодовій комбінації; складність алгоритмів кодування та декодування.
Одним з основних факторів вибору коду є характер розподілу помилок в каналі зв’язку, який визначає корегуючу здатність. Сучасні методи завадостійкого кодування направленні на виявлення та виправлення тільки однократних помилок та повністю втрачають свій сенс при виникнення багатократних пакетних помилок. В таких умовах використання сучасних методів завадостійкого кодування та декодування в реальних каналах зв’язку виявляється неефективним, оскільки не забезпечується відповідний рівень ймовірності появи некоригованих помилок.
Структурно-аналітична модель
реалізації методу ідентифікації повної кодової конструкції
В попередніх
роботах [1-3], представлено новий розроблений метод відновлення кодових
конструкцій на базі достатньої кількості інформації з урахуванням інформативних
складових. Встановлені пороги прийняття рішення з метою вірогідного відновлення
повної кодової конструкції. Розроблено
новий метод визначення інформативних складових сигналу при введенні заданої
функції невизначеності з умов побудови послідовного правила прийняття рішення.
На основі проведених досліджень, визначено можливість зупинки процесу
декодування у разі відповідності отриманих результатів встановленим порогам
прийняття рішення на основі використання найбільш інформативних складових
спектру кодової конструкції. В результаті нововведень, необхідно побудувати
модель вирішальних процедур для визначення можливості використання багато
альтернативних правил прийняття рішення у задачах канального декодування.
Показано, що сформований вище метод,
надає можливість використання критеріїв й процедур ідентифікації інформаційних
сигналів на базі мінімально достатньої кількості інформації ![]() з визначеними
порогами прийняття рішень
з визначеними
порогами прийняття рішень ![]() . Однак, данні правила розроблені для ідентифікації сигналів
сформованих від різних класів інформаційних об’єктів з різко відмінними
інформаційними параметрами та мають конкретні недоліки.
. Однак, данні правила розроблені для ідентифікації сигналів
сформованих від різних класів інформаційних об’єктів з різко відмінними
інформаційними параметрами та мають конкретні недоліки.
Доведено, що вирішення даної задачі
можливе на основі досягнення мінімально достатньої міри кількості інформації,
що сформована з урахуванням найбільш інформативних параметрів інформаційних
сигналів. Показано, що інформативними параметрами сигналу є спектральне
представлення послідовності кодових слів, як найбільш інформативне для
прийняття рішення. Показано, що
спектральне подання сигналу буде використовуватися при розрахунках
умовних ймовірностей і виборі найбільш ймовірної гіпотези, тому можна говорити
про кількість інформації, яка відповідає кожній гіпотезі та позначена як: ![]() у відповідності до
у відповідності до ![]() , де
, де ![]() . Для кожної гіпотези
. Для кожної гіпотези ![]() обчислюється
кількість інформації
обчислюється
кількість інформації ![]() , що міститься в спектрі. Позначимо
, що міститься в спектрі. Позначимо ![]() (
(![]() ,
, ![]() ), як спектральне представлення прийнятого інформаційного
сигналу при наявності в каналі зв’язку білого гауссового шуму.
), як спектральне представлення прийнятого інформаційного
сигналу при наявності в каналі зв’язку білого гауссового шуму.
Визначено, що
міра кількості інформації ![]() , яка розраховується для кожної гіпотези
, яка розраховується для кожної гіпотези ![]() , має наступний вид:
, має наступний вид:
![]() , (1)
, (1)
де ![]() – апостеріорна
ймовірність появи інформаційного сигналу;
– апостеріорна
ймовірність появи інформаційного сигналу; ![]() – узагальнена міра
невизначеності для
– узагальнена міра
невизначеності для ![]() -го інформаційного сигналу, розрахована по апостеріорним
ймовірностям.
-го інформаційного сигналу, розрахована по апостеріорним
ймовірностям.
Визначено, що
враховуючи те, що за інформативний параметр інформаційного сигналу
використовується спектральне представлення, формула (1) прийме вид:
![]() , (2)
, (2)
де ![]() – апостеріорна
ймовірність появи інформаційного сигналу;
– апостеріорна
ймовірність появи інформаційного сигналу; ![]() – узагальнена міра
невизначеності розрахована по апостеріорній ймовірності:
– узагальнена міра
невизначеності розрахована по апостеріорній ймовірності:
![]() .
.
Доведено, що
використання спектрального представлення кодового слова, в якості функції
невизначеності ![]() , буде найкращим для побудови математичної процедури
прийняття рішення з умов збільшення узагальненої міри кількості інформації та
забезпечення ідентифікації кодових конструкцій.
, буде найкращим для побудови математичної процедури
прийняття рішення з умов збільшення узагальненої міри кількості інформації та
забезпечення ідентифікації кодових конструкцій.
Подальше,
введено функцію невизначеності, покликану зменшити інформаційну невизначеність
та забезпечити достатню міру кількості інформації. Дана функція надалі буде
використовуватися при побудові математичної процедури прийняття рішення, а саме
розрахунку міри невизначеності, міри кількості інформації та апостеріорної
ймовірності правильної ідентифікації кодової конструкції.
На базі введення цих аналітичних положень, виникає завдання побудови моделі процедури
статистичних правил прийняття рішення у задачах декодування повної кодової
конструкції з умов забезпечення цілісності та достовірності інформаційних
потоків ІКСМ (Рис.1). Побудуємо модель процедури статистичних правил прийняття
рішення на базі мінімально-достатньої кількості інформації при виконанні послідовної
процедури зупинки процесу ідентифікації у разі відповідності отриманих
результатів встановленим критеріям та вимогам [2-4]. Одним із основних завдань
при розробці ефективного методу є оцінка точності безпомилкової ідентифікації з
урахуванням забезпечення максимальної ймовірності правильного прийняття рішення
та мінімізації ймовірності появи не коригованих помилок ![]() .
.
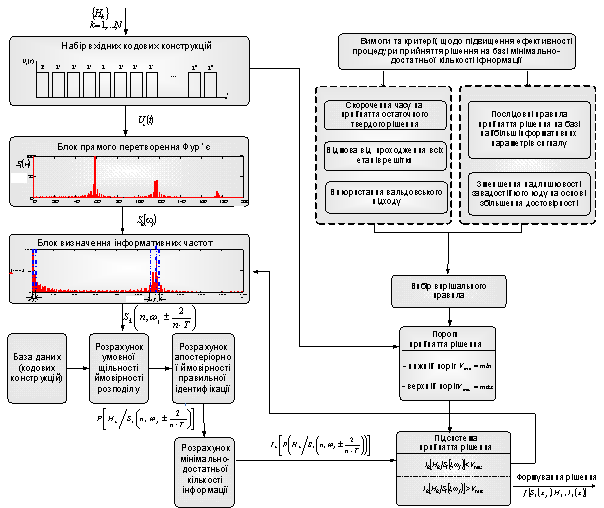 Рис.1.
Структурно-аналітична модель реалізації методу ідентифікації повної кодової
конструкції з слабо відмінними параметрами
Рис.1.
Структурно-аналітична модель реалізації методу ідентифікації повної кодової
конструкції з слабо відмінними параметрами
Оцінка ефективності методів
відновлення та ідентифікації з умов забезпечення достовірності та цілісності
кодових конструкцій
Розглянемо ефективність розробленої послідовної процедури прийняття
рішення на базі мінімально-достатньої кількості інформації (рис.2). Дана
процедура розглядається в випадку багато альтернативної ситуації та при
присутності слабо відмінних гіпотез, тобто такі, що розрізняються на 1-4
Хемінгові різниці та мають ![]() бітову архітектуру.
бітову архітектуру.
Для оцінки
якості розробленого методу, побудуємо графічні залежності ймовірності появи не
коригованих помилок ![]() кратності
кратності ![]() від співвідношення
сигнал/шум
від співвідношення
сигнал/шум ![]() .
.
Ймовірність появи не коригованих помилок кратності ![]() для розробленого
методу, розрахуємо згідно виразу:
для розробленого
методу, розрахуємо згідно виразу:
![]() (3)
(3)
![]() - ймовірність появи
бітової помилки в канальному символі,
- ймовірність появи
бітової помилки в канальному символі,
![]() ,
,
![]() - Гаусів інтеграл,
- Гаусів інтеграл, ![]() - швидкість коду
(відношення кількості інформаційних
- швидкість коду
(відношення кількості інформаційних ![]() до канальних
до канальних ![]() символів),
символів), ![]() - співвідношення
сигнал/шум;
- співвідношення
сигнал/шум; ![]() - кількість розміщень
помилок кратності
- кількість розміщень
помилок кратності ![]() у кодовій конструкції
довжиною
у кодовій конструкції
довжиною ![]() :
: ![]() .
.
Проведемо порівняльний аналіз розробленої процедури відновлення та ідентифікації кодових конструкцій на базі мінімально достатньої кількості інформації з існуючими методами завадостійкого кодування/декодування інформаційних потоків.
Визначимо оцінку точності процедур відновлення та
ідентифікації на основі достатньої кількості інформації з умов забезпечення
достовірності і цілісності кодових конструкцій. Для оцінки якості розроблених
методів, побудуємо графічні залежності
ймовірності появи не коригованих помилок кратності ![]() від співвідношення
сигнал/шум
від співвідношення
сигнал/шум ![]() (Рис.2,3).
(Рис.2,3).
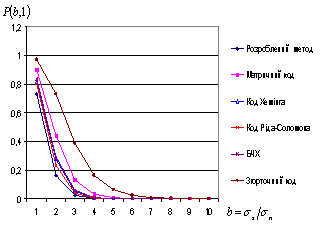
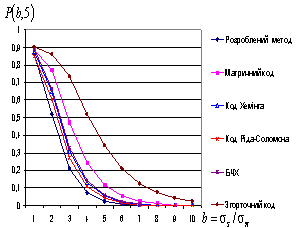
По-перше, кількісні значення
ймовірностей не коригованих помилок для розробленого методу відновлення кодових
слів, значно менші в порівнянні з відомими методами; (при 1 бітній помилці
ймовірність неправильного декодування знизилася від 1,7 до 17 разів; при 2
бітній помилці – від 1,9 до 19 разів; при 3 бітній помилці – від 2 до 13
разів; при 4 бітній помилці – від 1,6
до 21 разів; при 5 бітній помилці – від
1,64 до 13 разів в залежності від використаного методу завадостійкого
кодування);
по-друге: використання розроблених
методів не потребує введення надлишкової коригувальної інформації, що звільняє
від 15 до 18 відсотків розміру кодового слова на передачу додаткової корисної інформації, що дозволить збільшити
обсяги переданої інформації за встановлену одиницю часу.
|
Рис.2 Ймовірність появи не коригованих помилок,
порівняння сучасних методів (при
1 бітній помилці) |
коригованих помилок, порівняння
сучасних методів (при
5 бітній помилці) |
З отриманих аналітичних та графічних залежностей ймовірності не
коригованих помилок, можна зробити наступні висновки:
Таким чином показано, що
відбувається зменшення ймовірності помилкової ідентифікації та подальше повне
усунення спотворень у інформаційному повідомленні з умов появи багатократних помилок, що підвищує
ефективність та надійність функціонування ІКСМ з умов збільшення вірогідності
інформаційного потоку даних: ![]() , без втрат якості.
, без втрат якості.
Проведемо оцінку складності реалізації розробленої моделі
вирішальних процедур сформованих на базі мінімально-достатньої кількості
інформації в порівнянні з сучасним методом завадостійкого декодування –
алгоритмом Вітербі. Для оцінки складності визначимо кількість математичних
операцій процедури за час декодування 32
та 64 бітної кодової конструкції.
Показано, що метод декодування Вітербі є ефективним, але
його складність росте експоненційно з ростом кодового обмеження ![]() , і тому на практиці кодери з
, і тому на практиці кодери з ![]() не використовуються.
Тобто експоненційно збільшується кількість вузлів решітки та можливих станів
діаграми процедури декодування. Порівняльний аналіз складності реалізації
процедури проводився для алгоритму декодування Вітербі при
не використовуються.
Тобто експоненційно збільшується кількість вузлів решітки та можливих станів
діаграми процедури декодування. Порівняльний аналіз складності реалізації
процедури проводився для алгоритму декодування Вітербі при ![]() та заданій
ймовірності виникнення помилки. Визначено
кількість операцій для нововведеного методу реалізації процедури прийняття
рішення при декодуванні та ідентифікації 32-64 бітної кодової конструкції.. Доведено,
що процедура прийняття рішення на базі-мінімально достатньої кількості інформації
при використанні інформативних складових більш ефективна, як в аспекті
забезпечення достовірності так і в аспекті часових затрат. Визначено значення
загального часу на відновлення та обробку даних на базі розрахунку кількості математичних операцій.
Показано можливість скорочення
загального часу на прийняття остаточного твердого рішення, щодо відновлення
повної кодової в 7 раз у разі обробки повного вибіркового простору.
та заданій
ймовірності виникнення помилки. Визначено
кількість операцій для нововведеного методу реалізації процедури прийняття
рішення при декодуванні та ідентифікації 32-64 бітної кодової конструкції.. Доведено,
що процедура прийняття рішення на базі-мінімально достатньої кількості інформації
при використанні інформативних складових більш ефективна, як в аспекті
забезпечення достовірності так і в аспекті часових затрат. Визначено значення
загального часу на відновлення та обробку даних на базі розрахунку кількості математичних операцій.
Показано можливість скорочення
загального часу на прийняття остаточного твердого рішення, щодо відновлення
повної кодової в 7 раз у разі обробки повного вибіркового простору.
На базі сформованих оцінок та проведеного дослідження, зроблено наступні висновки:
·
забезпечується зменшення кількості
математичних операцій (використання вибіркового простору трьох частотних вікон)
при ідентифікації і відновленні 32-бітної кодової конструкції, що спрощує
складність реалізації розробленого методу в ![]() разів, в порівнянні з
базовим методом Вітерці;
разів, в порівнянні з
базовим методом Вітерці;
·
забезпечується зменшення кількості
математичних операцій (використання вибіркового простору восьми частотних
вікон) при ідентифікації і відновленні 64-бітної кодової конструкції, що
спрощує складність реалізації розробленого методу в ![]() разів, в порівнянні з
базовим методом Вітербі .
разів, в порівнянні з
базовим методом Вітербі .
Висновки
У даній роботі проведено
порівняльний аналіз розробленого методу ідентифікації на основі вирішення
багато альтернативної задачі з існуючими методами завадостійкого кодування/декодування
з умови забезпечення цілісності та достовірності інформаційного потоку ІКСМ. На
основі проведеного аналізу можна констатувати, що використання нововведеної
процедури підвищує точність ідентифікації з умов зменшення ймовірності
помилкової ідентифікації. Нововведена
модель дає змогу проводити ідентифікацію при незначному рівні сигналу на фоні
шуму. Тобто відбувається підвищення достовірності прийняття рішення,
зменшення ймовірності помилкової ідентифікації та повне усунення спотворень у
інформаційному повідомленні. Також, відбувається підвищення швидкості передачі
даних, збільшення вірогідного потоку даних, економія смуги частот ІКСМ. Визначено
кількісні оцінки точності процедур відновлення та ідентифікації на основі достатньої
кількості інформації з умов забезпечення достовірності і цілісності кодових
конструкцій. Для оцінки якості розроблених методів, побудовано графічні залежності ймовірності не коригованих помилок
кратності ![]() від співвідношення
сигнал/шум
від співвідношення
сигнал/шум ![]() .
.
Література
1.
Юдін О.К. Кодування в інформаційно-комунікаційних мережах – Монографія.К.:
Книжкове видавництво НАУ, 2007. – 302 с.
2.
Юдін О.К. Математичні аспекти використання багато альтернативних правил в
задачах канального кодування інформаційних потоків /Юдін О.К., Чунарьова А.В.
// Збірник наукових праць Інституту проблем моделювання в енергетиці ім. Г.Є.
Пухова. Вип.47-К.:ІПМЕ НАН України,
2008. – 25-31 с.
3.
Юдін О.К. Спектральні методи визначення інформативних складових в
процедурах усунення інформаційної невизначеності/ Юдін О.К., Чунарьова А.В.//Всеукраинский межведомственный научно-технический
сборник “Радиотехника“, вып. №159. Х.: ХНУРЭ, 2009. – С. 228-233.
4.
Скляр Б. Цифровая связь. Теоретические основы и практическое
применение / Пер. с англ. – М.: Изд. дом Вильямс, 2004. – 1104 с.