Современные
информационные технологии/Вычислительная техника и программирование
Мясищев А.А.
Хмельницкий национальный
университет, Украина
Параллельное умножение квадратных
матриц с использованием технологии MPI
Целью работы является исследование зависимости
производительности последовательной и параллельной вычислительной системы на
задаче умножения квадратных матриц от качества составленных
программ. Эта задача часто встречается при решении многих прикладных задач,
связанных с решением систем уравнений в частных производных (задачи расчета на
прочность, переноса тепла и т.д.) Для удобства отслеживания производительности
компьютера на конкретном приложении в работе фиксируется производительность
систем в Мегафлопсах (1 Mflops - миллион операций с плавающей точкой за одну
секунду). Для оценки этой величины измеряется время выполнения фиксированного
числа реальных операций, которые выполняются системой. Для данной задачи эта
величина равна:
Число операций = (2* N - 1)*N*N,
где N - размерность матриц.
Разделив число операций на время,
умноженное на 1000000, можно получить производительность системы в Мегафлопсах.
( Мегафлопс=(Число операций)/(время*1000000)).
В качестве вычислительных систем рассмотрены
системы, построенные на базе двуядерных процессорах Pentium E2160
и Athlon 64x2 4000+.
Рассмотрим
последовательность действий выполняемых при перемножении квадратной матрицы. В
качестве примера для последующего обобщения зависимостей для вычисления членов
результирующей матрицы рассмотрим произвольные матрицы размерностью
N=4.
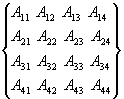 *
* 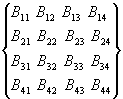 =
=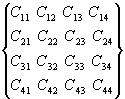
Рассмотрим построчное
вычисление членов матрицы C . Это важно для
реализации параллельного алгоритма вычисления произведения.
Определение членов матрицы C
для первой строки определяется следующим образом:
![]()
![]()
![]()
![]()
Или в общем виде:
![]() ,
,
Здесь J-номер столбца , K-индекс
для суммирования.
Аналогично для второй строки:
![]()
![]()
![]()
![]()
Или в общем виде:
![]()
Окончательно можно записать для любого элемента матрицы C:
![]() ,
здесь I – номер строки.
,
здесь I – номер строки.
Важно отметить, что при построчном
алгоритме расчета произведения, вычисления производятся для каждой строки
матрицы C, т.е. сначала для первой, затем для второй и т.д., затем
для N-й.
Фрагмент программы на Фортране для
построчного вычисления произведения может выглядеть так:
do 2 i=1,n
do 2 j=1,n
c(i,j)=0.
do 3 k=1,n
3 c(i,j)=c(i,j)+a(i,k)*b(k,j)
2
continue
Известно, что компилятор
Фортрана располагает двумерные массивы в памяти по столбцам. Поэтому выборка
членов из массива A выполняется из далеко расположенных друг от
друга ячеек памяти. Так как размер быстродействующей кэш памяти ограничен,
целесообразно вынести операцию выборки из самых внутренних циклов наружу.
Поэтому представленное ниже преобразование фрагмента программы путем введения
линейного массива aa(m) должно дать выигрыш в
производительности для матриц большого размера.
do 2 i=1,n
do m=1,n
aa(m)=a(i,m)
end do
do 2 j=1,n
c(i,j)=0.
do 3 k=1,n
3 c(i,j)=c(i,j)+aa(k)*b(k,j)
2
continue
Рассмотрим вычисление
членов матрицы C по столбцам.
Определение членов матрицы C для
первого столбца определяется следующим образом:
![]()
![]()
![]()
![]()
Или в общем виде:
![]() ,
,
Здесь I-номер строки , K-индекс
для суммирования.
Аналогично для второго столбца:
![]()
![]()
![]()
![]()
Или в общем виде:
![]()
Окончательно можно записать для любого
элемента матрицы C:
![]() ,
здесь J – номер столбца.
,
здесь J – номер столбца.
Фрагмент программы на Фортране вычисления
произведения по столбцам может выглядеть так:
do 2 j=1,n
do 2 i=1,n
c(i,j)=0.
do 3 k=1,n
3 c(i,j)=c(i,j)+a(i,k)*b(k,j)
2
continue
Необходимо отметить, что
при расчете произведения по столбцам, вычисления производятся для
каждого столбца матрицы C, т.е. сначала для
первого, затем для второго и т.д. затем для N-го. Этот способ расчета
удобнее применять для параллельного алгоритма методом MPI, так как пересылается
меньшее количество данных между процессами (см. программу, представленную
ниже).
Ниже представлены три
разных программы, написанных для однопроцессорного узла. В каждой программе
рассчитывается сумма членов главной диагонали матрицы.
1. Программа выполняет перемножение
матриц порядка n=1000. Определение элементов матрицы
производится последовательно построчно.
program lab3_1
include 'mpif.h'
parameter (n=1000)
integer ierr,rank,size,i,j,k,ii
real :: a(n,n), b(n,n), c(n,n)
real :: r1,mf,op
double precision time1, time3, time2
integer status(MPI_STATUS_SIZE)
call MPI_INIT(ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, size,
ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank,
ierr)
op=(2.0*n-1)*n*n
c
initial data
do 10 i=1,n
do 10 j=1,n
a(i,j)=1.0*i*j
b(i,j)=1.0/a(i,j)
c(i,j)=0.
10 continue
c
First part of the matrix
if(rank.eq.0) then
time1 = MPI_Wtime()
do 2 i=1,n
do 2 j=1,n
c(i,j)=0.
do 3 k=1,n
3 c(i,j)=c(i,j)+a(i,k)*b(k,j)
2 continue
time2 = MPI_Wtime()
time3 = time2-time1
do 7 i=1,4
7 print 8,c(i,1),c(i,2),c(i,3),c(i,4)
8 format(1x,4f9.3)
r1=0.
do ii=1,n
r1=r1+c(ii,ii)
end do
mf=op/(time3*1000000.0)
print *,' diagonal=',r1
print *,' time = ',time3,' mf=',mf
end if
call MPI_FINALIZE(ierr)
end
2. Программа выполняет перемножение
матриц порядка n=2000. Определение элементов матрицы
производится последовательно по столбцам. Эта программа проще поддается
распараллеливанию.
program lab3_1a
include 'mpif.h'
parameter (n=2000)
integer ierr,rank,size,i,j,k,ii
real :: a(n,n), b(n,n), c(n,n)
real :: r1,mf,op
double precision time1, time3, time2
integer status(MPI_STATUS_SIZE)
call MPI_INIT(ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, size,
ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank,
ierr)
op=(2.0*n-1)*n*n
c
initial data
do 10 i=1,n
do 10 j=1,n
a(i,j)=1.0*i*j
b(i,j)=1.0/a(i,j)
c(i,j)=0.
10 continue
c
First part of the matrix
if(rank.eq.0) then
time1 = MPI_Wtime()
do 2 j=1,n
do 2 i=1,n
c(i,j)=0.
do 3 k=1,n
3 c(i,j)=c(i,j)+a(i,k)*b(k,j)
2 continue
time2 = MPI_Wtime()
time3 = time2-time1
do 7 i=1,4
7 print 8,c(i,1),c(i,2),c(i,3),c(i,4)
8 format(1x,4f9.3)
r1=0.
do ii=1,n
r1=r1+c(ii,ii)
end do
mf=op/(time3*1000000.0)
print *,' diagonal=',r1
print *,' time = ',time3,' mf=',mf
end if
call MPI_FINALIZE(ierr)
end
3. Программа выполняет перемножение
матриц порядка n=2000. Определение элементов матрицы
производится последовательно по строкам. Однако для увеличения
производительности расчета матрица a(i,j),
с помощью подстановки
do m=1,n
aa(m)=a(i,m)
end do
преобразуется для строки i в одномерный
массив aa(m). Благодаря этому повышается производительность в несколько раз для
процессоров Pentium и AMD из-за более
эффективного использования быстродействующей кэш памяти. Как отмечалось выше, это
объясняется тем, что компилятор Фортрана располагает двумерные массивы в памяти
по столбцам. Т.е. для больших массивов кэш память может быть полностью
заполнена только одной строкой, а для доступа к следующему столбцу процессор
должен обратиться к основной более медленной оперативной памяти.
program lab3_0
include 'mpif.h'
parameter (n=2000)
integer ierr,rank,size,i,j,k,ii,m
real :: a(n,n), b(n,n), c(n,n),aa(n)
real :: r1,mf,op
double precision time1, time3, time2
integer status(MPI_STATUS_SIZE)
call MPI_INIT(ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, size,
ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank,
ierr)
op=(2.0*n-1)*n*n
c
initial data
do 10 i=1,n
do 10 j=1,n
a(i,j)=1.0*i*j
b(i,j)=1.0/a(i,j)
c(i,j)=0.
10 continue
c
First part of the matrix
if(rank.eq.0) then
time1 = MPI_Wtime()
do 2 i=1,n
do m=1,n
aa(m)=a(i,m)
end do
do 2 j=1,n
c(i,j)=0.
do 3 k=1,n
3 c(i,j)=c(i,j)+aa(k)*b(k,j)
2 continue
time2 = MPI_Wtime()
time3 = time2-time1
do 7 i=1,4
7 print 8,c(i,1),c(i,2),c(i,3),c(i,4)
8 format(1x,4f9.3)
r1=0.
do ii=1,n
r1=r1+c(ii,ii)
end do
mf=op/(time3*1000000.0)
print *,' diagonal=',r1
print *,' time = ',time3,' mf=',mf
end if
call MPI_FINALIZE(ierr)
end
Далее представлены три
разных программы, написанных для двухпроцессорного (двуядерного) узла.
1. Программа выполняет перемножение
матриц порядка n=2000. Определение элементов матрицы
производится построчно. Для нулевого процесса идет расчет матрицы с 1-й
строки по n/2 (для двухпроцессорного случая). Для первого процесса
производится расчет с n/2+1 строки до n - й. Пересылка данных
выполняется с помощью дополнительного массива cc(n,n)
от 1-го процесса 0-му. После пересылки к нулевым членам массива c(i,j)
добавляются рассчитанные в 1-м процессоре члены массива cc(i,j).
program lab3_3b
include 'mpif.h'
parameter (n=2000)
integer ierr,rank,size,i,j,k,ii,m
real :: a(n,n),b(n,n),c(n,n),cc(n,n)
real :: r1,mf,op
double precision time1, time3, time2
integer status(MPI_STATUS_SIZE)
call MPI_INIT(ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, size,
ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank,
ierr)
op=(2.0*n-1)*n*n
c
initial data
do 10 i=1,n
do 10 j=1,n
a(i,j)=1.0*i*j
b(i,j)=1.0/a(i,j)
c(i,j)=0.
10 continue
c
First part of the matrix
if(rank.eq.0) then
time1 = MPI_Wtime()
do 2 i=1,n/2
do 2 j=1,n
c(i,j)=0.
do 3 k=1,n
3 c(i,j)=c(i,j)+a(i,k)*b(k,j)
2 continue
call
MPI_RECV(cc(1,1),n*n,MPI_REAL,1,5,MPI_COMM_WORLD,
&status,ierr)
do 11 i=n/2+1,n
do 11 j=1,n
11 c(i,j)=cc(i,j)
do 7 i=1,4
7 print 8,c(i,1),c(i,2),c(i,3),c(i,4)
8 format(1x,4f9.3)
time2 = MPI_Wtime()
time3=time2-time1
print *,' process=',rank,' time=',time3
end if
c
Second part of the matrix
if(rank.eq.1) then
do 4 i=n/2+1,n
do 4 j=1,n
c(i,j)=0.
do 5 k=1,n
5 c(i,j)=c(i,j)+a(i,k)*b(k,j)
4 continue
call
MPI_SEND(c(1,1),n*n,MPI_REAL,0,5,MPI_COMM_WORLD,
&ierr)
end if
if(rank.eq.0) then
r1=0.
do ii=1,n
r1=r1+c(ii,ii)
end do
mf=op/(time3*1000000.0)
print *,' diagonal=',r1
print *,' time = ',time3,' mf=',mf
end if
call MPI_FINALIZE(ierr)
end
2. Программа выполняет перемножение
матриц порядка n=2000. Определение элементов матрицы
производится по столбцам. Для нулевого процесса идет расчет матрицы с
1-го столбца по n/2 (для двухпроцессорного случая). Для первого
процесса производится расчет с n/2+1 столбца до n -го. Пересылка данных
выполняется с помощью массива c(n,n)
от 1-го процесса к 0-му, причем половинной длины. Данная программа наиболее
экономичная по использованию памяти и размера пересылаемых данных. Однако как
будет показано ниже, она поигрывает в производительности.
program lab3_3
include 'mpif.h'
parameter (n=2000)
integer ierr,rank,size,i,j,k,ii
real :: a(n,n), b(n,n), c(n,n)
real :: r1,mf,op
double precision time1, time3, time2
integer status(MPI_STATUS_SIZE)
call MPI_INIT(ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, size,
ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank,
ierr)
op=(2.0*n-1)*n*n
c
initial data
do 10 i=1,n
do 10 j=1,n
a(i,j)=1.0*i*j
b(i,j)=1.0/a(i,j)
c(i,j)=0.
10 continue
c
First part of the matrix
if(rank.eq.0) then
time1 = MPI_Wtime()
do 2 j=1,n/2
do 2 i=1,n
c(i,j)=0.
do 3 k=1,n
3 c(i,j)=c(i,j)+a(i,k)*b(k,j)
2 continue
call
MPI_RECV(c(1,n/2+1),n*n/2,MPI_REAL,1,5,MPI_COMM_WORLD,
&status,ierr)
do 7 i=1,4
7 print 8,c(i,1),c(i,2),c(i,3),c(i,4)
8 format(1x,4f9.3)
time2 = MPI_Wtime()
time3=time2-time1
print *,' process=',rank,' time=',time3
end if
c
Second part of the matrix
if(rank.eq.1) then
do 4 j=n/2+1,n
do 4 i=1,n
c(i,j)=0.
do 5 k=1,n
5 c(i,j)=c(i,j)+a(i,k)*b(k,j)
4 continue
call
MPI_SEND(c(1,n/2+1),n*n/2,MPI_REAL,0,5,MPI_COMM_WORLD,
&ierr)
end if
if(rank.eq.0) then
r1=0.
do ii=1,n
r1=r1+c(ii,ii)
end do
mf=op/(time3*1000000.0)
print *,' diagonal=',r1
print *,' time = ',time3,' mf=',mf
end if
call MPI_FINALIZE(ierr)
end
3. Программа выполняет перемножение
матриц порядка n=2000. Определение элементов матрицы
производится построчно, как и в первой программе. Однако для повышения
производительности в 0-й и 1-й процессы вводится подстановка, как и в
однопроцессорной программе, с целью преобразования двумерного массива в
одномерный. Для нулевого процесса идет расчет матрицы с 1-й строки по n/2
(для двухпроцессорного случая). Для первого процесса производится расчет с n/2+1
строки до n - й. Пересылка данных
выполняется с помощью дополнительного массива cc(n,n)
от 1-го процесса 0-му. После пересылки к нулевым членам массива c(i,j)
добавляются рассчитанные в 1-м процессоре члены массива cc(i,j).
program lab3_3a
include 'mpif.h'
parameter (n=2000)
integer ierr,rank,size,i,j,k,ii,m
real ::
a(n,n),b(n,n),c(n,n),cc(n,n),aa(n)
real :: r1,mf,op
double precision time1, time3, time2
integer status(MPI_STATUS_SIZE)
call MPI_INIT(ierr)
call MPI_COMM_SIZE(MPI_COMM_WORLD, size,
ierr)
call MPI_COMM_RANK(MPI_COMM_WORLD, rank,
ierr)
op=(2.0*n-1)*n*n
c
initial data
do 10 i=1,n
do 10 j=1,n
a(i,j)=1.0*i*j
b(i,j)=1.0/a(i,j)
c(i,j)=0.
cc(i,j)=0
10 continue
c
First part of the matrix
if(rank.eq.0) then
time1 = MPI_Wtime()
do 2 i=1,n/2
do
m=1,n
aa(m)=a(i,m)
end do
do 2 j=1,n
c(i,j)=0.
do 3 k=1,n
3 c(i,j)=c(i,j)+aa(k)*b(k,j)
2 continue
call
MPI_RECV(cc(1,1),n*n,MPI_REAL,1,5,MPI_COMM_WORLD,
&status,ierr)
do 11 i=n/2+1,n
do 11 j=1,n
11 c(i,j)=cc(i,j)
end if
c
Second part of the matrix
if(rank.eq.1) then
do 4 i=n/2+1,n
do
m=1,n
aa(m)=a(i,m)
end do
do 4 j=1,n
c(i,j)=0.
do 5 k=1,n
5 c(i,j)=c(i,j)+aa(k)*b(k,j)
4 continue
call
MPI_SEND(c(1,1),n*n,MPI_REAL,0,5,MPI_COMM_WORLD,
&ierr)
end if
if(rank.eq.0) then
r1=0.
do ii=1,n
r1=r1+c(ii,ii)
end do
do 7 i=1,4
7 print 8,c(i,1),c(i,2),c(i,3),c(i,4)
8 format(1x,4f9.3)
time2 = MPI_Wtime()
time3=time2-time1
mf=op/(time3*1000000.0)
print *,' diagonal=',r1
print *,' time = ',time3,' mf=',mf
end if
call MPI_FINALIZE(ierr)
end
В таблице 1 показаны результаты по
затратам времени в секундах (числитель) и производительности в Мегафлопсах
(знаменатель) для расчета произведений квадратных матриц порядков 400x400, 500х500, 1000х1000, 2000х2000, 3000x3000 представленными выше программами для компьютера
на базе процессора Athlon 64x2 4000+. В качестве операционной системы использовался
ASP Linux 11.2 с
скомпилированным для него пакетом MPICH версии 1.2.7. Для компиляции
использовался Фортран 77, поставляемый вместе с дистрибутивом Linux 11.2.
Таблица 1
|
Метод расчета |
Расчет на одном ядре |
Расчет на двух ядрах |
||||||||
|
400 |
500 |
1000 |
2000 |
3000 |
400 |
500 |
1000 |
2000 |
3000 |
|
|
По строкам |
0.14 896 |
0.40 619 |
12.7 158 |
143.6 112 |
508.1 106 |
0.088 1455 |
0.221 1130 |
6.40 312 |
71.9 222 |
259.8 207.8 |
|
По строкам с преобр.
двухмерного массива |
0.15 881 |
0.29 868 |
2.29 872 |
17.7 901 |
59.1 914 |
0.08 1568 |
0.18 1374 |
1.39 1436 |
10.7 1498 |
35.5 1520 |
|
По столбцам |
0.17 749 |
0.51 484 |
12.9 155 |
143.5 112 |
511.4 106 |
0.103 1240 |
0.32 780 |
6.61 302 |
72.7 220 |
265.6 203 |
В таблице 2 представлены
аналогичные расчеты, но для системы на базе процессора Pentium E2160.
Таблица 2
|
Метод расчета |
Расчет на одном ядре |
Расчет на двух ядрах |
||||||||
|
400 |
500 |
1000 |
2000 |
3000 |
400 |
500 |
1000 |
2000 |
3000 |
|
|
По строкам |
0.17 754 |
0.43 586 |
7.70 260 |
68.1 235 |
305.0 177 |
0.095 1347 |
0.28 899 |
4.00 499 |
41.8 383 |
252.1 214 |
|
По строкам с преобр.
двухмерного массива |
0.17 758 |
0.33 751 |
2.30 869 |
15.3 1047 |
49.5 1089 |
0.093 1373 |
0.183 1366 |
1.42 1405 |
8.8 1822 |
28.4 1901 |
|
По столбцам |
0.18 695 |
0.50 497 |
8.00 250 |
69.8 229 |
293.5 184 |
0.11 1130 |
0.31 796 |
4.40 454 |
45.6 351 |
250 216 |
Расчеты, выполненные на
вычислительном кластере, состоящем из двух компьютеров Pentium IV
3.0GHz/1024/800MHz и соединенных с помощью сети Fast Ethernet, представлены в
таблице 3. Программным обеспечением является учебный кластер BCCD 2.2.1,
построенный на базе Linux. В качестве компилятора, как и в предыдущих случаях,
использовался Фортран 77.
Таблица 3
|
Метод расчета |
Расчет на одном ядре |
Расчет на двух ядрах |
||||||||
|
400 |
500 |
1000 |
2000 |
3000 |
400 |
500 |
1000 |
2000 |
3000 |
|
|
По строкам |
0.27 472 |
0.62 406 |
8.85 226 |
83.8 191 |
273.7 197 |
0.20 645 |
0.41 614 |
4.84 413 |
44.7 358 |
149.1 362 |
|
По строкам с преобр.
двухмерного массива |
0.14 900 |
0.29 868 |
2.31 865 |
18.5 866 |
61.8 874 |
0.14 930 |
0.26 968 |
1.54 1300 |
11.7 1369 |
39.1 1381 |
|
По столбцам |
0.27 470 |
0.71 350 |
9.43 212 |
90.3 177 |
298.4 181 |
0.17 768 |
0.426 586 |
5.37 372 |
50.1 319 |
160.4 336 |
Компиляция программ на языке Фортран
выполнялась скриптом mpi77:
/usr/local/mpi/ch_shmem/bin/mpif77 –O2
lab3_3.f -o lab3_3
Запуск программ – скриптом mpirun:
/usr/local/mpi/ch_shmem/bin/mpirun
-np 2 -machinefile machines lab3_3
Здесь опция -O2 сообщает компилятору
о необходимости оптимизации кода.
В таблице 4 представлены
данные, позволяющие оценить ускорение вычисления произведения матриц двуядерными
процессорами для программ расчета по
строкам(1) и по строкам с преобразованием
двумерного массива(2).
Таблица 4
|
Размерность матрицы NxN |
Athlon 64x2
4000+ , ускорение |
Pentium E2160,
ускорение |
Кластер, ускорение |
|||
|
1 |
2 |
1 |
2 |
1 |
2 |
|
|
400x400 |
1.624 |
1.780 |
1.786 |
1.811 |
1.367 |
1.033 |
|
500x500 |
1.826 |
1.583 |
1.534 |
1.819 |
1.512 |
1.115 |
|
1000x1000 |
1.975 |
1.647 |
1.919 |
1.617 |
1.827 |
1.503 |
|
2000x2000 |
1.982 |
1.663 |
1.630 |
1.740 |
1.874 |
1.581 |
|
3000x3000 |
1.962 |
1.663 |
1.209 |
1.746 |
1.838 |
1.580 |
Из последней таблицы видно, что
максимальное ускорение достигается для процессора Pentium E2160
для самой быстродействующей программы (2). Но для этой более оптимизированной
программы к кэш памяти не удается получить ускорение, близко приближающееся к двукратному.
Однако для программы 1 первый процессор демонстрирует почти двукратное
ускорение для размерностей матрицы больше 1000. Процессор Pentium E2160
имеет максимальное ускорение для
матрицы 1000, а затем ускорение резко уменьшается, что связано с малым размером
кэш памяти его по сравнению с первым процессором. Для двухузлового
кластера максимальное ускорение для 1-й
программы не превышает 1.87 раза. Это можно объяснить значительным временем
передачи данных по сети Fast Ethernet. Как
отмечалось, для второй задачи(2) лидером по ускорению является процессор Pentium
E2160. Причем для всех систем кроме кластера для второй
задачи отмечается равномерное ускорение для всех размерностей матрицы. Однако
оно имеет меньшее значение, чем для неоптимизированной к кэш памяти программы
(2).
Выводы
1. Не удается достичь двукратного
ускорения счета матричного произведения для оптимизированных к кэш памяти
программ.
2. При составлении программ, которые
интенсивно работают с большими массивами, необходимо их вычислительную часть
максимально размещать в кэш памяти. Это приводит к резкому (6-8 раз) увеличению
производительности.
3. При распараллеливании оптимизированных
к кэш памяти программ предпочтение следует отдавать системам на базе
многоядерных процессоров фирмы Intel, как наиболее
приспособленных для данных задач.
4. При выборе параллельных вычислительных
систем необходимо предпочтение отдавать SMP системам, а не
вычислительным кластерам, которые тратят много времени на пересылку данных.
5. Если процессор имеет большую кэш
память, нет необходимости тратить время для составления оптимизированных к кэш
памяти программ.
Литература.
1. Воеводин В.В., Воеводин Вл.В.
Параллельные вычисления. – СПб: БХВ – Петербург, 2004.-608 с.: ил.
2. Гергель В.П. Теория и практика
параллельных вычислений. http://www.intuit.ru/department/calculate/paralltp/ - 2007.
3. Мясищев А.А. Анализ эффективности
использования MPI для пересылки массива данных в системах с
двуядерными процессорами. – Материали за 4-а международна научна практична
конференция, «Динамика изследвания», - 2008. Том 27. Математика. Съвременни
технологии на информации. Здание и архитектура. София. «Бял ГРАД-БГ» ООД – 88
стр.