Современные
информационные технологии/Компьютерная инженерия
Омарова Лаззат Алимовна
Современная гуманитарная академия, Казахстан
Проблемы информационно-поисковых систем и способы их решения
В настоящее время, в
связи с быстрым появлением новой информации, возникает потребность в поиске
информации с использованием различных информационно-поисковых систем (ИПС).
Поиск актуальной информации является наиболее важной проблемой.
Информацию, находящуюся
на сервере необходимо постоянно обновлять, а на этот процесс может примерно затратиться 4 недели. Средняя длина поисковых запросов
очень мала и составляет 2-3 слова, соответственно построить качественную
выборку из миллиарда документов по такому «слепку информации» просто
невозможно. Выходом может служить сохранение контекста запросов пользователя,
их истории, предпочтений, но, к сожалению,
на сервере и это сделать невозможно, т.к. он и так достаточно перегружен
[1].
Решением выше описанных
проблем может служить создание новой архитектуры функционирования ИПС:
1.
переход к распределенной вычислительной модели. Система распределенных вычислений по
своей сути многомерна, с большим количеством участников - одноранговых узлов.
Ее можно противопоставить традиционным моделям вычислений. В модели
клиент-сервер в транзакцию вовлечены два участника - сервер, который
предоставляет некоторую услугу, и клиент, желающий ее получить. Отличаются
системы распределенных вычислений и от двухточечных приложений, объединяющих
пары машин для обмена друг с другом файлами. Как следствие этих различий,
необходимы новые протоколы и новые технологии [2].
В
системе распределенных вычислений необходимо обеспечить доступ к самым разным
ресурсам. У каждого ресурса есть своя система и владеющая им организация,
которая решает, какая часть ресурса доступна, в какое время и кому. Если не
вдаваться в детали, можно сказать, что суть системы распределенных вычислений в
управлении доступом к ресурсам.
Одним из вариантов
моделирования системы распределенных вычислений можно представить разбитым на
вычислительные кванты (квант - порция вычислений, производимых в каком-то
отдельном элементе оборудования, которая между своим началом и концом не
требует дополнительной информации от других элементов) (см. рис.1). Каждый
отдельный квант уже не является распределенным и выполняется в некотором месте физического пространства.
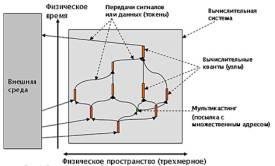
Рисунок 1 – Распределенный вычислительный процесс
С учетом физических
расстояний передача данных из одного места в другое может занимать значительное
время, которое может быть даже больше, чем собственно вычисления.
Выполнение
вычислительного кванта может быть инициировано в каком-то месте только тогда,
когда в этом месте собрана вся информация, необходимая для работы кванта. Эта
информация либо может поступить извне, либо может быть получена от других
квантов. Соответственно, результатами работы кванта могут быть порции данных,
предназначенные либо для других квантов, либо для передачи наружу в качестве
результата всего вычислительного процесса.
2.
переход от
модели «один поиск на всех» к модели персонального поиска. Слово «релевантность» обозначает соответствие,
релевантен – значит соответствует чему-либо. В поисковой оптимизации понятие «релевантность» используется поисковыми системами,
чтобы построить поисковую выдачу для удовлетворения интересов пользователя. При расчете релевантности учитываются внутренние и внешние
факторы [3].
Внутренние факторы –
обозначают то, на сколько хорошо текст страницы (документа) подходит для
раскрытия тех или иных поисковых запросов. Помимо текста есть и другие внутренние факторы:
внутренняя перелинковка (внутренние ссылки), поведение людей на странице с
текстом.
Внешние факторы – это внешние ссылки и упоминания.
Пертинентность – мера удовлетворенности пользователя
результатами поисковой выдачи. То есть данное понятие обозначает, насколько
результаты поиска соответствуют ожиданиям пользователя.
Нынешние алгоритмы поисковых систем стараются повышать
именно пертинентность. Для этого вводятся такие понятия, как «поведение
человека на сайте», «свежесть информации» другие. То есть поисковые
системы все больше начинают изучать поведение и интересы людей для того, чтобы
построить максимально релевантную выдачу.
Для решения проблемы перехода к
пертинентности, можно использовать для описания страниц дескрипторный язык
вместо ключевых слов. Дескриптор - одно или несколько слов данного языка
(синонимов), характеризующих данное понятие.
3.
построение
поисковой системы с точки зрения теории пространства (критерий пертинентности,
поиск в мультимедийном окружении). Первой
задачей поиска в мультимедийном окружении является поиск в базах данных [4]. Для организации поиска в табличной
информации, необходимо вербализовать эти данные, то есть перевести столбцы
чисел в некие текстовые отчеты, в которых будет произведен анализ данных в
таблице. Нужна некая система построения отчетов (генератор отчетов) для
написания отчетов на основании заданных рядов данных на естественных языках с
элементами математического и статистического (в будущем-эвристического)
анализа. Отличительной особенностью предлагаемой системы является то, что она
имитирует действия человека, читающего доклад с использованием графиков и
таблиц, то есть является следующим шагом в деле построения отчетов.
Второй наиболее реализуемой задачей представляется задача
распознавания речи и текста на изображениях, в том числе и рукописного. При
распознавании устной речи и рукописного текста на естественных языках возникают
проблемы, следующего рода. Существуют слова, близкие по звучанию, по набору
фонем. Например, «шесть» и «шерсть» (рус.), ship and sheep в английском.
Человек достаточно легко справляет с различением таких слов за счет понимания
контекста, в котором они произнесены, тогда как для компьютерных систем
различить такие близкие наборы звуков составляет почти неразрешимую задачу. Следовательно,
для распознавания речи нужно не только слышать ее, но еще и понимать о чем идет
речь. Человек однозначно воспринимает контекст и «домысливает» нерасслышанные
фонемы, в то время как существующие алгоритмы этот контекст просто не
учитывают.
Проблема распознавания решается
построением выражения алгебры понятий для тех гипотез значений, которые
наиболее вероятны для звучаний и написаний распознаваемых слов. (То есть
рассматриваются все варианты слов, которые могут быть получены из распознанной
информации). Так как распознавание происходит вместе с предыдущим контекстом,
то, при проведении отражения в пространство понятий, сразу можно проверить
попадание понятия в область, которая соответствует данному контексту, используя
механизм алгебры понятий. То есть, результат описанных в тексте преобразований
понятий попадает в определенную область, разрешенную по данному контексту и
значение для распознавания будет выбираться именно из этой (результирующей)
области, что решит проблему низкого качества распознавания.
Литература:
1. http://www.searchengines.ru
2.
http://www.island-formoza.ru
3. http://blog.businesskolusev.com
4. http://www.searchengines.ru