Филологические науки/5. Методы и приемы контроля уровня владения
иностранным языком
К.п.н. Кащеева
А.В.
Тамбовский государственный
университет имени Г.Р. Державина, Россия
Использование статистических методов в анализе письменного
дискурса
Использование статистических
методов в теории и практике обучения иностранному языку в настоящее время представляется
одним из перспективных направлений исследований. В отличие от других
математических методов (теорий множеств и алгоритмов, логические законы),
квантитативные методы в лингвистике позволяют осуществить многомерный
статистический анализ, который выявляет системные свойства языка и взаимосвязи
языковых явлений. Они способствуют более эффективному моделированию содержания
обучения, поскольку дают репрезентативные результаты в исследовании языка. Примером
использования квантитативных методов в обучении иностранному языку может
служить процедура дисперсионного анализа переменных устного дискурса (задания и
собеседника) в работе Энн Лазаратон [4].
Квантитативная лингвистика
(quantitative linguistics) – это одно из
направлений прикладной лингвистики, которое занимается изучением языка с
помощью статистических методов. В настоящее время количественные показатели
чаще всего используются для характеристики исторических изменений в языке и
анализе авторского стиля текста. Квантитативные методы включают простой
количественный анализ, дисперсионный анализ, анализ распределения и центральной
тенденции, регрессионно-корреляционный анализ, факторный и кластерный анализ, а
также анализ нейронных сетей как вид многофакторного статистического анализа.
Методы квантитативной
лингвистики применимы к разным уровням системы языка: фонетической,
орфографической, лексической, грамматической. Тем не менее, основным объектом
квантитативной лингвистики остается текст как сумма выборок (обозримых частей
лингвистических единиц). Этот факт является для нашего исследования отправной
точкой, позволяющей говорить о перспективе использования квантитативных методов
в изучении письменного учебного
дискурса.
В качестве примера
учебного дискурса мы анализировали образцы письменных работ студентов с
элементами рассуждения. Несмотря на большое количество исследований в теории
обучения, посвященных проблемам письма на иностранном языке, практика обучения письменному
учебному дискурсу показывает, что этап планирования и разработки содержания в
трехэтапной модели обучения все же вызывает наибольшую трудность у студентов. Кроме
этого, у преподавателей также возникает вопрос субъективности оценивания результата
по критериям соответствия содержания письменного дискурса теме задания и
полноте раскрытия темы. Постараемся изучить, насколько использование
квантитативных методов может способствовать более объективному оцениванию содержания
эссе.
Дискурсивная компетенция, согласно классическому
определению Каналь и Суэйн, заключается в знании правил когезии
(лексико-грамматической связности высказываний) и когерентности (текстовой
семантики), благодаря которым текст воспринимается и создается как единый
смысловой отрывок [3]. Детально исследуя проблему целостности понимания устного
дискурса, Томлин, Форэст и Пу отмечают, что когерентность может быть
разноуровневой: от собственных высказываний до дискурса в целом. Отметим, что эта
теоретическая модель справедлива также для его письменной формы. Модель
включает этапы концептуализации (риторической, тематической, референтной и
текущей), внутреннего плана высказывания, языкового оформления высказывания и
собственно речи [7.с.71].
Помимо правил когезии и
когерентности Арчибальд добавляет к модели дискурсивной компетенции знание
контекста и знание информационной структуры высказываний [2]. В определении Бахман дискурсивная компетенция приравнивается к
текстовой и означает владение такими правилами построения текста как когезия,
риторическая организация и конверсационные правила [5].
Все перечисленные
определения дискурсивной компетенции опираются на дискурс как результат
коммуникации в виде текста. Анализ дискурса как процесса устной или письменной
коммуникации отражается в определениях Байрам и Ричардс [1,6], которые основаны
на владении стратегиями создания, управления и восприятия дискурса в
определенном социокультурном контексте. Тем не менее, смысловое единство
дискурса остается его основной характеристикой, что и объединяет подходы к
дискурсу как результату и как процессу. Исходя из этого, мы предположили, что
использование статистических методов может быть эффективным для описания
лингвистических и структурно-семантических особенностей письменного учебного дискурса.
Для анализа способов
когезии и когерентности мы выбрали несколько образцов творческих письменных
работ с элементами рассуждения на тему “I’m
going to adopt
a pet” студентов 2 курса
отделения зарубежной филологии института филологии ТГУ имени Г.Р. Державина. Традиционно
к способам когезии относят такие лингвистические явления как референтность,
номинальную или глагольную замену, эллипсы, союзную связь, лексические способы
повторения и замены [3,6]. В рамках
статьи в качестве примера рассмотрим лишь использование референтности и союзной
связи. Для этого мы проанализировали выбранные нами переменные (лингвистические
явления) в нескольких выборках с примерно одинаковым количеством слов в каждой,
поскольку объем письменного высказывания был ограничен заданием в 250 слов.
В анализе способов
когезии, использованных студентами, мы посчитали наиболее информативными
простые числовые методы, а также методы факторного и
регрессионно-корреляционного анализа. Они позволяют не только выявить наиболее частотные явления, но и
влияющие на них скрытые языковые факторы. Простые числовые методы в лингвистике
включают определение частотности языкового явления в выборке на промежутке с
определенным количеством слов или страниц, что свидетельствует об
употребительности исследуемого явления. При сравнении частотности в разных
выборках можно использовать понятие среднего арифметического, по которому
исследователь ранжирует исследуемые явления языка [8].
Регрессионный
анализ заключается в установлении зависимости между постоянной (критериальной)
переменной и одной или несколькими независимыми. Регрессия показывает, на какую
величину может измениться значение одного признака, если другой меняется на
определенную единицу измерения. Величину регрессии можно вычислить с помощью статистических
функций Excel
и STATISTICA.
Для статистики регрессионный анализ важен, потому что он позволяет сделать
выводы о предполагаемой величине одного признака по значениям другого. Тем не
менее, для лингвистического анализа цифровой показатель регрессии не столь
информативен, как анализ диаграммы рассеяния и центральной тенденции. Диаграмма
рассеяния показывает, как располагаются отдельные проявления языкового явления
относительно средней величины центральной тенденции, и насколько велик их
разброс. Поскольку
регрессионный анализ выявляет степень зависимости одного признака от другого,
то чаще всего его называют регрессионно-корреляционным.
Другой наглядный
статистический метод, метод факторного анализа, представляет собой многомерное
исследование скрытых факторов, влияющих на сочетаемость единиц языка. Этот вид
анализа позволяет путем вращения матриц признаков выделить основные, по которым
переменные коррелируют между собой, а задача исследователя состоит в
интерпретации полученных факторов.
Проиллюстрируем на примерах использование указанных методов для анализа
способов когезии в учебном письменном дискурсе. Мы выбрали 4 работы студентов, оцененными
на «отлично», «хорошо» и «удовлетворительно». Используя числовые методы, в
каждой работе подсчитали количество предложений. Среднее арифметическое
количества предложений составило 19,75. Очевидно, что работы 1,3,4 близки к
среднему показателю. Количество союзов и слов-связок в каждой из работ
составило 10, однако в трех работах из 4 преобладали односложные слова-связки.
Кроме того, отношение
количества использованных способов когезии для связи предложений и их частей к
общему количеству предложений в работах 1,3,4 составило в среднем 43%, а в
работе 2 – 83%, что свидетельствует в пользу последней работы.
Для определения
взаимосвязи между количеством предложений в тексте и количеством использованных
средств связи мы воспользовались регрессионно - корреляционным анализом с
помощью пакета STATISTICA (рис. 1,2).
Рисунок
1.
Рисунок
2.
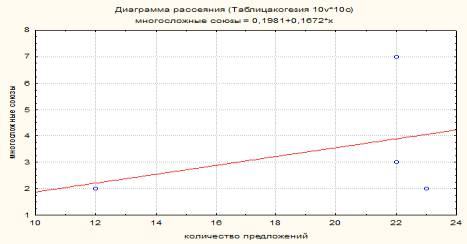
На рисунке 1 центральная
тенденция имеет положительное значение, направлена вверх, а вокруг неё
сосредоточились значения словоупотреблений сложных слов-связок, и лишь одна
точка c наибольшим значением находится на значительном удалении от
центральной тенденции (работа 2). Положительное значение центральной тенденции
позволяет сделать вывод о том, что увеличение количества предложений в тексте
вызывает увеличение использования многосложных средств связи. Это
свидетельствует о развитии дискурсивного смысла, поскольку многосложные связки
служат не только для добавления и противопоставления информации, как
односложные and, but, но и для выражения
причинно-следственных связей, вывода, представления новой информации, выражения
несогласия (however, moreover, nevertheless,
in spite of, furthermore).
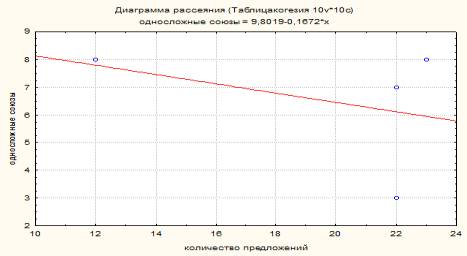
На рисунке 2 показана
зависимость количества предложений и односложных союзов. Линия центральной
тенденции направлена вниз, что свидетельствует об обратной пропорции числа
использованных союзов и числа предложений. Это можно объяснить тем, что
большинство предложений
характеризовалось отсутствием средств связи, что значительно снизило
качество работ и не способствовало когерентности письменного дискурса. Если
проследить корреляцию многосложных связок и односложных союзов, то диаграмма
рассеяния выглядит следующим образом (рис. 3).
Рисунок
3.
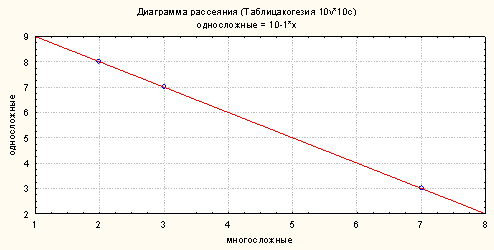
Рисунок показывает, что все
точки находятся на линии центральной тенденции, а зависимость использования
средств связи носит взаимоисключающий характер, то есть, чем больше
используется односложных союзов, тем меньше в тексте многосложных слов-связок.
Референтность как способ
когезии анализировалась с помощью факторного метода. Морфологические формы личных,
указательных и неопределенных местоимений, существительных с артиклем или
определением в работах студентов использовались в функции дополнения и подлежащего
в предложениях, представляющих как новую, так и известную информацию. Это было
сделано для того, чтобы проследить, насколько часто студенты используют
указанные формы для последовательного развития идеи абзаца, или они ограничиваются
кратким описанием основной идеи и
представляют новую идею, перегружая тем самым письменную работу. Матрица
морфологических форм представлена на рисунке 4.
Рисунок
4.
|
№ |
Личные местоимения - подлежащие в предложениях
с новой информацией |
Существительные – подлежащие в предложениях с
новой информацией |
Личные местоимения в функции дополнения |
Указательные местоимения в функции подлежащего
и дополнения |
Неопределенные местоимения подлежащее или
дополнение |
Личное местоимение в функции подлежащего |
Существительное в функции дополнения |
ссылка one |
|
1 |
20 |
8 |
5 |
0 |
1 |
3 |
2 |
1 |
|
2 |
10 |
6 |
1 |
0 |
2 |
3 |
2 |
0 |
|
3 |
10 |
14 |
6 |
2 |
0 |
11 |
1 |
1 |
|
4 |
12 |
11 |
5 |
0 |
2 |
5 |
2 |
1 |
С помощью STATISTICA мы
получили следующее распределение факторов, ограничив их число двумя (рис. 5).
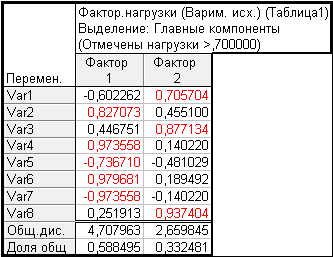 Рисунок 5.
Рисунок 5.
На рисунке 5 цветом выделены
наибольшие значения переменных. Первый фактор составляют переменные 2,4,5,6,7,
что свидетельствует о том, что референтность используется, в основном, в
синтаксической функции подлежащего. С точки зрения морфологии первый фактор
имеет выраженный номинативный характер. Второй фактор свидетельствует о
достаточно частом использовании местоимений в функции подлежащего и дополнения
для представления новой идеи в предложении по сравнению с развитием известной
информации. Сумма факторных нагрузок выше у первого фактора выше, что
подтверждает использование реферетности преимущественно для развития идеи
абзаца. Безусловно, проведенный анализ имеет
отношение только к избранным работам и может быть значительно расширен и
уточнен при получении данных из большего количества выборок.
Для исследования когерентности
письменного дискурса мы использовали кластерный анализ и семантический анализ с
помощью программы Tropes. Кластерный
анализ группирует переменные таким образом, что показывает степень их близости. Самые близкие объединены в кластеры на первом шаге, а
более удаленные – на следующих шагах, образуя древовидную структуру. В отношении выбранных нами работ студентов мы принимали
за переменные понятия, которые в них содержатся. Это позволило нам сделать
вывод о соответствии содержания заданной теме и способах логического построения
дискурсивной темы.
Опции программы Tropes характеризовали формат
письменного дискурса как аргументативное повествование от первого лица. Для описания
содержания каждой работы мы использовали опцию Reference Fields,
которая выявила следующие понятия в эссе: «домашние животные», «чувства», «человек», «семья», «время», «люди», «дружба».
Отмечались также некоторые нетипичные понятия («тело», «азартные игры»), потому
что они были классифицированы на основе единичных словосочетаний. Опция Scenario
выявила наиболее частотные укрупненные группы понятий: «природа и её обитатели»,
«личность», «поведение и чувства», «время и даты», «здоровье», что позволило
говорить о соответствии содержания заданной теме и однотипности приводимых
аргументов. На рисунке 6 представлено
семантическое поле работы № 3.
Рисунок
6.
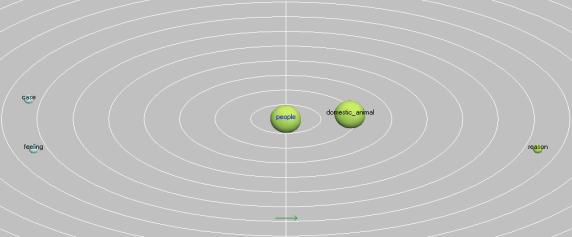
Среди выделенных понятий
«люди», «домашние животные», «причина», «забота» и «чувства» первое в наибольшей
степени связано с понятием «домашние животные», которое, однако, не является
центральным. Мы можем предположить, что на этапе планирования письменного
дискурса его автор рассматривал несколько ключевых идей: забота людей о
домашних животных; чувства и отношение к
домашним животным.
С помощью пакета STATISTICA мы
также выполнили кластерный анализ, принимая понятия за переменные. Вертикальная
дендрограмма выглядит следующим образом (рис. 7).
Рисунок 7.
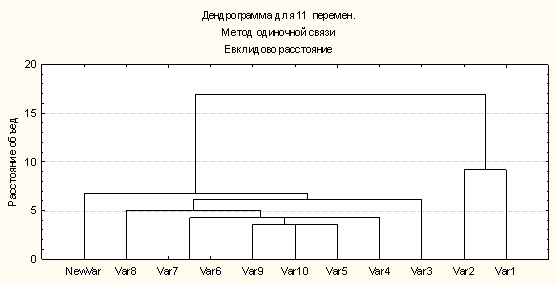
На рисунке видны два первых
кластера с переменными 9,10,5 и 1,2 свидетельствуют о присутствии двух главных
смысловых групп в смысловой структуре текстов: «дружба», «люди», «время» и «животные».
На втором шаге первая группа понятий объединяется с более общими понятиями
«человек» и «жизнь». На третьем шаге к этой группе присоединяется понятие «семья»,
на четвертом – «чувства», на пятом – «тело» (в нашем случае – глаза собаки как
способ выражения чувств), а потом две группы объединяются в один текст.
Таким образом, очевидно,
что для всех изученных отрывков письменного учебного дискурса наиболее важной
явилась тема дружбы домашних животных с человеком, которая была описана с точки
зрения длительности, испытываемых человеком чувств и отношения к ним социальной
группы (семьи). Другие аргументы, касающиеся вида, породы, содержания,
дрессировки, бытовых условий для домашних животных и их прав студентами не
рассматривались. Это говорит о преобладании моральных причин завести домашнее
животное над практическими аргументами и достаточно однообразном выборе
аргументов студентами. Отметим также, что на этапе планирования у студентов
возникают трудности во множественном выборе идей для выражения противоположных
точек зрения и их детальной разработке.
В заключение мы хотим отметить,
что использование статистических методов в анализе письменного дискурса может
решать несколько исследовательских задач. Данные процедуры позволяют описать
наиболее характерные особенности текста, в частности, выявить морфологические и
синтаксические взаимосвязи и описать смысловую структуру. С одной стороны, данные
анализа позволяют более объективно оценивать письменные работы с точки зрения
сформированности навыков использования средств когезии, соответствия смысловой
структуры текста заданной теме, разнообразия использованных понятий и
смыслового единства текста. С другой стороны, полученные данные могут служить
основанием для моделирования содержания обучения письменному дискурсу.
Выявленные особенности письменного дискурса могут быть включены в содержание
письменных заданий с элементами творчества на разных уровнях обучения. Процесс
выполнения заданий подобного рода, на наш взгляд, должен развиваться от
контролируемого до творческого письма.
Отметим, что обычно
применение статистических методов требует большей выборки для получения более
точных результатов. Однако их использование в достаточно малых выборках
свидетельствует об имеющейся тенденции и также является достоверным. В рамках
этой статьи мы постарались представить отдельные возможности анализа учебного
письменного дискурса с использованием методов статистического анализа. Наглядная
модель смысловой структуры текста и его лингвистических особенностей, на наш
взгляд, может способствовать пониманию того, как реализуются правила когезии и
когерентности. С этой целью мы предлагаем использовать статистические методы
разной сложности и направленности.
Литература.
1. Byram, M., Teaching and assessing intercultural communicative
competence. Multilingual Matters, 1997.
2. Callies, M., Information highlighting in advanced learner English.
John Benjamin’s Publishing Company, 2009.
3. Johnson, K., H. Johnson. Encyclopedic Dictionary of Applied
Linguistics: a handbook for language teaching. Blackwell Publishing. 1999.
4. Lazaraton, A., Quantitative and qualitative approaches to discourse
analysis // Annual Review of Applied Linguistics. CUP, 2002. № 22. P. 32-51.
5. Peterwagner, R., What is the matter with communicative competence?
Wien, 2005.
6. Richards, J.C., S. Rogers. Approaches and methods in language
teaching. CUP, 2004.
7. Tomlin, R.S., Forrest, L., Pu, M. Discourse Semantics // T.van Dijk
(ed.), Discourse as structure and process. London, 1997. P. 63-111.
8. Электронный учебник по
статистике. М., StatSoft. WEB:
http://www.statsoft.ru/home/textbook/default.html
(дата обращения 25.07.2012)