Cовременные информационные технологии/3. Программное обеспечение
Абдыкеримова Э.А., Абилхан Д.Р.
Каспийский
государственный университет технологий и инжиниринга имени Ш. Есенова, Казахстан
Высокопроизводительные
вычисления
с
использованием графического процессора
В данной статье мы провели сравнение принцип работы центрального и графического процессора. Центральный и графический процессор имеют схожие
цели, но оптимизированы для разных вычислений.
Разработчики
центрального процессора (англ. Central
Processing
Unit,
CPU)
для увеличения производительности процессора, стараются добиться выполнения как
можно большего числа инструкций. Благодаря
этому, инженеры компании Intel, начиная с процессоров Intel Pentium, добавили
технологию суперскалярное выполнение, обеспечивающее выполнение двух инструкций
за один такт, а Pentium Pro имел функцию внеочередного выполнения инструкций. Однако у параллельного выполнения
последовательного потока инструкций есть ограничение скорости, и если увеличить
количества исполнительных блоков, то все равно кратного увеличения скорости не
добиться.
Основные различия между
архитектурами центрального
и графического
(англ. Graphics
Processing
Unit,
GPU) процессора: ядра центрального процессора созданы для
исполнения одного потока последовательных инструкций с максимальной
производительностью, тогда как графический
процессор предназначен для быстрого исполнения большого числа
параллельно выполняемых потоков инструкций. Центральные процессоры
оптимизированы для достижения высокой производительности единственного потока
инструкций, обрабатывающего и целые числа и числа с плавающей точкой. При этом
доступ к памяти случайный [1].
Графический процессор
изначально имеет простую работу. Он принимает на входе группу полигонов,
обрабатывает, и на выходе выдаёт пиксели. Полигоны и пикселей обрабатываются
независима, как параллельно, так и отдельно друг от друга. Поэтому, изначально
организованной параллельной работы в графическом процессоре установлено большое
количество исполнительных блоков, которые с легкостью загружается, в отличие от
последовательного потока команд для центрального процессора. Однако,
современные центральные процессоры выполняют больше одной инструкции за такт, в
этом помогает им технология dual issue. Один из главных отличий графический
процессор от центрального - доступ к памяти. В GPU он связанный и легко
предсказуемый. Если, к примеру, из памяти читается пиксель текстуры, то через
некоторое время придёт время и для соседних пиксели. Принцип записи точно такой
же - пиксель записывается во фреймбуфер, и через несколько тактов будет
записываться расположенный рядом с ним другой фреймбуфер. Это и есть
существенное отличие организация памяти от той, что используется в CPU. И
графическому процессору, в отличие от центрального, не требуется кэш-память
большого размера, а для текстур требуются примерно 128 или 256 килобайт памяти [2].
Существует множество
различий и в технологиях многопоточности. Центральный процессор выполняет 1-2
потока вычислений на одно процессорное ядро, тогда как графический процессор
может поддерживать до 1024 потоков на каждый мультипроцессор, которых в чипе
несколько штук. И если переключение с одного потока на другой для CPU стоит
сотни тактов, то GPU переключает несколько потоков за один такт.
Кроме того, центральные
процессоры используют SIMD (одна инструкция выполняется над многочисленными
данными) блоки для векторных вычислений, а видеочипы применяют SIMT (одна
инструкция и несколько потоков) блоки для скалярной обработки потоков. SIMT не
требует, от разработчика преобразования данных в векторы, и допускает
произвольные ветвления в потоках выполнения.
Значительно большее
число транзисторов GPU работает по прямому назначению – обработке массивов
данных, а не управляет исполнением (flow control) немногочисленных
последовательных вычислительных потоков. Рисунок 1 показывает, сколько места в
CPU и GPU занимает разнообразная логика:
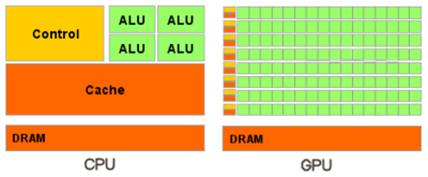
Рисунок
1.
Архитектура CPU
и GPU
В итоге, основой для
эффективного использования мощи GPU в неграфических расчётах является
распараллеливание алгоритмов на сотни исполнительных блоков, имеющихся в
графических процессорах. К примеру, множество приложений по молекулярному
моделированию отлично приспособлено для расчётов на графических процессорах,
они требуют больших вычислительных мощностей и поэтому удобны для параллельных
вычислений. А использование нескольких GPU даёт ещё больше вычислительных
мощностей для решения подобных задач.
В качестве вывода можно
продемонстрировать работу программы под названием Nvidia PhysX Particle Fluid.
Главной отличительной
чертой Nvidia
PhysX
Particle
Fluid
является функция переключения между графическим и центральным процессором, как
главный аппарат для вычисления. Рисунок 2 демонстрирует работу графического
процессора. Графический процессор нагружаясь на 36 %, с легкостью обрабатывает
более шестидесяти тысяч частиц жидкости, тем самым выдавая предельный
шестьдесят кадров в секунду.

Рисунок
2. Процесс работы GPU
А на рисунке 3 показан
работа центрального процессора. Он в свою очередь работал медленнее, чем
графический процессор. При 13% нагрузке, он долго обрабатывал шестьдесят тысяч
частиц, давая 4 кадров в секунду. Следует отметить, что в этом случае нагрузка
графического процессора составила 0-1%.

Рисунок 3. Процесс работы CPU
На
основе проведенных исследований можно сделать следующие выводы:
– полученные результаты
показывают эффективность реализации программ, поддающихся хорошей степени
параллелизма вычислений, с помощью графического
процессора;
– использование
видеокарты для реализации вычислений является более выгодным решением по
сравнению с использованием центрального процессора, как по экономическим, так и
по вычислительным причинам;
Подводя итог
вышесказанному, отметим, что переход к реализации программ и выполнение
вычислений с помощью графических процессоров общего назначения является более
эффективным, чем использование расчетов с помощью центрального процессора
применительно к областям, связанным с вычислением однотипных задач.
Список литературы:
1. Селифонов Е. В. Оптимизация работы
программ для графического процессора. http://is.ifmo.ru/papers/_selifonov.pdf
2. Бастраков С.И. Высокопроизводительные вычисления на GPU // Молодежная школа
«Высокопроизводительные вычисления для гибридных вычислительных систем», ННГУ,
2011.