Шарнин Л.М.1, Осипова А.Л.2, Ризаев И.С.3,
Яхина З.Т.4
1 профессор, доктор
технических наук; 2 преподаватель; 3 доцент, кандидат технических наук; 4
кандидат технических наук
Казанский национальный исследовательский
технический университет им. А.Н.Туполева
РАЗРАБОТКА
И ПРИМИНЕНИЕ ХРАНИЛИЩ ДАННЫХ
ДЛЯ РЕШЕНИЯ БИЗНЕС-ЗАДАЧ
Аннотация
Рассматриваются вопросы, связанные с необходимость интеграции данных при
решении бизнес-задач. Предлагается для консолидации и аналитической обработки
данных использовать технологию хранилищ данных.
Ключевые
слова: хранилище
данных, консолидация, агрегация, OLAP.
Sharnin L.M.1, Osipova A.L.2,
Rizaev I.S.3, Yahina Z.T.4
1 Professor, doctor of technical Sciences; 2 teacher; 3
associate Professor, candidate of technical Sciences; 4 candidate of
technical Sciences
Kazan national research technical University n.A.N.Tupolev
DEVELOPMENT AND APPLICATION OF DATA
WAREHOUSES
TO SOLVE BUSINESS PROBLEMS
Abstract
Discusses the need to integrate data for solving business tasks. Offered
for consolidation and analytical processing of the data from using the
technology of data storage.
Keywords: data
warehouse, consolidation, aggregation, OLAP.
Решение интеллектуальных аналитических задач
связано с обработкой больших объемов дынных, хранимых в самом разнообразном
виде и в самых различных источниках. Это
могут быть офисные документы, таблицы, файлы, базы данных различных неоднородных
СУБД и т.д. При этом данные могут быть
как избыточными, так и недостаточными. Для повышения информативности и
оперативности данных проводят их консолидацию на основе концепции хранилищ
данных [1,2].
Хранилище данных позволяют интегрировать
информацию и обеспечивать более высокую скорость обмена данными с
аналитическими приложениями. Для успешной реализации аналитических свойств
используют многомерное представление данных, которое на логическом уровне
представляется в виде многомерного куба.
Хранилище данных “data warehouse” (ХД),
предназначено для интеграции данных из различных источников, очистки,
трансформации и подготовки данных для
оперативной аналитической обработки (рис.1).
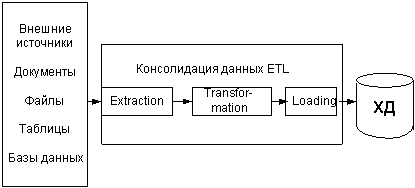
Рис.1. Процесс консолидации данных
Сам процесс консолидации включает целый ряд
этапов, называемых ETL (extraction - извлечение, transformation
- преобразование, loading -загрузка) [2]. В
процессе консолидации данные извлекаются из самых различных источников и
преобразуются в формат, поддерживаемый системой хранения, соответствующей
структуре ХД. Извлечение данных из различных источников должно сопровождаться
процедурой очистки данных, так как в исходных данных могут встречаться
различные ошибки, противоречия, пропуски,
дубликаты, аномалии и т.д. Извлекаемые данные, как правило, являются
максимально детализированными, так как в системах оперативной обработки (OTLP)
в базу данных заносится вся поступающая информация. Это, например, сведения о
ежедневных продажах товаров, сведения о
клиентах и т.д. Для аналитической обработки информации больший интерес представляют
обобщенные данные: за определенный
интервал времени, по группе товаров, клиентов и т.д. Такие обобщенные
данные называются агрегированными. В качестве агрегированных данных могут
выступать: сумма, среднее значение, максимальное (минимальное) значение,
количественные данные. Кроме того, при переносе данных в ХД требуется
производить очистку данных, так как исходные данные могут оказаться
некорректными, противоречивыми, имеющими пропуски, дублирования,
несоответствующие форматы. После того, как будут выполнены основные операции,
связанные с извлечением, очисткой, агрегированием выполняется этап загрузки
данных в ХД. Загрузка данных может осуществляться в виде процесса добавления,
или изменения. Кроме того после загрузки могут быть осуществлены операции переиндексации
и верификации данных.
После предобработки и загрузки данных в
хранилище в ряде случаев для подготовки информации к аналитической обработке проводят трансформацию. Трансформация проводится с
целью подготовки данных к более качественному анализу, для чего осуществляют
объединение и выделение наиболее ценной информации. К методам трансформации
можно отнести следующие операции: преобразование упорядоченных данных, квантование,
сортировки, слияние, группировки, дополнительные вычисления, нормализацию и
т.д.
Группировка производится для обобщения данных по
ряду параметров, например, по дате, товарам, клиентам. Обобщенные данные лучше характеризуют
свойства признаков в целом. Слияние проводится с целью объединения данных, «разбросанных»
по различным таблицам для повышения эффективности анализа.
Для решения задач оперативной аналитической
обработки данных в хранилищах данных используется концепция OLAP.
Выделяют три основных способа реализации оперативной аналитической обработки
данных: MOLAP, ROLAP, HOLAP.
В настоящее время, более широко используется
модель ROLAP, которая реализуется или по схеме «звезда», или по схеме
«снежинка».
Основными понятиями многомерной модели
(рис.2) данных являются: Измерение (Dimension), Уровень измерения (Level),
Метка (Memders), Ячейка (Cell), Мера (Measure) .
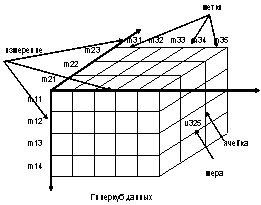
Рис.2. Гиперкуб данных.
Логически гиперкуб данных
представляет собой объект, организованный в соответствии с измерениями данных.
Математическое представление многомерных данных можно записать следующим
образом:
![]() , где
, где
![]() ,
,
![]() - множество измерений
куба и
- множество измерений
куба и ![]() - мера, которая представляет собой факт куба (например,
продажа).
- мера, которая представляет собой факт куба (например,
продажа).
![]() - множество значений
измерения.
- множество значений
измерения.
Ts – набор данных ячейки или набор
кортежей в форме: ![]() , где ti1 Î dom(d1), …. tin Î dom(ds).
, где ti1 Î dom(d1), …. tin Î dom(ds).
C0n
–атомарный куб, состоит из детальных данных в соответствии с самым низким уровнем класса иерархии.
![]() где:
где:
![]() ,
, ![]() - множество измерений куба и
- множество измерений куба и
![]() - мера, которая представляет собой факт куба (например,
продажа).
- мера, которая представляет собой факт куба (например,
продажа).
![]() , множество значений измерения, представляющих самый низкий
уровень класса иерархии.
, множество значений измерения, представляющих самый низкий
уровень класса иерархии.
T0n – набор
данных ячейки или набор кортежей в форме: ![]() , где ti1 Î dom(d1), … tin Î dom(ds).
, где ti1 Î dom(d1), … tin Î dom(ds).
Одним из
важнейших свойств куба данных является возможность получения другого куба с помощью функций группирования, таких как
{sum, avg, count, max, min ….} и операций преобразований: свертывания, развертывания,
проекции, вращения, среза и др.
Типичная структура
хранилища данных существенно отличается от структуры обычной реляционной СУБД.
Как правило, эта структура денормализована (это позволяет повысить скорость
выполнения запросов), поэтому может допускать избыточность данных.
Основными составляющими
структуры хранилищ данных являются таблица фактов (fact table) и таблицы
измерений (dimension tables).
Таблица фактов
является основной таблицей хранилища данных. Как правило, она содержит сведения
об объектах или событиях, совокупность которых будет в дальнейшем
анализироваться. К фактам можно отнести: отдельные события, транзакции,
моментальные снимки и т.д.
Одно измерение куба
может содержаться как в одной таблице (в том числе и при наличии нескольких
уровней иерархии), так и в нескольких связанных таблицах, соответствующих
различным уровням иерархии в измерении. Если каждое измерение содержится в
одной таблице, такая схема хранилища данных носит название «звезда» (star
schema). Пример такой схемы приведен на рис. 3.
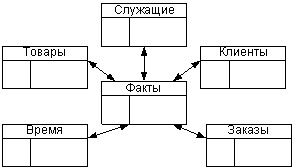
Рис.3. Модель хранилища данных по схеме
«Звезда»
В хранилище данных для повышения эффективности
обработки данных используется специальный термин «материализованное
представление (МП)» [2,3].
МП (MATERIALIZED VIEWS)
- это тип представления, который пересчитывает и хранит агрегированные данные,
такие как сумма или средние значения [3].
Применение материализованных представлений может
резко повысить эффективность запросов, а также значительно уменьшить нагрузку
на систему. Это объясняется тем, что в этом случае потребуется меньшее количество
логических чтений для удовлетворения запросов, чем тот же запрос будет работать
в среде базовых таблиц.
Рассмотрим следующий пример: Необходимо найти
количество продаж, касающееся клиентов конкретного города, в определенном
подразделении и в конкретное время, но без использования материализованного представления.
Запрос составленный на SQL будет следующим:
SELECT SUM(price_quantity)
SALES$
FROM sales, customers, times,
branches
WHERE
sales.time_key=times.time_key AND
sales.customer_key=customers.customer_key AND
customers.city_key=countries. Countries.city_key AND
sales.branch_key= branchs.branch_key AND
branchs.branch_name
IN ('Direct Sales', 'Internet') AND
times.month =
9 AND
times.year= 2006 AND
customer.city IN ('Москва', 'Казань');
Для организации подобного запроса потребуется 4
операции соединения “JOIN”. В случае применения
больших таблиц понадобится значительное время для выполнения подобного запроса.
Если использовать материализованное
представление, то ответ на запрос будет иметь следующий вид]:
SELECT SUM(price_quantity) SALES$
FROM view_sales
WHERE branch_name
IN ('Direct Sales', 'Internet') AND
month = 9 AND
year= 2000 AND
City IN ('Москва', 'Казань');
В
этом случае все операции соединения исчезают и остаются только
логические операции. Результаты таких исследований представлены на рис.4. Видно, что без использования
материализованных представлений время обработки
значительно увеличивается с увеличением числа строк, и практически остается
неизменным (меньше 1 сек.) при использовании материализованных представлений.
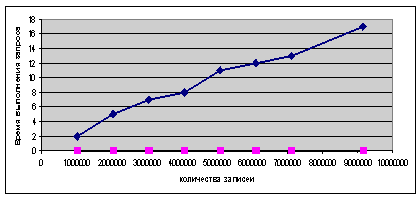


Рис.4.
Время выполнения запроса с использованием материализованного представления
(нижняя линия) и без использования материализованного представления (верхняя
линия).
Основными средствами анализа и добычи новых
знаний стали такие средства, как OLAP и DATA
MINING. Система OLAP - позволяет пользователям
анализировать данные с помощью сложных многомерных представлений.
Различные запросы, поступающие к ХД, как
простые, так и сложные должны завершатся
за приемлемое время с учетом, что размеры ХД возрастают с огромной скоростью и
достигают величин от сотен гигабайт до - терабайт и даже петабайт. Большое
время отклика может стать источником разочарования для многих пользователей.
Так как запросы в основном осуществляются с помощью декларативного языка SQL,
то с пользователя снимается ответственность за принятие соответствующей
стратегии для повышения наибольшей производительности. Такая задача ложится на
службы поддержки ХД. С этой целью должна быть выбрана соответствующая СУБД. На
рис.5 дается сравнительная характеристика использования различных СУБД при
обработке больших массивов данных.
Современные разработчики СУБД предлагают
достаточное количество продуктов для построения ХД: Oracle, DB2,
Microsoft SQL Server
2000 и др. Для построения ХД в качестве основной СУБД предлагается использовать
Oracle Database. Было проведено сравнение эффективности
обработки данных для различных СУБД, с применением баз данных одинакового
объема порядка 10 Гбайт.

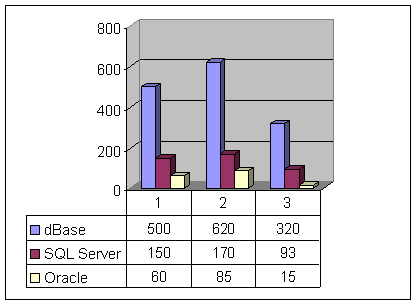
Рис.5. Сравнение
эффективности различных типов БД
Эксперимент показал, что применение СУБД Oracle на много эффективнее по сравнению с
другими системами баз данных.
Заключение
Для успешного решения
бизнес-задач могут использоваться самые различные документы: файлы, массивы, электронные таблиц, базы
данных различных структур и форматов. Для эффективного анализа данных и принятия
решений необходимо иметь консолидированное представление об объектах и
процессах рассматриваемой предметной области. Для решения подобных задач
предлагается воспользоваться технологией хранилищ данных, которая основывается
на представление данных в виде многомерных моделей. Возможность использования
функций группирования, операций
преобразования и материализованного представления могут существенно улучшить организацию
запросов к хранилищу данных.
Литература
1.
Барсегян
А.А., Куприянов В.В. Степаненко И.И., Холод И.И. Технологии анализа данных: Data Mining,
Visual Mining, Text
Mining, OLAP // 2-е изд., перераб. и
доп. – СПБ.: БХВ-Петербург. 2008.-384 с.
2.
Паклин Н.Б., Орешков В.И. Бизнес-аналитик: от данных к
знаниям: Учеб.пособие СПб.: Питер. 2010.
3.
Ризаев
И.С., Рахал Я. Интеллектуальный анализ данных для поддержки принятия решений.
–Казань: Изд-во МОиН РТ, 2011, - 172 с.