Krivoy Rog national
university, Ukraine
SOUND
WAVE MODEL CONSTRUCTION IN CONTEXT OF ROBUST SIGNAL GENERATION
Introduction
Sound
wave model construction allows to describe sound parameter modification in the time
domain used in various sound synthesizers. While a real musical instrument is playing
its loudness changes through the time. Each musical instrument has its own
changes of loudness features. For example, organ plays the notes with the
permanent loudness, but guitar plays the sounds with maximal loudness only in
the attack moment of the string after that it smoothly fades out. Wind musical
instruments are characterized by reaching the maximum loudness not in the
attack moment but after some period of time.
ADSR-envelope
ADSR-envelope
realizes such changes by using a small collection of parameters. This is the simplest
and the most widespread sound dynamic model which helps to describe the
progress laws in time for most of the sounds. According to mathematics, the
loudness level modulation of a signal comes to the simple multiplication of the
signal form (timbre) and ADSR-form, as a result the output signal form is
limited by the form of ADSR-oscillation.
ADSR-envelope
is an important sound characteristic of the musical instruments and a one of
the main criteria of musical instrument identification. The envelope consists of
four main sections (stages) (fig. 1):
1. Attack (A) – the
period of initial signal loudness increasing;
2. Decay (D) – the period
of signal decaying after the initial increasing;
3. Sustain (S) – the
period of constant signal power;
4. Release (R) – the
period of final signal fading.
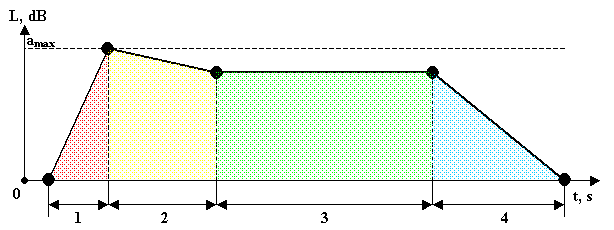

1 – attack, 2 – decay, 3 – sustain, 4 – release
Figure 1 – ADSR-envelope
Not all
of the stages could be represented in ADSR-envelope: it depends on a specific
musical instrument. For example, piano has all of these stages, but flute can
be viewed only in sustain stage, the others may be ignored. Because of
nonlinearity of the initial and final sound stages for the robust digitization
it is necessary to have a sample rate at least in five times over the sound
oscillation frequency [44].
Attack time determines a period of time
to reach the maximum loudness level (key pressing event).
Decay time determines a period of time to
come from the maximum loudness level to sustain level.
Sustain time describes a sound level which
is playing while key is holding (key holding event).
Release time determines a period of time
to the final fading of the note sound level (key releasing event).
Now, it
is necessary to implement and describe a mathematical model of the sound wave,
following by ADSR-scheme.
The main
advantage of this model is that it is not mathematically complicated and fits
for most sound simulation. But for the parameter completeness and of course for
the reliability improving another one period is needed – hold time which could describe the maximal loudness sound level conservation
law.
Our
received model of the sound oscillations will be called AHDSR (Attack-Hold-Decay-Sustain-Release) and shows it in more
detail (fig. 2).
AHDSR-model description
Let the
individual musical note is describing as (fig. 2):
|
|
|
(1) |
where
t – time (![]() );
);
tn – onset time (![]() );
);
![]() – duration time (sustain time) (
– duration time (sustain time) (![]() );
);
![]() – relative attack time (
– relative attack time (![]() );
);
![]() – relative hold time (
– relative hold time (![]() );
);
![]() – relative decay time (
– relative decay time (![]() );
);
![]() – relative release time (
– relative release time (![]() );
);
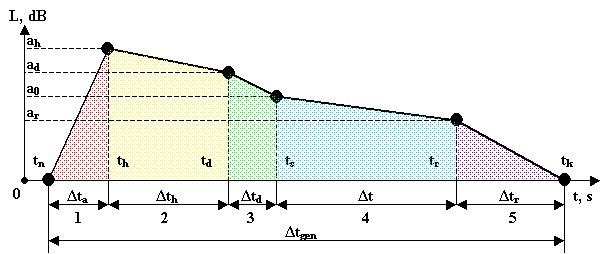

1 – attack, 2 – hold, 3 – decay, 4 – sustain, 5 – release
Figure 2 – AHDSR-envelope
a0 – sustain loudness
(a0 > 0);
f0 – pitch (f0 > 0);
![]() – coefficient determing the maximal
value of sounding duration (sustain time) (
– coefficient determing the maximal
value of sounding duration (sustain time) (![]() ):
):
if ![]() , then
, then ![]() and
and ![]() don't change,
don't change,
if ![]() , then
, then ![]() , but
, but ![]() ;
;
![]() – relative frequencies of the
partial harmonics (fi >
0);
– relative frequencies of the
partial harmonics (fi >
0);
![]() – percentage of the partial
harmonics (
– percentage of the partial
harmonics (![]() );
);
![]() – oscillation phases of the
partial harmonics;
– oscillation phases of the
partial harmonics;
![]() – timbre function:
– timbre function:
|
|
|
(2) |
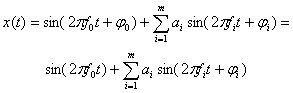 ,
,where
![]() – oscillation phase of the
fundamental harmonic (
– oscillation phase of the
fundamental harmonic (![]() );
);
m – number of partial harmonics (![]() );
);
ah – hold loudness coefficient (![]() );
);
ad – decay loudness coefficient
(![]() );
);
ar – release loudness
coefficient (![]() );
);
Parameters ah, ad, a0
and ar are choosing in the
way to satisfy the following inequality:
|
|
|
(3) |
ga(t) – attack function of time t;
gh(t) – hold function of time t;
gd(t) – decay function of time t;
gs(t) – sustain function of time t;
gr(t) – release function of time t.
Let add
some more model parameters for convenience and system completeness (4) – (12):
|
|
|
(4) |
where
![]() – coefficient determing
instantaneous (
– coefficient determing
instantaneous (![]() ) oscillation process duration of frequency up to 1 Hz and intensity up
to 1 dB;
) oscillation process duration of frequency up to 1 Hz and intensity up
to 1 dB;
|
|
|
(5) |
|
|
|
(6) |
|
|
|
(7) |
|
|
|
(8) |
|
|
|
(9) |
|
|
|
(10) |
|
|
|
(11) |
|
|
|
(12) |
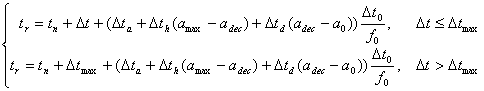 ;
;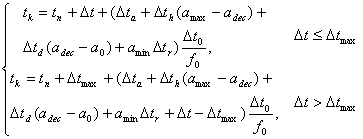 ;
;
In
terms of above-listed formula, let set the values of real sound wave times (13)
– (18):
|
|
|
(13) |
|
|
|
(14) |
|
|
|
(15) |
|
|
|
(16) |
|
|
|
(17) |
|
|
|
(18) |
Including
the following conditions are to be satisfied (19) – (21):
|
|
|
(19) |
|
|
|
(20) |
|
|
|
(21) |
From formula (1) – (21) we receive the
equation (22) for
the inividual sound
wave:
|
|
|
(22) |
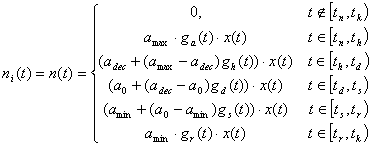
The equation
(22) is true in ideal cases of the practical
modelling techniques, as it doesn't contain any deviations and noise. Thus, it
is necessary to add a noise component ![]() which would distort the source
sound oscillation by k times:
which would distort the source
sound oscillation by k times:
![]() , in case of additive noise model,
, in case of additive noise model,
![]() , in
case of multiplicative noise model;
, in
case of multiplicative noise model;
The function ![]() returns random values in the range (-1, 1), which cause
more (if
returns random values in the range (-1, 1), which cause
more (if ![]() ) or less (if
) or less (if ![]() ) effect on the oscillation system:
) effect on the oscillation system:
|
|
|
(23) |
In addition
to that, it is necessary to add an external
noise component ![]() which would be the same
relation as
which would be the same
relation as ![]() but applied to the whole sound
signal (would effect on all of the sound objects of the system which are taking
part in the oscillation process).
but applied to the whole sound
signal (would effect on all of the sound objects of the system which are taking
part in the oscillation process).
Conclusions
Therefore,
a musical piece is a N-set (24) – a set of the elementary sound objects ni(t) (![]() ):
):
|
|
|
(24) |
where
m – number of the notes in a musical piece.
If (24)
is written more detailed then:
|
|
|
(25) |
where
p – external noise level.
Thereby,
formula (22) specifies the equation of the sound wave according to the AHDSR-scheme,
including its harmonic, amplitude, temporal and functional characteristics.
References:
1.
Белобородов А. Ю.
Распознавание аудиообразов с применением обертонового ряда. — Инженерия
программного обеспечения. — №3. — Киев, 2010.
2.
Голд, Б. Цифровая
обработка сигналов (под ред. Трахтмана А. М.) / Б. Голд, Ч. Рэйдер. — М.:
Советское радио. — 1973.
3.
Попов, О. Б. Цифровая
обработка сигналов в трактах звукового вещания: учебное пособие / О. Б. Попов,
С. Г. Рихтер. — "Горячая линия - Телеком". — М. — 2007.
4.
Френкс Л. Теория
сигналов (под ред. Вакмана Д. Е.). — М.: Советское радио. — 1974.