ОПРЕДЕЛЕНИЕ ЯЗЫКА ЗВУЧАЩЕЙ РЕЧИ
К.т.н. Гусев М.Н.
ФГУП НИИ «Квант», Санкт-Петербург, Россия
michael.n.gusev@gmail.com
Д.т.н. Дегтярев В.М.
Санкт-Петербургский
государственный университет телекоммуникаций им. проф. М.А. Бонч-Бруевича,
Санкт-Петербург, Россия
degtyrev@sut.ru
Плотникова Е. В.
Санкт-Петербургский
государственный университет телекоммуникаций им. проф. М.А. Бонч-Бруевича,
Санкт-Петербург, Россия
ne.nya@mail.ru
Постановка задачи
Речевой сигнал
характеризуется определенным набором объективных характеристик: временной
структурой сигнала, длительностью звучания, спектральным составом и т.д.
Структура речевого сигнала определяется не только семантикой передаваемого
высказывания. Речь несет также и информацию и информацию об эмоциональном
состоянии диктора, его индивидуальные параметры, позволяющие отличать дикторов
друг от друга.
Спектр речи постоянно
изменяется во времени, но если наблюдать его достаточно долго, то можно получить
довольно устойчивую спектрограмму. Спектром речи называется зависимость среднего
в течение длительного времени спектрального уровня речи от частоты [1]. Эта зависимость показывает распределение
энергии по различным частотам, характерное для данного языка.
Для того, чтобы
передавать информацию язык должен состоять из конечного числа различимых и
различающихся элементов. Основной единицей звукового строя языка является
фонема. Возможные варианты реализации фонем называют аллофонами. Звуковой
состав различных языков имеет свои особенности.
Не существует единого
мнения относительно конкретного звукового состава различных языков. Так, только
для русского языка по одним данным 43 фонемы, по другим – 64 по третьим
их более сотни. Как-бы то ни было, спектры речи, полученные для различных
языков, различаются.
Для примера на рисунке 1
представлены спектры речи для четырех языков: английского французского,
японского и русского. Кроме того, на рисунке 1 приведена кривая,
соответствующая спектру речи, среднему по всем представленным языкам.
Учет выявленного
различия может быть полезен при оценке качества передачи речи, т.к. вклад в
оценку различных частотных групп определяется спектром речи. Зная язык звучащей
речи можно было бы корректировать веса и подстраивать систему оценки качества,
повышая точность получаемых оценок. На практике пользователь не всегда может
дать системе подсказку – указать язык сообщения, а значит, система должна уметь
это делать самостоятельно. Таким образом, возникает актуальная задача
автоматического определения языка звучащей речи.
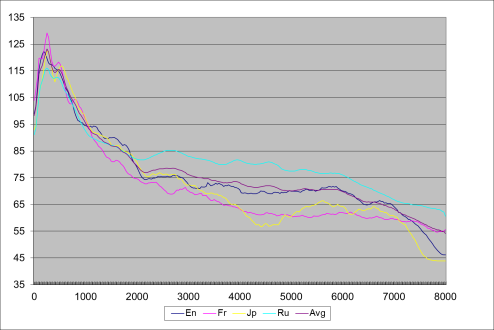

Рисунок 1 – Спектры речи
Подходы к решению
Речеобразующая система
человека способна воспроизводить практически неограниченный набор звуков. Как
уже отмечалось, каждый язык имеет определенный звуковой состав (фонетику).
Различные языки могут использовать пересекающиеся множества фонем, но частоты
встречаемости фонем будут различаться. Кроме того, языки различаются комбинациями
разрешенных последовательностей фонем (фонотактика). Так, комбинации, часто
встречающиеся в одном языке, могут быть запрещены в другом.
Фонетика и фонотактика
оказываются естественными системами признаков для автоматического определения
языка звучащей речи. Сложность заключается в том, что для задействования
фонетики и фонотактики требуется использовать систему распознавания речи. В рамках
поставленной задачи такое решение представляется неоправданно громоздким.
Поэтому было решено
использовать средства параметризации, предоставляемые системой оценки качества
автоматически, а именно – спектральный анализ. Действительно, раз спектры речи
на разных языках различаются, то почему бы не определять принадлежность записи
к языку по степени подобия спектров?!
Структура системы
Для определения языка
звучащей речи было создана программа, работающая по схеме, представленной на
рисунке 2. Функции цифровой обработки сигналов были заимствованы из системы
оценки качества передачи звука AQuA [2].
В разработанной
программе предусмотрено два режима работы: режим определения языка звучащей
речи и режим построения модели языка. В режиме определения языка на вход
программы подается один звуковой файл. В режиме обучения программа работает не
с одним звуковым файлом, а с набором записей. Выполняется предварительная
проверка качества записей по соотношению сигнал/шум. Только не содержащие шума
записи используются в обучении. После проверки принятые к обработке записи
объединяются в один звуковой поток и обрабатываются по общей схеме. Все записи,
используемые для обучения должны иметь одинаковый формат.
Входящий звук проходит
предобработку, заключающуюся в фильтрации, изменении частоты дискретизации и
нормализации уровня энергии сигнала. Изменение частоты дискретизации
выполняется только в том случае, если частота дискретизации не совпадает с
частотой дискретизации моделей языков.
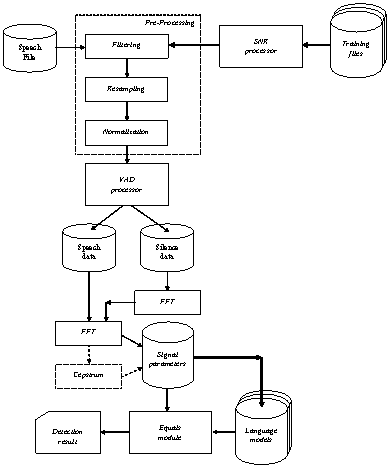
Рисунок 2 – Схема работы
программы
определения языка
звучащей речи
Далее сигнал
обрабатывается с помощью алгоритма VAD и разделяется на речь и
«тишину». Сначала обрабатывается «тишина». По данным, отнесенным к «тишине»,
строится интегральный спектр, который передается на модуль построения спектра
речевой составляющей сигнала. В процессе построения интегрального спектра
речевых данных выполняется его коррекция на спектр «тишины». Таким образом,
выполняется очистка спектра речевых данных от стационарного шума.
В случае необходимости
по спектру речевых данных строится интегральный кепстр речевого сигнала.
Интегральные спектр и кепстр сигнала составляют его параметрическое описание. В
режиме обучение параметрическое описание сохраняется в базе моделей, а в случае
определения языка передается на модуль сравнения.
Модуль сравнения
подгружает модели языков и параметры идентифицируемого звука, а затем выполняет
сравнение параметров звука с моделями. Имя модели, ближайшей к параметрам звукового сигнала, вместе с коэффициентом
подобия принимается за результат определения языка.
Эксперименты по определению языка звучащей речи
Для каждого из
перечисленных языков были построены спектры речи. Длительность звукозаписей для
каждого языка составила около часа. Использовались записи с частотой
дискретизации 16 кГц. Для проверки точности идентификации на английском,
французском и японском языках использовались записи базы ITU-T
[3]. Для русского языка была создана тестовая база, включающая 260 записей, с
длительностями менее 20 секунд. (Длительность записей в базе ITU-T 8
секунд.)
Для определения степени
подобия (LS) спектра речи модели i-того языка (ISi)
со спектром анализируемой записи (SS) была использована
следующая простая формула:
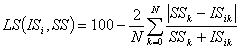 (1)
(1)
Спектр речи, обладающий
наибольшим подобием принимался за искомый. Сопоставление по формуле 1 позволило
получить следующие показатели точности определения (таблица 1):
Таблица 1 – Точности
определения языка речи с использованием (1)
|
Язык |
Распознано как |
Ok |
Fail |
|||
|
EN |
FR |
JP |
RU |
|||
|
EN |
114 |
73 |
0 |
0 |
60,96257 |
39,03743 |
|
FR |
2 |
186 |
0 |
0 |
98,93617 |
1,06383 |
|
JP |
20 |
0 |
168 |
0 |
89,3617 |
10,6383 |
|
RU |
26 |
0 |
5 |
229 |
88,07692 |
11,92308 |
|
Result |
|
337,3374 |
62,66264 |
|||
Видно, что сумма ошибок
превышает 60%. Данный результат не может быть признан удовлетворительным. Было
принято решение провести эксперименты по использованию различных функций
подобия.
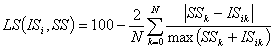 (2)
(2)
Попытка использования
формулы подобия с нормированием на максимальную компоненту спектра (2) дало
точности определения, представленные в таблице 2. Полученный прирост точности
определения невозможно считать существенным.
Таблица 2 – Точности
определения с использованием (2)
|
Язык |
Распознано как |
Ok |
Fail |
|||
|
EN |
FR |
JP |
RU |
|||
|
EN |
114 |
73 |
0 |
0 |
60,96257 |
39,03743 |
|
FR |
2 |
186 |
0 |
0 |
98,93617 |
1,06383 |
|
JP |
21 |
0 |
167 |
0 |
88,82979 |
11,17021 |
|
RU |
26 |
|
6 |
228 |
87,69231 |
12,30769 |
|
Result |
|
336,4208 |
63,57917 |
|||
Анализ спектров записей
показал, что часто из-за малой длительности их спектры не в полной мере
соответствуют спектрам речи. Соответствие достигается лишь на наиболее
распространенных частотах. Поэтому было принято решение выполнять сравнение
только по значениям максимумов в спектре записи (3):
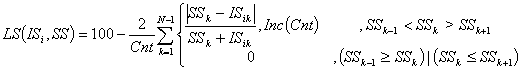 (3)
(3)
Сопоставление по формуле
3 позволило повысить точности определения языка (таблица 3):
Таблица 3 – Точности
определения языка речи с использованием (3)
|
Язык |
Распознано как |
Ok |
Fail |
|||
|
EN |
FR |
JP |
RU |
|||
|
EN |
136 |
51 |
0 |
0 |
72,72727 |
27,27273 |
|
FR |
6 |
182 |
0 |
0 |
96,80851 |
3,191489 |
|
JP |
14 |
0 |
172 |
2 |
91,48936 |
8,510638 |
|
RU |
14 |
0 |
6 |
240 |
92,30769 |
7,692308 |
|
Result |
|
353,3328 |
46,66716 |
|||
Из таблицы 3 видно, что
благодаря использованию нового способа сопоставления сумма ошибок снизилась на
16%. Для всех языков, кроме английского точность определения оказывается
приемлемой.
Эксперименты по
ограничению частотного диапазона как сверху (таблица 4), так и снизу (таблица
5) положительного результата не дали. Любое ограничение приводило к снижению точности.
Таблица 4 – Точности
определения при ограничении частотного диапазона 0 – 7900Гц
|
Язык |
Распознано как |
Ok |
Fail |
|||
|
EN |
FR |
JP |
RU |
|||
|
EN |
133 |
54 |
0 |
0 |
71,12299 |
28,87701 |
|
FR |
4 |
184 |
0 |
0 |
97,87234 |
2,12766 |
|
JP |
20 |
0 |
137 |
31 |
72,87234 |
27,12766 |
|
RU |
22 |
0 |
7 |
231 |
88,84615 |
11,15385 |
|
Result |
|
330,7138 |
69,28617 |
|||
Таблица 5 – Точности
определения при ограничении частотного диапазона 50 – 8000Гц
|
Язык |
Распознано как |
Ok |
Fail |
|||
|
EN |
FR |
JP |
RU |
|||
|
EN |
136 |
51 |
0 |
0 |
72,72727 |
27,27273 |
|
FR |
7 |
181 |
0 |
0 |
96,2766 |
3,723404 |
|
JP |
14 |
0 |
172 |
2 |
91,48936 |
8,510638 |
|
RU |
14 |
0 |
6 |
240 |
92,30769 |
7,692308 |
|
Result |
|
352,8009 |
47,19908 |
|||
Эксперименты со
способами нормировки позволили предложить формулу (4), также повышающую
точность определения:
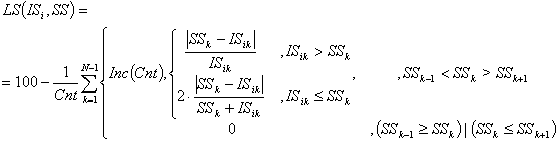 (4)
(4)
Точности определения,
полученные с использованием формулы (4) представлены в таблице (6):
Таблица 6 – Точности
определения языка речи с использованием (4)
|
Язык |
Распознано как |
Ok |
Fail |
|||
|
EN |
FR |
JP |
RU |
|||
|
EN |
163 |
22 |
2 |
0 |
87,16578 |
12,83422 |
|
FR |
13 |
175 |
0 |
0 |
93,08511 |
6,914894 |
|
JP |
1 |
0 |
184 |
3 |
97,87234 |
2,12766 |
|
RU |
4 |
0 |
6 |
250 |
96,15385 |
3,846154 |
|
Result |
|
374,2771 |
25,72293 |
|||
Введение формулы 4
повысило суммарную точность определения на 21 %, однако точность определения
английского языка так и осталась ниже пороговых 90%.
Переход к
логарифмическим спектрам также не дал желаемый результат (таблица 7).
Таблица 7 – Точности
определения языка речи по логарифмическим спектрам
|
Язык |
Распознано как |
Ok |
Fail |
|||
|
EN |
FR |
JP |
RU |
|||
|
EN |
3 |
184 |
0 |
0 |
1,604278 |
98,39572 |
|
FR |
0 |
188 |
0 |
0 |
100 |
0 |
|
JP |
173 |
7 |
8 |
0 |
4,255319 |
95,74468 |
|
RU |
149 |
4 |
0 |
107 |
41,15385 |
58,84615 |
|
Result |
|
147,0134 |
252,9866 |
|||
Дополнительные параметры
Дальнейшие эксперименты
с использование других функций вычисления подобия, наложение весов на вклад
различных частот в подобие, выбор способов нормирования, а также применение
сглаживания спектра не позволили увеличить точность определения языка.
Поэтому было принято
решение о поиске дополнительных параметров, повышающих точность определения
языка. Дополнительным требованием при выборе дополнительных параметров стала
простота их получения на базе функционала системы оценки качества передачи
речи.
Первым кандидатом из
легко получаемых стал кепстр сигнала, представляющий собой спектр
логарифмического спектра сигнала. Считается, что кепстральное представление
лучше подчеркивает особенности частотной структуры сигнала.
По аналогии со спектрами
речи, представленными на рисунке 1, были построены кепстры речи. Полученные
зависимости представлены на рисунке 2.
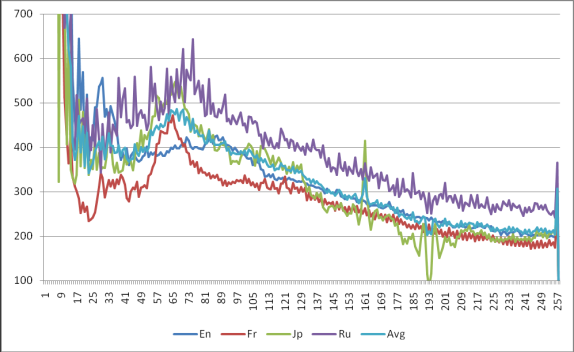
Рисунок 2 – Кепстры речи
На рисунке четко видно
различие между зависимостями, полученными для речи на различных языках. Поэтому
было решено включить кепстры языков в модель, и провести эксперименты с
точностью определения уже с использованием расширенного комплекта параметров.
Для вычисления подобия
была использована формула (5):
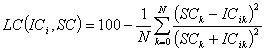 ,
где
(5)
,
где
(5)
ICi – кепстр i-той
модели языка;
SC –
кепстр сопоставляемой звукозаписи.
Результирующее подобие (L)
определялось как среднее значение подобий, вычисленных по спектру (LS)
и кепстру (LC) (6).
![]() (6)
(6)
В результате
эксперимента были получены точности определения языка, представленные в таблице
8.
Таблица 8 – Точности
детектирования с учетом кепстров
|
Язык |
Распознано как |
Ok |
Fail |
|||
|
EN |
FR |
JP |
RU |
|||
|
EN |
187 |
0 |
0 |
0 |
100 |
0 |
|
FR |
0 |
187 |
1 |
0 |
99,46809 |
0,531915 |
|
JP |
0 |
0 |
188 |
0 |
100 |
0 |
|
RU |
28 |
51 |
69 |
112 |
43,07692 |
56,92308 |
|
Result |
|
342,545 |
57,45499 |
|||
Видно, что для всех
языков, кроме русского, получено значительное увеличение точности определения.
Столь существенное падение точности определения для одного из языков делает
невозможным практическое применение модели в таком варианте.
Анализ получаемых
значений подобия показал, что необходимо ввести весовые коэффициенты на вклад
спектрального и кепстрального подобий в результирующее подобие (7):
![]() (7)
(7)
Значения коэффициентов as
= 0.0125 и ac = 4.500 определились путем перебора. Результаты
тестирования представлены в таблице 9.
Таблица 9 – Точности определения
с учетом кепстров и весов
|
Язык |
Распознано как |
Ok |
Fail |
|||
|
EN |
FR |
JP |
RU |
|||
|
EN |
183 |
4 |
0 |
0 |
97,86096 |
2,139037 |
|
FR |
3 |
185 |
0 |
0 |
98,40426 |
1,595745 |
|
JP |
0 |
0 |
188 |
0 |
100 |
0 |
|
RU |
6 |
0 |
0 |
254 |
97,69231 |
2,307692 |
|
Result |
|
393,9575 |
6,042474 |
|||
Из таблицы 9 видно, что
введение весовых коэффициентов позволило выправить ситуацию с точностью для
русского языка и получить приемлемые значения точности определения языка
звучащей речи.
Заключение
В результате
проведенного исследования был разработан модуль определения языка звучащей
речи, предназначенный для встраивания в систему оценки качества передачи речи AQuA.
Достигнутые показатели точности позволяют говорить о возможности использования
модуля в качестве самостоятельного решения.
На данный момент
практическому применению модуля мешает существенное ограничение, связанное с возможностью
работы только с сигналом, имеющим частоту дискретизации 16кГц. Работы по
устранению частотного ограничения ведутся.
Дальнейшее развитие
модуля связано с построением моделей для других языков и совершенствованием
модели музыки, повышением точности определения и введением в модели
дополнительных параметров.
Литература:
1. Покровский Н.Б.
Расчет и измерение разборчивости речи / М., Связьиздат, 1962
2. Valentin Smirnov, Mikhail Gusev Objective method of speech signal
quality estimation // Proceedings of the 11-th International Conference
"Speech and Computer" SPECOM'2006.-St.Petersburg, Anatolya
Publishers, 2006, pp. 242-244
3. ITU-T coded-speech database // Supplement 23 to ITU-T P-series
Recommendations / http://www.itu.int/rec/T-REC-P.Sup23-199802-I/en