Evgeny Faizrakhmanov
National Research Tomsk
Polytechnic University, Russian Federation
The
data integration in heterogeneous information systems
This article describes technologies used to create data integration systems. Data
integration system of well testing between two large production systems is used
as an example. Moreover, problems
encountered during the system
implementation are defined in details
as well as solution approaches.
The aim of data
integration technologies consists in an overcoming the numerous heterogeneity
manifestations peculiar for information systems. The systems have a different
functionality, use different data types, are based on different hardware
platforms, have different data management tools, different middleware, data
models, user interfaces, etc.
There are two
alternatives for data integration: the old one – syntactical, the new one –
semantical. The first one is based on the merge data formal resemblance, the
second one on the content similarity [1].
An example of data
integration in heterogeneous information systems is developed by TPU together
with LLC "Siberian Center of High Technologies" data integration
system of well test «Integra». The objective of this system is to transfer data
from one database to another of two different industrial AIS.
A major problem in the
process of integration between these systems is different platforms and design
concepts used in creating these databases. The first database is based on SQL
Server 2005 database, the second - on the basis of database Oracle 11g.
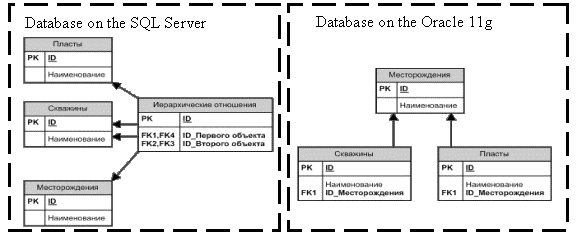
All data on the
drillholes’ studies tied to three main contents – ‘Deposits’, ‘Geologic beds’
and ‘Drillholes’. Figure 1 shows the relation between these contents in the
database ( Fig. 1). As can be seen from the figure, in the database on the SQL
Server there is additional table ‘Hierarchical relationships’, which describes
how the associated contents are interrelated. In the database based on Oracle
tables relate directly with one another. To perform a correct synchronization
it is necessary to compare these contents. For this purpose it is necessary to
solve the problems:
1.
Different relations between tables
2.
The difference in the data formats
 251659264
251659264
Fig. 1. The relation scheme
Due to the additional table in SQL Server we can be
sure that even if we change the database scheme, we still can get data on
drillholes and geological bed belonging to the same deposit. In the case of the
database based on Oracle, this architecture does not allow this. To get around
this, you need to check all the related table to table ‘deposit’, and if the
required table ‘Beds’ or ‘Drillholes’ is not found, we have to check all
related tables on the lower level . This is repeated until we reach the desired
table. Thus, you can associate the deposits with drillholes and geological
beds.
The second problem is solved significantly easier than
the first one. The developed system performs data conversion according to the
types specified in the documentation for the database data. It is decided to
use the field ‘Name’ for the data comparison. The data introduction for this
field is based on the general rule for both information systems, but with
different registers. A data transfer system brings them into a single register,
and if the data matches it compares their unique identifiers. Otherwise, it
reports about the data that are not comparable and the operator is able to
specify comparable object individually.
Thus, the data integration system was developed that
allows integrating data between heterogeneous information systems. Moreover,
the issue of automatic schema validation of matched data is solved. Due to a
technical impossibility of semantic relations organization for the data scheme in
the database based on Oracle 11g we used syntactic approach, which leads to
additional difficulties in the implementation of the system.
The list of references:
1.
L. S. Chernyak. Data integration:
syntax and semantics // Open systems-2010. -URL: http://www.osp.ru/os/2010/06/11170978/
2. How Data Integration
Works. – URL: http://computer.howstuffworks.com/data-integration.htm
3. Data integration – URL: http://en.wikipedia.org/wiki/Data_integration
т различную производительность. Системы строятся на разных
аппаратных платформах, имеют разные средства управления данными, разное ПО
промежуточного слоя, модели данных, пользовательские интерфейсы и м