Файзрахманов
Е.Г.
Томский
политехнический университет, Россия
Data Mining с использованием средств MS SQL Server на примере анализа федеральной статистики
преступлений
В наши дни человечество накопило огромное
количество информации. Эти данные можно использовать для выявления новых
зависимостей и поиска новой информации. В данной статье будет описан процесс
анализа федеральных статистических данных по преступности в Российской
Федерации и поиск новой информации (Data Mining)
с помощью средств Microsoft SQL
Server. Такой анализ
статистических данных предоставит общую картину по преступности в стране и даст
возможность спрогнозировать дальнейшие тенденции развития преступности по
отдельным регионам.
Для лучшего понимания кратко опишем основные
положения и принципы Data mining.
Data mining – это процесс выявления скрытых фактов и взаимосвязей в больших
массивах данных. Он задействует четкое понимание бизнеса и мощные аналитические
технологии для быстрого и тщательного изучения больших массивов данных с целью
извлечения ценной информации – бизнес аналитики, необходимой для принятия
эффективных решений.
Для проведения
анализа статистических данных было спроектировано и реализовано небольшое
тестовое хранилище данных. После разработки хранилища данных необходимо создать проект
в среде Microsoft SQL Server
Business Intelligence Development Studio. Далее необходимо создать один или
несколько источников данных. На данном этапе все интуитивно понятно и не
требует большего разъяснения. После создания источника данных в одноименном
пункте появится соответствующая запись.
Следующим шагом необходимо создать
представления источника данных. Представление
источника данных - это логическое отображение одного или нескольких источников
данных. Проще говоря, это коллекция объектов базы данных (таблиц, представлений
и хранимых процедур), которые логически сгруппированы и могут быть использованы
во всем проекте. Представления источника данных очень похожи на реляционные
представления SQL Server. Его создание идентично созданию источника
данных и не требует подробного описания.
А
далее начинается самое интересное – создание структуры интеллектуального
анализа данных. Структуру можно создать
на основе хранилища данных или на основе куба. Так как OLAP кубы не
рассматривались в данной статье, структура будет реализована на основе
существующего хранилища данных. Вторым шагом будет выбор метода
интеллектуального анализа данных.
Изначально в SQL Server Business Intelligence имеется 9 разнообразных алгоритмов для обработки
данных. Этот набор можно расширить, добавив свой собственный алгоритм. В нашем
случае подходят «алгоритм нейронной сети» и «упрощенный алгоритм Байеса». Потом
выбираем созданное ранее представление источника данных и таблицы с необходимой
нам информацией. При появлении таблицы, показанной на рисунке 1, необходимо
выбрать ключевой атрибут (используем уникальный идентификатор), входные данные
для обучения и проверки, а также прогнозируемый атрибут (интересующий нас). И
последним шагом создания структуры интеллектуального анализа данных является
создание проверочного набора. На этом шаге задается процентное соотношение
данных на обучение и проверку.
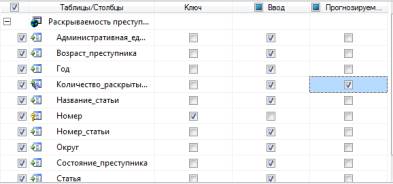
Рисунок 1 – Определение обучающих данных
После выполнения вышеописанной работы
имеется возможность произвести анализ статистических данных. При выполнении
анализе можно увидеть зависимость количество раскрытых преступлений в
зависимости от разных атрибутов, что показано на рисунке 2.
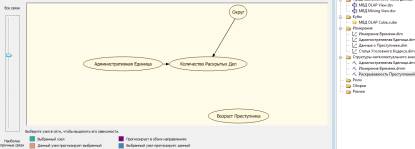
Рисунок 2 – Визуализация модели анализа
Хотелось бы отметить, что главной целью статьи
является описание процесса создания Data Mining
структуры, а не проведение самого анализа. Однако можно заметить, что при
анализе данных было выявлено снижение преступности во всех регионах с каждым
последующим годом, начиная с 2008 года.
1.
Новые возможности SQL Server 2005
Integration Services. – URL: http://citforum.ru/database/mssql/new_int_serv/part2.shtml
2. Структуры
интеллектуального анализа данных. –URL: http://msdn.microsoft.com/ru-ru/library/ms174757.aspx
3.
Jamie MacLennan, ZhaoHui Tang,
Bogdan Crivat – Data Minning with Microsoft SQL Server 2008. – Wiley
Publishing, Inc. – 2009. -700 с