Математика / 4. Прикладная математика
Колесниченко Е. О.
Одесский
национальный политехнический университет, Украина.
Масштабно-пространственна идентификация изображений при распознавании
образов.
I. ВВЕДЕНИЕ
Системы технического зрения имеют дело с
проблемой получения значимой и полезной информации о мире, используя его
световое отражение. Что подразумевается под термином, «значимая и полезная
информация», конечно, это строго зависит от цели анализа, то есть от основной
цели, почему мы хотим использовать визуальную информацию и обработать ее
автоматическими методами.
Типичными решаемыми задачами являются
распознавание объектов, манипуляция объектами, и визуальная навигация. Другие
общие применения методик машинного зрения могут быть найдены в обработке изображения,
можно упомянуть такие области как повышение качества изображения, визуализацию
и анализ медицинских данных, так же как индустриальный осмотр, дистанционное
зондирование, автоматизированную картографию, сжатие данных, дизайн визуальных
средств, и т.д.
Предельно важная тема в автоматизации
формулирования логических выводов – это понятие внутреннего представления.
Только по средствам представления информация может быть зафиксирована и сделана
доступной для решающих процессов. Цель представления состоит в том, чтобы
сделать определенные аспекты информационного наполнения явными, то есть,
немедленно доступными без любой потребности в дополнительной обработке[1].
Как сделать явными важные аспекты
изображения, которые будут полезны для более поздних процессов обработки?
Очевидная проблема касается того, какая информация должна быть извлечена и
какие вычисления должны быть выполнены на этих уровнях[2].
На
сегодня значительная часть практических задач характеризуется высоким уровнем помех,
а методы представления и идентификации или не достаточно помехоустойчивыми или
недостаточно достоверные. Поэтому задача разработки нового
метода идентификации, реализуемого программными средствами, является актуальной.
Формально, линейное пространственное масштабом представление
непрерывного сигнала создано следующим образом.
Пусть ![]() представляет любой
заданный сигнал. Тогда пространственно масштабное представление
представляет любой
заданный сигнал. Тогда пространственно масштабное представление ![]() определенно для
определенно для ![]() и
и
![]() (1)
(1)
где ![]() параметр масштаба, а
параметр масштаба, а ![]() Гауссово ядро, для
произвольной размерности это будет выглядеть как:
Гауссово ядро, для
произвольной размерности это будет выглядеть как:
![]()
![]() (2)
(2)
Пространственно-масштабное семейство ![]() может быть также
определенно как решение диффузионного уравнения:
может быть также
определенно как решение диффузионного уравнения:
![]() (2)
(2)
В пространственно-масштабном представления мы можем на любом уровне
масштаба, определяют пространственно-масштабные производные [3]
![]() (3)
(3)
где ![]() и
и ![]() составляют
мульти-индексное обозначение для производного оператора
составляют
мульти-индексное обозначение для производного оператора ![]() . Такие Гауссовы производные операторы обеспечивают
компактный способ характеризовать местную структуру изображения вокруг
определенного изображения в любом масштабе.
. Такие Гауссовы производные операторы обеспечивают
компактный способ характеризовать местную структуру изображения вокруг
определенного изображения в любом масштабе.
Определенно, вывод от пространственных
масштабом производных может быть объединен в многомасштабные дифференциальные
инварианты, которые будут служить признаками для идентификации [4].
Используем
данный подход к декомпозиции модели данных, которые позволяют реализовать
общую модель как совокупность иерархически взаимоувязанных более простых
моделей различного уровня иерархии (рисунок 1). Такая структура позволит
повысить точность моделирования, упростить и повысить достоверность этапа
классификации [3].
Изображение можно представить в виде
совокупности изображений различного уровня иерархии:
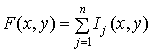 , (4)
, (4)
где j – число уровней
иерархии на изображении;
![]() – изображение на j-м уровне иерархии (j=1,…,n).
– изображение на j-м уровне иерархии (j=1,…,n).
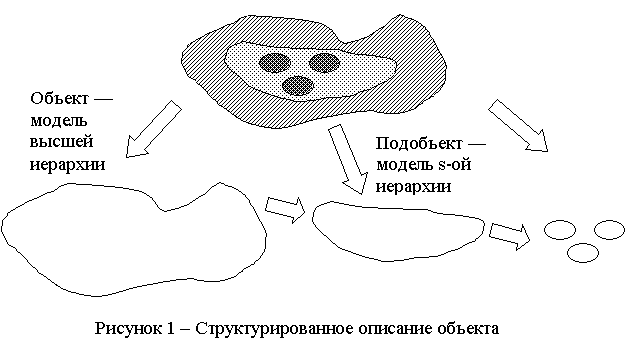

В общем случае изображение ![]() на каждом уровне есть совокупность изображений
отдельных объектов и фона [4]:
на каждом уровне есть совокупность изображений
отдельных объектов и фона [4]:
![]() , (5)
, (5)
где ![]() – число объектов (подобъектов) на изображении;
– число объектов (подобъектов) на изображении;
![]() – изображение i-го
объекта или его видимой части (i=1,…,k)
на j – уровне иерархии;
– изображение i-го
объекта или его видимой части (i=1,…,k)
на j – уровне иерархии;
![]() – изображение фона на j – уровне иерархии.
– изображение фона на j – уровне иерархии.
При этом
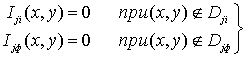 , (6)
, (6)
где ![]() – область i –
объекта на j – уровне иерархии, входящая в дискретное поле зрения
– область i –
объекта на j – уровне иерархии, входящая в дискретное поле зрения ![]() ;
;
![]() – область фона на j –
уровне иерархии;
– область фона на j –
уровне иерархии;
![]() .
. ![]() при
при ![]() .
.
![]() ,
,
где j, g – уровни иерархии.
В такой постановке задача моделирования
процессов обработки может быть разбита на такие этапы:
1.
Представление
изображения в виде структуры изображений
объект – подобъект (ы) – … – подобъект (ы) в виде (4).
2.
Выделение объектов,
соответствующих одному уровню иерархии (3.2), так чтобы выполнялось условие (6).
3.
Распознавание объектов и
подобъектов.
II. ОПИСАНИЕ ОБЪЕКТОВ
В результате проведения контурного анализа
изображений на базе предложенной выше сигнально-семантической модели получено
пирамидальное представление геометрических форм объекта и его деталей: набор
контурных препаратов. Такое представление
(или его отдельные составляющие) служит исходным для расчета
геометрических идентификационных признаков. Для получения геометрических идентификационных
данных и последующей классификации целесообразно представить контурные
препараты в виде последовательности векторов признаков разного уровня. В соответствии с предлагаемой концепцией иерархических
моделей описание объекта может быть представлено в виде (7)
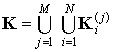 (7)
(7)
Здесь M –число масштабов преобразования; N – количество объектов и подобъектов.
На
множествах К определено отношение
принадлежности, при котором один или несколько подобъектов располагается внутри
другого объекта или подобъекта.
Известно, что наибольшей информативностью
среди точек контура обладают точки наибольшей кривизны (характерные точки)
Описание
объекта на множестве характерных точек контура может быть представлено в виде
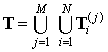 (8)
(8)
Здесь
M
–число масштабов преобразования; N – количество объектов и подобъектов.
В
работе предлагается следующий метод выделения характерных точек:
1.
Выбираем первую
точку контура, которая становится началом отрезка;
2.
Начинаем цикл,
условием остановки которого является нахождение характерной точки;
3.
Смещаемся по
прослеженному контуру на шаг равный интервалу контурной обработки и выбираем
вторую точку, которая становится концом отрезка;
4.
Находим
координаты точек делящих отрезок на равные части согласно следующих формул:
![]() ;
; ![]() ;
; ![]() ,
, ![]() (9)
(9)
Результат
(9)
округляем;
5.
От всех
полученных точек находим расстояние по норме вектора до соответствующих точек
прослеженного контура и сравниваем его с ![]() , введенным пользователем;
, введенным пользователем;
6.
Если расстояние
не превышает ![]() , то
, то ![]() и мы возвращаемся к шагу №3. Если превышает – тогда
соответствующая точка контура претендует на занесение в массив характерных
точек;
и мы возвращаемся к шагу №3. Если превышает – тогда
соответствующая точка контура претендует на занесение в массив характерных
точек;
7.
Массив
характерных точек проверяется на наличие в нем точки с такими же координатами;
8.
Проверяется не
находятся ли претендующая точка и предыдущая характерная точка на прямых
параллельных осям координат во избежании бесконечного роста шага итерации;
9.
Если все
условия выполнены точка заносится в массив характерных точек и цикл начатый на
шаге №2 завершается, найденная точка становится новым началом отсчета и мы
возвращаемся к шагу №1;
10.
Процесс
продолжается пока не будут перебраны все точки прослеженного контура.
Для
получения первичного вектора контурных признаков были проанализированы
следующие методы контурной идентификации:
– геометрических моментов-признаков [5];
– лучевых сумм [5];
– анализа Фурье-коэффициентов [5].
В
результате анализа установлено, что все эти методы могут быть реализованы в
рамках иерархического подхода. Сравнительный анализ этих методов и особенности
применения для вычисления идентификационных данных в рамках
адаптивно-критериального подхода показал, что наиболее полно соответствует
требованиям иерархической модели идентификации структурно-статистический метод
на базе геометрических моментов признаков (ГМП) [5]. ГМП в исходной евклидовой
системе координат имеют вид:
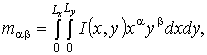 (10)
(10)
где
I – обрабатываемое изображение; ![]() – геометрические
размеры изображения;
– геометрические
размеры изображения; ![]() – порядок момента.
– порядок момента.
При
распознавании методом ГМП обычно используют не сами моменты-признаки, а
рассчитанные на их базе инварианты. Инвариантность к повороту и сдвигу легче
реализуется в полярной системе координат. Для того, чтобы обеспечить
инвариантность к масштабу необходимо произвести нормировку радиус-векторов.
Высокой помехоустойчивостью обладает расчетная площадь фигуры S. Поэтому
для нормировки используется коэффициент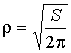 .
.
Выражение
для вычисления моментов при этом принимает вид:
![]() (11)
(11)
где ![]() - среднее геометрическое
радиус-векторов,
- среднее геометрическое
радиус-векторов, ![]() - разность фаз между
i - ой и (i+1) - ой ХТ.
- разность фаз между
i - ой и (i+1) - ой ХТ.
На базе полученных простых геометрических
моделей К1, К2, КN различного уровня иерархии рассчитываются векторы
признаков ![]() , соответствующие разному разрешению. Комбинирование моделей
позволяет проводить как классификацию на основе вектора признаков
, соответствующие разному разрешению. Комбинирование моделей
позволяет проводить как классификацию на основе вектора признаков ![]() , полученного в
зависимости от соотношения между признаками разного уровня иерархии, так и
независимую классификацию по вектору признаков на каждом уровне иерархии и
принятие на ее основе окончательного решения по классификации объекта.
, полученного в
зависимости от соотношения между признаками разного уровня иерархии, так и
независимую классификацию по вектору признаков на каждом уровне иерархии и
принятие на ее основе окончательного решения по классификации объекта.
Таким образом в данной работе предлагается
система следующего вида (рисунок 2):
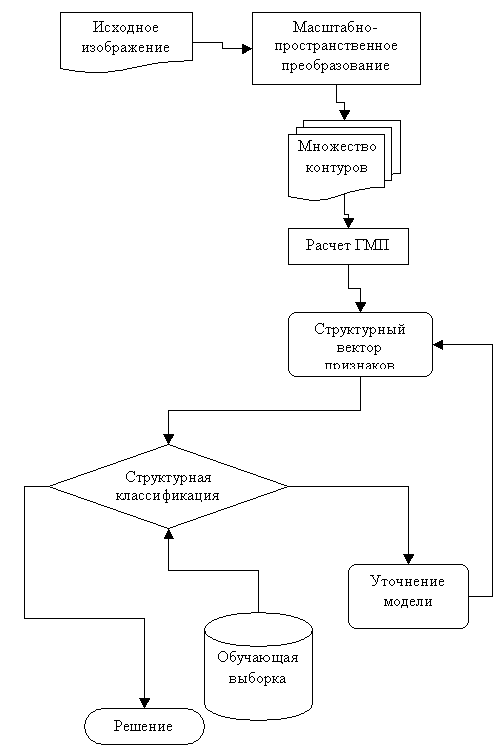
Рисунок 2 – Модель системы
III. ОЦЕНКА
СИСТЕММЫ
Мерой
качества процедуры идентификации выбрано нормированное внутримножественное
расстояние вектора признаков ![]() , полученного в результате идентификации t-ым из оцениваемых методов и
«идеальным» методом (при t = 0) [6]
, полученного в результате идентификации t-ым из оцениваемых методов и
«идеальным» методом (при t = 0) [6]
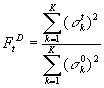 (12)
(12)
где ![]() несмещенная дисперсия (L — количество элементов класса).
несмещенная дисперсия (L — количество элементов класса).
При оценке
эффективности идентификации использовалась геометрическая мера информации,
определяемая отношением числа пикселей в прослеженном контуре т к размерности вектора
признаков l [6].
![]() (13)
(13)
Размерность
вектора признаков выбиралась исходя из требований семантической достаточности
[6].
При идентификации
используется процедура минимизации и ортогонализации признакового пространства.
III. ПРАКТИЧЕСКОЕ ИСПОЛЬЗОВАНИЕ ПРЕДЛОЖЕННОЙ СИСТЕММЫ
Методы масштабно-пространственной
идентификации и метод постепенной структурной классификации были применены к
задаче распознавания нумизматских монет. Монеты
идентифицировались и классифицировались как по полному так и по неполному
набору контуров При классификации использовать классификацию с обучением.
Монеты
как известно характеризуются своей формой, а также рельефным рисунком,
вытесненным на их поверхностях, которая в большинстве случаев имеет одну и ту
же расцветку, что позволяет характеризовать изображение монеты только по
контурному препарату ее формы и рисунку.
Так как монеты достаются из разного рода сред, в которых они подвержены
влиянию разнообразных агрессивных влияний: эрозии, давления, трения, и так
далее. Из-за этого первоначальная форма монеты может будет частично искривлена
или даже потеряна, потому при экспериментальных
исследованиях также учитывались искривление в форме монеты или контуров ее
рисунка. Для
тестов использовались следующие монеты (рисунки 3-7):

Рисунок 3 – Корейская монета
времен династии Ли (Класс №2)

Рисунок 4 – Японская монета
1570-1584 годов (Класс №3)


Рисунок 5 – Китайская монета
1573-1619 лет и монета счастья (Класс №1,6)


Рисунок
6 – Монеты восточных Карибов с 1981(Класс 5,7)

Рисунок 7 – Монета Средней Азии с
отверстием (Класс №4)
В результате экспериментальных исследований были получены графики
зависимости качества и эффективности идентификации
в зависимости от класса объекта и размерности признакового пространства (рисунки 8 – 9).
При оценке этих показателей использовались тестовые полутоновые изображения
монет полученные методом масштабно-пространственной сегментации и контуры получены искусственной сегментацией и используемые
как идеальные образцы монет. Результаты исследований метода масштабово-просторової|
идентификации приведены в таблицах 1-2:
Таблица 1 Характеристики работы метода масштабно-пространственной
идентификации по полной последовательности контуров на тестових изображениях
|
Номер
класса № |
Количество
контуров |
Количество
характерных точек |
Длина
вектора признаков |
Качество
идентификации |
Эффективность
идентификации |
|
1 |
3 |
125 |
3 |
0.7343 |
41.6667 |
|
2 |
6 |
213 |
6 |
0.6914 |
35.5000 |
|
3 |
3 |
117 |
3 |
0.6782 |
39.0000 |
|
4 |
2 |
89 |
2 |
0.6723 |
44.5000 |
|
5 |
2 |
62 |
2 |
0.7131 |
31.0000 |
|
6 |
2 |
53 |
2 |
0.7098 |
26.5000 |
|
7 |
3 |
130 |
3 |
0.7511 |
43.3333 |
|
1 |
3 |
125 |
5 |
0.7612 |
25.0000 |
|
2 |
6 |
213 |
10 |
0.7103 |
21.3000 |
|
3 |
3 |
117 |
5 |
0.6934 |
23.4000 |
|
4 |
2 |
89 |
4 |
0.6921 |
22.2500 |
|
5 |
2 |
62 |
3 |
0.7588 |
20.6667 |
|
6 |
2 |
53 |
3 |
0.7308 |
17.6667 |
|
7 |
3 |
130 |
5 |
0.7765 |
26.0000 |
|
1 |
3 |
125 |
7 |
0.8513 |
17.8571 |
|
2 |
6 |
213 |
14 |
0.8473 |
15.2143 |
|
3 |
3 |
117 |
7 |
0.8285 |
16.7143 |
|
4 |
2 |
89 |
5 |
0.8367 |
17.8000 |
|
5 |
2 |
62 |
5 |
0.8638 |
12.4000 |
|
6 |
2 |
53 |
5 |
0.8553 |
10.6000 |
|
7 |
3 |
130 |
7 |
0.8714 |
18.5714 |
|
1 |
3 |
125 |
8 |
0.9375 |
15.6250 |
|
2 |
6 |
213 |
18 |
0.9343 |
11.8333 |
|
3 |
3 |
117 |
8 |
0.9183 |
14.6250 |
|
4 |
2 |
89 |
6 |
0.9437 |
14.8333 |
|
5 |
2 |
62 |
6 |
0.9455 |
10.3333 |
|
6 |
2 |
53 |
6 |
0.9377 |
8.8333 |
|
7 |
3 |
130 |
8 |
0.9534 |
16.2500 |
Таблица 8.2 Характеристики работы метода масштабно-пространственной идентификации по частичному набору контуров
на тестовых изображениях
|
Номер
класса № |
Количество
контуров |
Количество
характерных точек |
Длина
вектора признаков |
Качество
идентификации |
Эффективность
идентификации |
|
1 |
1 |
125 |
1 |
0.4523 |
125.0000 |
|
2 |
3 |
213 |
2 |
0.4155 |
106.5000 |
|
3 |
1 |
117 |
1 |
0.4122 |
117.0000 |
|
4 |
1 |
89 |
1 |
0.4135 |
89.0000 |
|
5 |
1 |
62 |
1 |
0.4445 |
62.0000 |
|
6 |
1 |
53 |
1 |
0.4101 |
53.0000 |
|
7 |
1 |
130 |
1 |
0.4571 |
130.0000 |
|
1 |
1 |
125 |
2 |
0.5642 |
62.5000 |
|
2 |
3 |
213 |
4 |
0.5341 |
53.2500 |
|
3 |
1 |
117 |
2 |
0.5362 |
58.5000 |
|
4 |
1 |
89 |
2 |
0.5391 |
44.5000 |
|
5 |
1 |
62 |
2 |
0.5352 |
31.0000 |
|
6 |
1 |
53 |
2 |
0.5335 |
26.5000 |
|
7 |
1 |
130 |
2 |
0.5722 |
65.0000 |
|
1 |
1 |
125 |
3 |
0.6511 |
41.6667 |
|
2 |
3 |
213 |
5 |
0.6343 |
42.6000 |
|
3 |
1 |
117 |
3 |
0.6422 |
39.0000 |
|
4 |
1 |
89 |
3 |
0.6466 |
29.6667 |
|
5 |
1 |
62 |
3 |
0.6501 |
20.6667 |
|
6 |
1 |
53 |
3 |
0.6331 |
17.6667 |
|
7 |
1 |
130 |
3 |
0.6820 |
43.3333 |
|
1 |
1 |
125 |
4 |
0.7156 |
31.2500 |
|
2 |
3 |
213 |
6 |
0.6914 |
35.5000 |
|
3 |
1 |
117 |
4 |
0.6763 |
29.2500 |
|
4 |
1 |
89 |
4 |
0.6921 |
22.2500 |
|
5 |
1 |
62 |
4 |
0.7304 |
15.5000 |
|
6 |
1 |
53 |
4 |
0.7267 |
13.2500 |
|
7 |
1 |
130 |
4 |
0.7565 |
32.5000 |
Проанализировав полученные
результаты следует заметить, что метод масштабно-пространственной идентификации
по полному набору контуров показал качество идентификации в 1,7-1,3 разы выше,
чем в метод идентификации по неполному набору контуров. Но этот показатель
также изменяется в зависимости от длины вектора признаков и класса объекта идентификации.
Наибольший выигрыш в качестве идентификации у метода по полной
последовательности контуров наблюдался для Класса №2. Это следует из того, что
для этого класса характерная наибольшая общая последовательность контуров,
которая при применении полного метода дает наиболее точное описание объекта
даже при наличии определенных искривлений в форме контуров, тогда как метод
постепенной идентификации по неполной последовательности контуров использует
только три первых контура, которые необходимы для идентификации в пределах
представленного набора классов, но при наличии искривлений это может привести к
неточной идентификации и ошибке. Для других классов выигрыш в качестве
составляет около 1,3, так как они содержат меньше контуров, а следовательно оба
метода идентификации используют приблизительно одинаковое количество контуров.
На качество идентификации также
влияет размерность признакового пространства. Если при длине ГМП в один признак
на контур, максимальная разница в качестве между методами достигает 1,7, то при
длине в четыре признака на контур она сокращается до 1,3.
Результат сравнения эффективности
идентификации для двух методов противоположен. Метод идентификации по неполному
набору контуров показал эффективность в 1,5-3 разы выше, чем у метода
идентификации по полному набору контуров. Особенно это заметно для Классов №1,
2, 3 и 7, для которых происходит значительное сокращение длины признакового
пространства за счет использования только тех контуров, которые наиболее полно
определяют объект среди других, и составляет 3-2,5 разы. Для других классов
этот показатель составляет 2-1,5 разы. Размерность признакового пространства
также влияет и на эффективность идентификации, но в данном случае это влияние
зависит от класса объекта идентификации. При длине ГМП в один признак на контур
максимальная разница в качестве между методами достигает 3 для Класса№1 и
остается неизменной для длины ГМП в четыре признака на контур, для других
классов наблюдается сокращение разницы в эффективности на 25-33%.
Из выше перечисленных показателей
можно сделать вывод, что метод идентификации по неполному набору контуров имеет
лучшее отношение эффективности и качества чем метод идентификации по полному
набору контуров, но не лишен недостатков. Основным недостатком является низкое
качество идентификации при искривлении ключевых контуров объекта, но этот
недостаток можно компенсировать за счет увеличения размерности признакового пространства.
Метод идентификации по полному набору контуров более стойкий к таким ошибкам,
потому что погрешности искривления ключевых контуров объекта в нем компенсируются
информацией, которую в себе несут не ключевые контуры. Но последний также имеет
свой недостаток, которым бесспорно является низкая эффективность идентификации
особенно для объектов, которые содержат большое количество контуров.
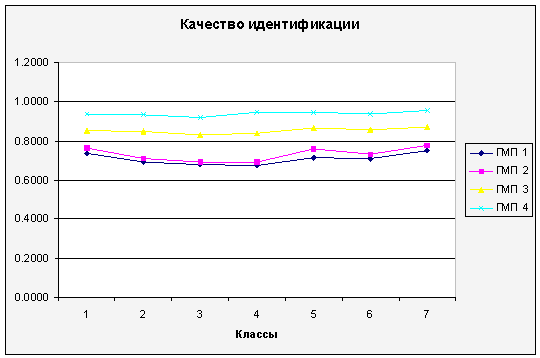
Рисунок 8 – Качество
идентификации при использовании полного набора контуров
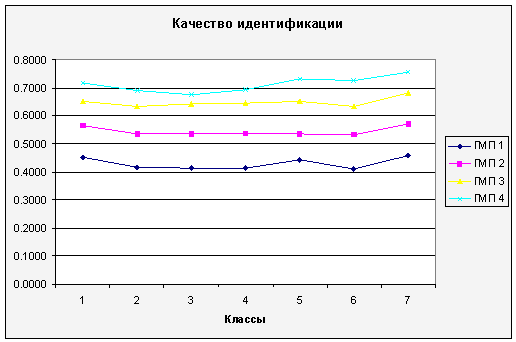
Рисунок 9 – Качество
идентификации при использовании неполного набора контуров
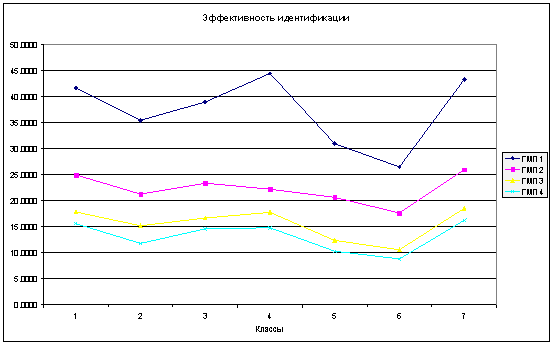
Рисунок 10 – Эффективность
идентификации при использовании полного набора контуров
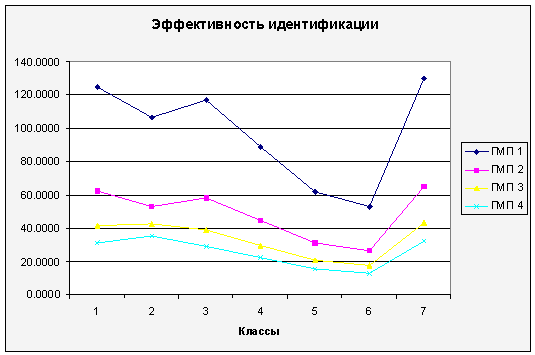
Рисунок 11 – Эффективность
идентификации при использовании не полного набора контуров
IV. ВЫВОДЫ
Итак при сильном искривлении
контуров объекта лучше применять метод масштабно-пространственной идентификации
по полному набору контуров с длиной ГМО в 2-3 признака, во всех других случаях
метод идентификации по не полному набору контуров и длине ГМО в 4 признака дает
оптимальные показатели эффективности и качества идентификации для всех классов
монет.
ЛИТЕРАТУРА
1.
Florack M. J., Romeny B. M., Koenderink J. J., General intensity
transformations and diferential invariants, //J. of Mathematical Imaging and
Vision, 1994. — N. 21. — P. 98-118.
2.
Witkin A. P., Scale-space filtering, //in Proc. 8th Int. Joint Conf.
Art. Intell. — Karlsruhe:IEEE Computer Society, 1983 — P. 201-216.
3.
Lindeberg T., Discrete scale space theory and the scale space primal
sketch. PhD thesis, Dept. of Numerical Analysis and Computing Science, //Royal Institute of
Technology, Stockholm, May 1991. — N. 32. — P. 312-322.
4.
Tong C. S., Zhang Y., and Zheng N., Variational-based image segmentation
and its multiscale realizations, //International Conference on Inverse Problems, January
9-12 2002. — N. 16. — P. 224-245.
5.
Крылов В. Н., Максимов
М. В. Вторичное преобразование сигналов изображений /Одес. гос. политехн. ун-т.
— Одесса: Астропринт, 1997. — 176 с.: ил. — Яз. рус.
6.
Гонсалес Р., Вудс Р.
Цифровая обработка изображений. — М.: Техносфера, 2005. — 1072 с.